本文将介绍分布式任务调度系统:xxl-job,开源地址如下:
码云地址:https://gitee.com/xuxueli0323/xxl-job
文档地址:https://www.xuxueli.com/xxl-job/
# (一)定时任务的场景 {#一-定时任务的场景}
在开发中,定时任务是一种十分常见的应用场景,比如每天晚上12点同步数据,又或者每隔一个小时拉取一次数据。
在Java中,实现定时任务的方式有很多,最简单的在线程中通过Thread.sleep 睡眠线程,或者采用SpringBoot中的@Schedule注解 ,又或者采用定时线程池ScheduledExecutorService来实现。
# (二)上面的定时任务会有什么问题? {#二-上面的定时任务会有什么问题}
在单机环境下,上面的这种定时任务实现方式问题主要有一个,无法进行管理,没有容错机制。
但是在集群环境下,如果不对代码作控制,就会导致集群的每一台机器都会执行一次定时任务。
常见的解决方式,我通过配置文件进行控制,只让定时任务在某一台机器上执行,如果项目比较小,就几台机器组成的集群环境,这样的方式确实可以,只不过在任务的管理上需要想办法解决。
如果是一个很庞大的分布式微服务系统,可能会有成千上万个定时任务,那上面的方法就不合理了。因此许多互联网公司会采用分布式任务调度系统 ,主要为了实现高可用、容错管理、负载均衡、管理机制等功能,我目前所在公司使用的是xxl-job作为分布式任务调度平台。
# (三)xxl-job的使用 {#三-xxl-job的使用}
xxl-job的一大优势就是使用简单,学习成本低,xxl-job作者已经给出了很详细的使用说明,下面我们就通过源码直接来跑一下。
# 3.1 初始化调度数据库 {#_3-1-初始化调度数据库}
git上clone的项目中保存了初始化sql脚本,位置在:
/xxl-job/doc/db/tables_xxl_job.sql
执行完毕后会在数据库中新建库以及表结构。
# 3.2 修改配置 {#_3-2-修改配置}
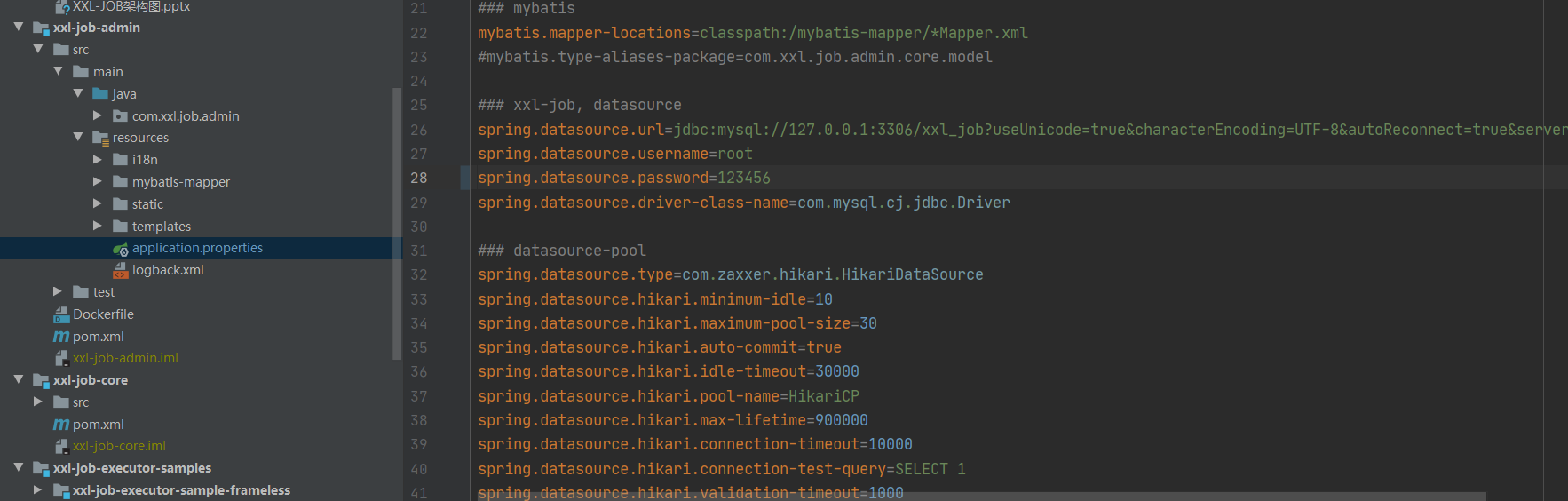
修改主配置文件:
/xxl-job/xxl-job-admin/src/main/resources/application.properties
主要修改jdbc的连接信息,以及报警邮件,xxl-job支持通过邮件报警的方式。
# 3.3 运行项目 {#_3-3-运行项目}
直接运行xxl-job-admin中的XxlJobAdminApplication,正常启动后访问http://localhost:8080/xxl-job-admin,输入用户名密码:admin/123456,然后就能看到任务调度中心页面了
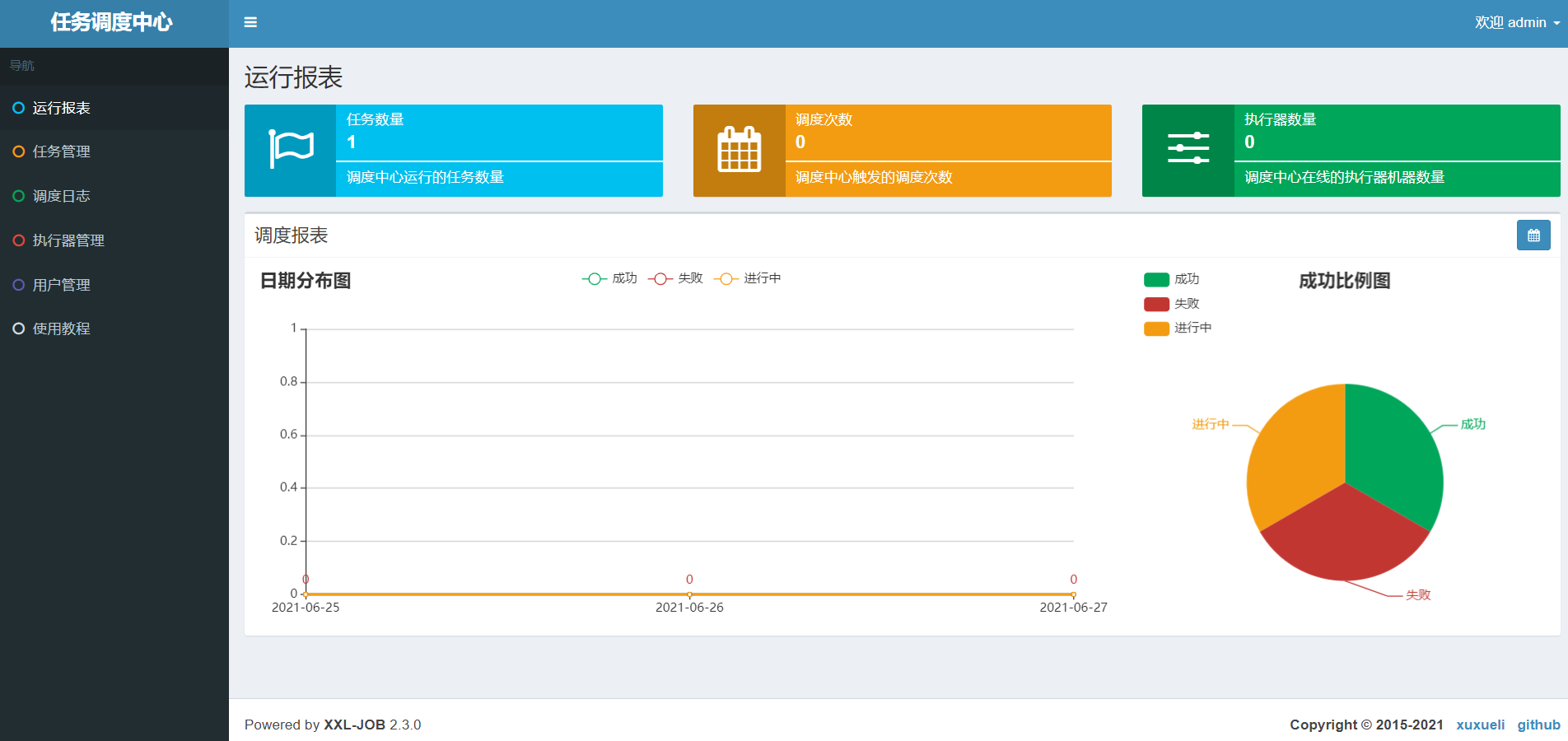
到这里为止,xxl-job的管理平台已经搭建完成,接下来展示客户端使用xxl-job的案例。xxl-job支持多种执行方式,我这里演示Java Bean的使用。其余的可看官方提供的技术文档。
# 3.4 配置执行器 {#_3-4-配置执行器}
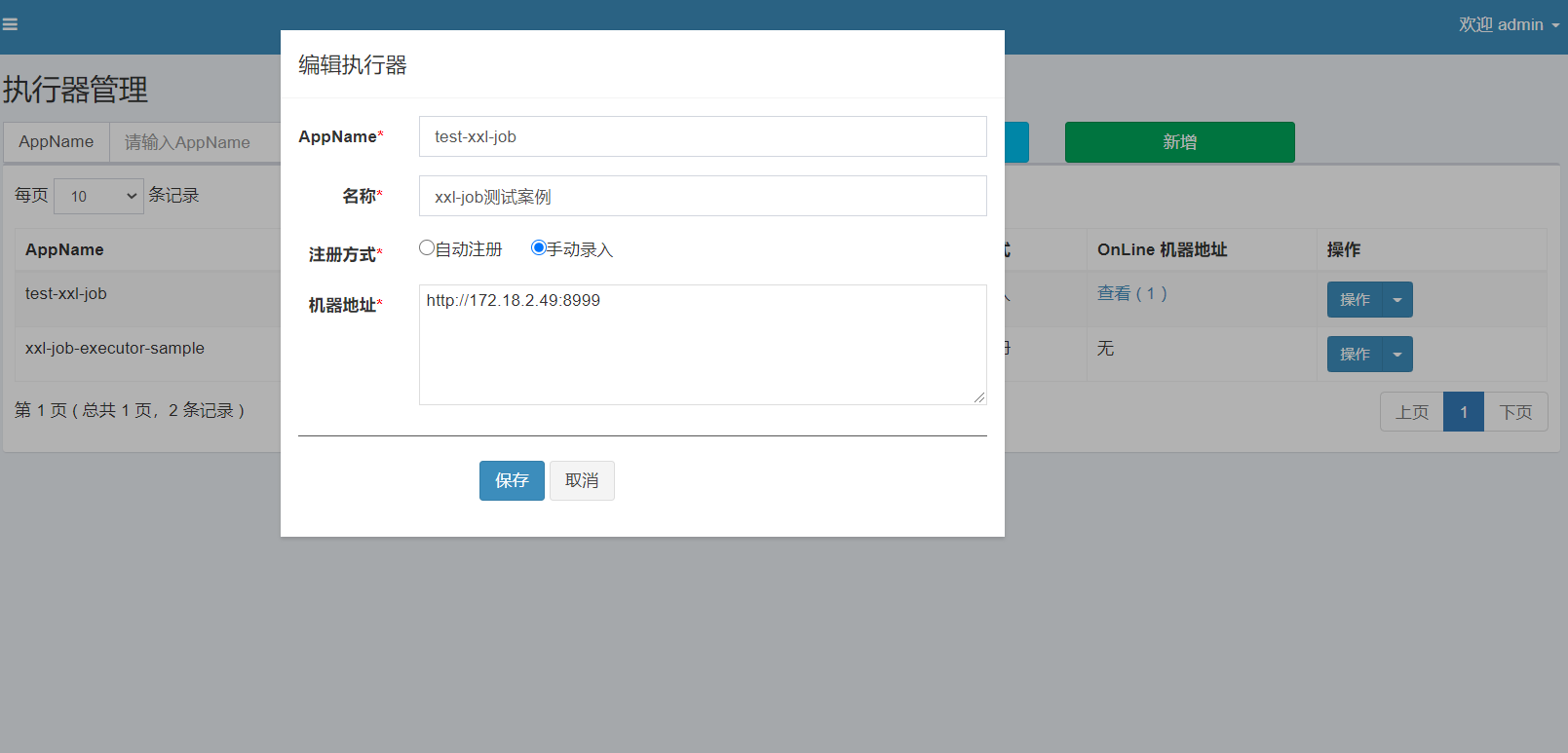
执行器管理页面点击新增执行器:
AppName: 是每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
注册方式:调度中心获取执行器地址的方式;
自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
我这里选择手动录入,并且自己输入执行器的地址,ip是本机ip,端口选择一个未使用过的端口。
# 3.5 编写客户端代码 {#_3-5-编写客户端代码}
接下来编写客户端的代码,在xxl开源项目中,已经有springboot的demo,我们自己写一个。
第一步引入依赖:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${project.parent.version}</version>
</dependency>
这里的version填写最新的稳定版本,因为我在xxljob的开源项目中新建了一个module进行测试,因此直接用父项目版本了。
第二步编写配置文件:
server.port=8081
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
xxl.job.accessToken=
xxl.job.executor.appname=test-xxl-job
xxl.job.executor.address=
xxl.job.executor.ip=172.18.2.49
xxl.job.executor.port=8999
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
xxl.job.executor.logretentiondays=30
几个注意点:
xxl.job.admin.addresses是管理平台的地址
xxl.job.executor.appname是我们上面的执行器appname
xxl.job.executor.address不填的话就是xxl.job.executor.ip:xxl.job.executor.port
其他的就按照执行器配置的填。
第三步编写配置类
@Configuration
public class XxlConfig {
private Logger logger = LoggerFactory.getLogger(XxlConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
第四步编写demo代码:
@Component
public class DemoJobHandler {
@XxlJob("demoJobHandler")
public void demoJobHandler(){
System.out.println("执行定时任务");
XxlJobHelper.log("执行定时任务");
}
}
通过@XxlJob("demoJobHandler"),指定任务的名称。
# 3.5 配置任务 {#_3-5-配置任务}
代码写好了,接下来配置具体的任务了,进管理平台的任务管理,在test执行器下新建一个任务,简单如下配置:
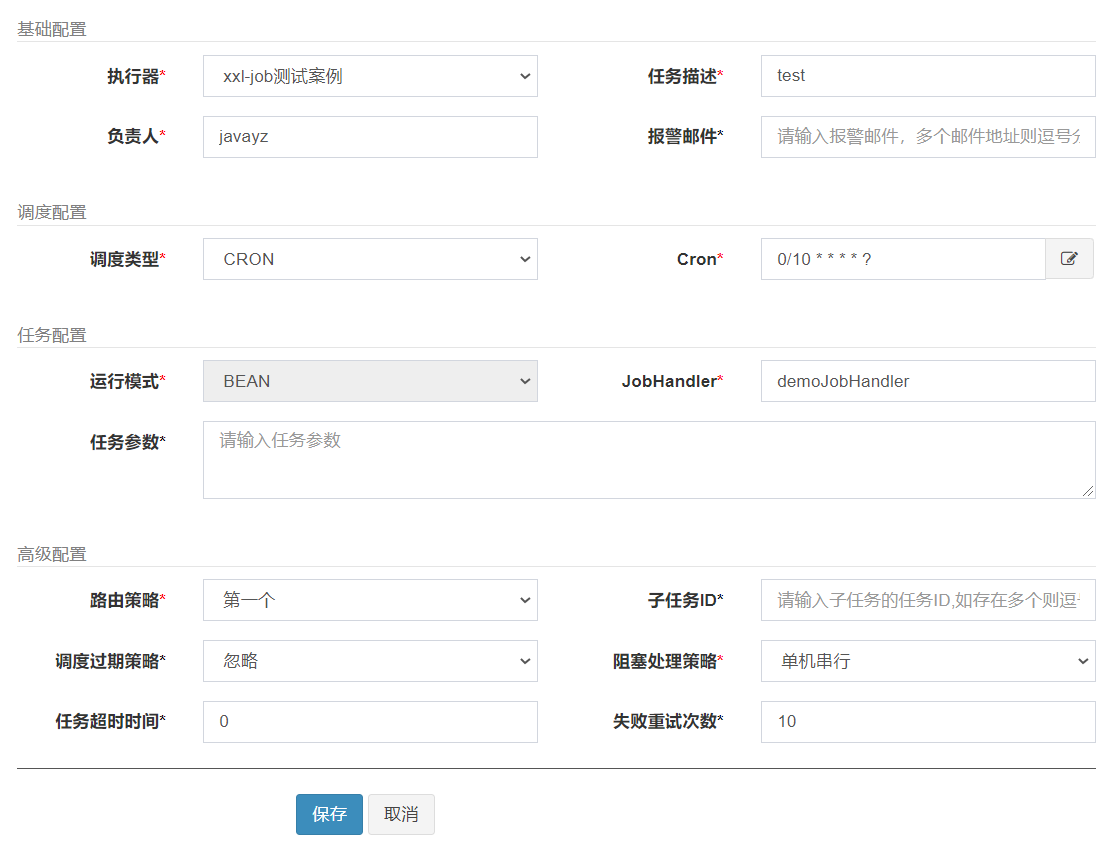
Cron配置了每10s执行一次,配置任务完成后启动任务,定时Job就开始工作了,通过日志可以查看是否执行成功。
# (四)xxl-job集群下的使用 {#四-xxl-job集群下的使用}
既然被称为分布式任务调度平台,xxl-job如何体现分布式场景下的任务调度呢?在任务配置的高级配置中,提供了多种路由策略:
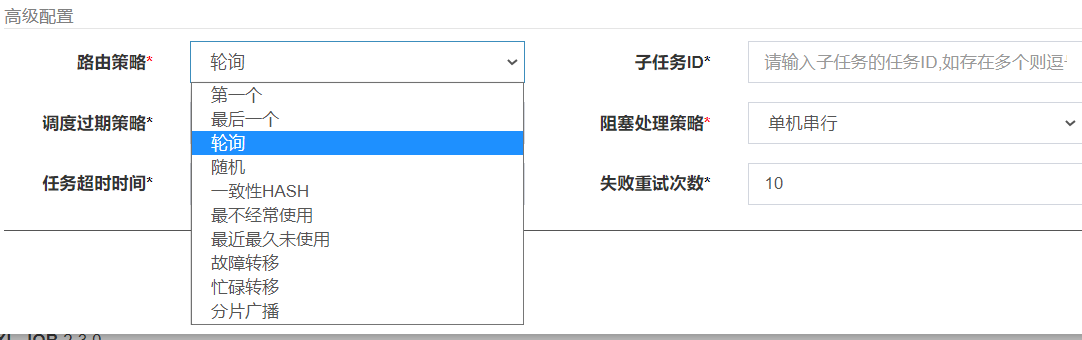
我现在选择轮询,然后修改一下执行器的配置,加入两个地址:
http://172.18.2.49:8999,http://172.18.2.49:8998
同时将测试项目启动两个,两者的配置文件分别为:
#第一个项目
server.port=8081
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
xxl.job.accessToken=
xxl.job.executor.appname=test-xxl-job
xxl.job.executor.address=
xxl.job.executor.ip=172.18.2.49
xxl.job.executor.port=8999
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
xxl.job.executor.logretentiondays=30
#第二个项目
server.port=8082
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
xxl.job.accessToken=
xxl.job.executor.appname=test-xxl-job
xxl.job.executor.address=
xxl.job.executor.ip=172.18.2.49
xxl.job.executor.port=8998
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
xxl.job.executor.logretentiondays=30
再启动任务后,会发现定时任务会在两个项目中轮询的执行:
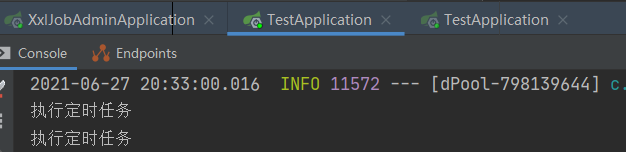
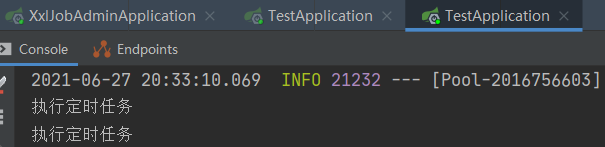
除了轮询之外,像故障转移、忙碌转移策略可以实现容错,一致性哈希可以保证同一个任务只在一台机器上执行。
# (五)总结 {#五-总结}
目前分布式任务调度的开源框架有很多,xxl-job是最常用的,功能确实很完善,同时完全开源。也难怪大量互联网企业在使用它。



![二、Mysql 基于常规显错方式的注入方法 [extractvalue]](https://img1.51tbox.com/static/2024-09-02/FwAcaanKaYrV.png)