# (一)概述 {#一-概述}
Spark计算框架封装了三种主要的数据结构:RDD(弹性分布式数据集)、累加器(分布式共享只写变量)、广播变量(分布式共享支只读变量)
# (二)RDD {#二-rdd}
RDD:弹性分布式数据集是Spark中十分重要的一种数据结构,RDD 是可以并行操作的元素的集合。RDD具有几大属性:
- RDD是由一系列partition组成
- 函数是作用在每个partition(split)上的
- RDD之间有一系列的依赖关系
- RDD提供了一系列最佳的计算位置
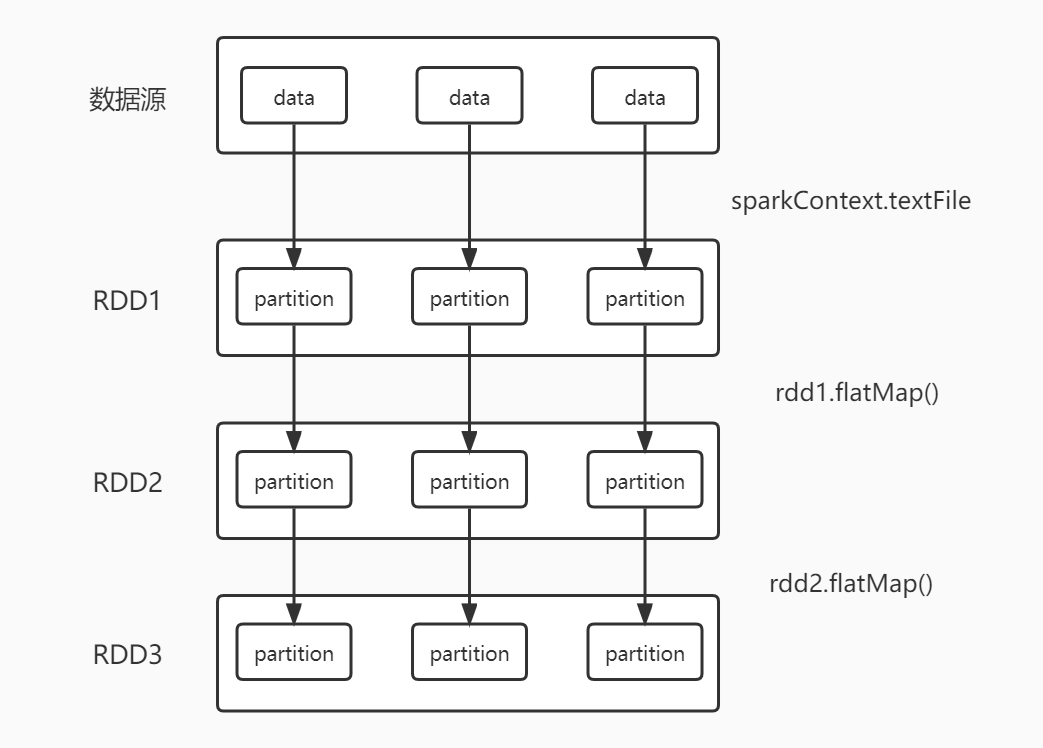
RDD的运行过程可以通过下面这张表来表示,当Spark从数据源读取数据之后,会在RDD中组成多个partition,这些partition可以并行进行操作计算。
# (三)RDD的使用 {#三-rdd的使用}
RDD的创建主要有两种方式,第一种是通过spark提供的parallelize方法来创建:
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
1
2
第二种方法是通过外部数据源直接生成:
JavaRDD<String> lines = sc.textFile("data/*");
1
接下来以scala和Java的案例分别介绍一下RDD的使用,案例依旧是最开始的WordCount例子。
首先是Java版本:
public class JavaWordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("wordCount").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
//读取文件转成RDD
JavaRDD<String> lines = sc.textFile("data/*");
//将每一行的单词根据空格拆分
JavaRDD<String> words = lines.flatMap((FlatMapFunction<String, String>) s -> Arrays.asList(s.split(" ")).iterator());
//将Hello转化为(Hello,1)这种格式
JavaPairRDD<String, Integer> wordToOne = words.mapToPair((PairFunction<String, String, Integer>) s -> new Tuple2<String,Integer>(s,1));
//根据key进行统计
JavaPairRDD<String, Integer> wordToCount = wordToOne.reduceByKey((x, y) -> x + y);
//输出结果
wordToCount.foreach((VoidFunction<Tuple2<String, Integer>>) stringIntegerTuple2 -> System.out.println(stringIntegerTuple2._1+stringIntegerTuple2._2));
sc.close();
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
接下来是scala版本:
object WordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
val sparkContext = new SparkContext(sparkConf);
val lines: RDD[String] = sparkContext.textFile(path = "data/*");
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
val wordToCount = wordToOne.reduceByKey((x, y) => x + y).foreach(println)
sparkContext.stop();
}
}
1
2
3
4
5
6
7
8
9
10
11
其实从这里也能看出来,scala版本会比Java版本看起来更加简洁。 通过上面两段代码可以看出Spark的基本代码流程:
- 创建SparkConf对象。
- 创建SparkContext对象。
- 基于SparkContext对象创建RDD,对RDD进行处理。
- 触发Transformation类算子执行。
- 关闭Spark上下文对象。
# (四)算子 {#四-算子}
算子从功能上可以分为Transformations转换算子和Action行动算子。转换算子用来做数据的转换操作,比如map、flatMap、reduceByKey等都是转换算子,这类算子通过懒加载执行。行动算子的作用是触发执行,比如foreach、collect、count等都是行动算子,只有程序运行到行动算子时,转换算子才会去执行。
一个应用程序中有几个Action行动算子执行,就会有几个Job运行。
# 4.1 常见的转换算子 {#_4-1-常见的转换算子}
filter:过滤记录,true保留,false过滤。
map:将一个RDD中的每个数据项,通过函数映射为一个新的元素。特点:输入一条输出一条。
flatMap:在map执行过后执行flat,和map类似,但是一个输入项可以对应0到多个输出项。
sample:随机抽样算子,根据传进去的小数按照比例进行有放回或者无放回的抽样。
reduceByKey:将相同的Key按照逻辑处理。
sortByKey:作用在Key-Value格式的RDD上,对Key进行升序或者降序排序。
# 4.2 常见的行动算子 {#_4-2-常见的行动算子}
count:返回数据集中的元素数量。会在结果计算完成后回收到Driver端。
take(n):返回包含数据集前n个元素的集合。
first:返回数据集中的第一个元素。
foreach:循环遍历数据集中的每个元素,运行相应的逻辑。
collect:将计算结果回收到Driver端。
# (五)RDD的持久化 {#五-rdd的持久化}
将RDD持久化的算子主要有三种:cache、persist、checkpoint。其中cache和persist都是懒加载,当有一个action算子触发时才会执行,而checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
持久化寸的是RDD中的partition,如果没有使用持久化,一个RDD执行了Action算子后再次执行就需要重新拿数据,使用持久化可以节省代码运行时间。
# 5.1 cache {#_5-1-cache}
cache默认是将RDD的数据持久化到内存中,cache的使用很简单,只需要在RDD之后执行一次即可:
val lines: RDD[String] = sparkContext.textFile(path = "data/*");
lines.cache();
1
2
cache在源码中的实现等于persist
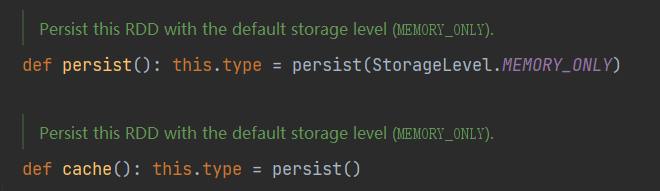
因此cache和persist的关系可以表示为:
cache()=persist()=persist(StorageLevel.MEMORY_ONLY)
1
# 5.2 persist {#_5-2-persist}
persist可以指定持久化的级别,其中MEMORY_ONLY和MEMORY_AND_DISK是最常用的两种持久化方式。
使用方式和cache一样:
val lines: RDD[String] = sparkContext.textFile(path = "data/*");
lines.persist();
1
2
cache和persist的注意事项:
- cache和persist都是懒执行,必须要有一个action类算子触发执行。
- cache和persist的返回值可以赋值给一个变量,在其他job中使用这个变量就是使用持久化的数据。
# 5.3 checkpoint {#_5-3-checkpoint}
checkpoint会将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。
checkpoint的使用也比较简单,首先在SparkContext中设置checkpoint在磁盘中保存的位置,接着执行RDD.checkpoint()
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
val sparkContext = new SparkContext(sparkConf);
sparkContext.setCheckpointDir("./checkpoint")
val lines: RDD[String] = sparkContext.textFile(path = "data/*");
lines.checkpoint();
1
2
3
4
5
checkpoint的执行原理:
- 从finalRDD往前找,当找到某一个RDD调用了checkpoint方法,给这个RDD打上一个标签。
- 启动一个新的job,重新计算这个RDD的数据,最后将数据持久化。 使用技巧: 在使用checkpoint时先对RDD执行cache,这样新启动的job只需要将内存中的数据持久化就可以,节省一次计算的时间。
# (六)Spark中的广播变量 {#六-spark中的广播变量}
当Spark的转换算子在工作时,在函数方法中使用到的所有外部变量都是一个独立的副本,这些变量会随着任务的执行被复制到每台机器上面。但是Spark提供了两种共享变量的类型,分别是广播变量和累加器。
广播变量允许程序员在每台机器上缓存一个只读变量,而不是随任务一起发送它的副本。例如,它们可用于以有效的方式为每个节点提供大型输入数据集的副本。广播变量通过 SparkContext.broadcast(v) 方法创建,通过调用value方法获取具体的值。
public class TestBroadcast {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("wordCount").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
Broadcast<int[]> broadcastVar = sc.broadcast(new int[] {1, 2, 3});
broadcastVar.value();
}
}
1
2
3
4
5
6
7
8
要释放广播变量复制到执行程序的资源,需要调用unpersist()方法,要永久释放广播变量使用的所有资源,需要调用destroy()方法。
broadcastVar.unpersist();
broadcastVar.destroy();
1
2
.
# (七)Spark中的累加器 {#七-spark中的累加器}
累加器也是共享变量中的一种,Spark的计算会被分配到各个工作节点中,因此如果用普通的i++的方式无法获取到预期的累加效果,Spark提供了累加器数据模型,实现数据类加:
public class TestAdd {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("wordCount").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> rdd = sc.parallelize(data);
LongAccumulator accum = sc.sc().longAccumulator();
rdd.foreach(x -> accum.add(1));
System.out.println(accum.value());
}
}
1
2
3
4
5
6
7
8
9
10
11
# (八)总结 {#八-总结}
Spark的核心在于RDD,理解了RDD就相当于对Spark编程彻底入门了,我是鱼仔,我们下期再见。