# (一)关于索引 {#一-关于索引}
索引是帮助Mysql更加高效获取数据的一种数据结构,索引的使用很简单,但是如果不能理解索引底层的数据结构的话,就谈不上去优化索引了。
# (二)B+树 {#二-b-树}
Mysql的索引用的是B+树,他具有这样的几个特点:
1、数据都存储在叶子节点中、非叶子节点只存储索引
2、叶子节点中包含所有的索引
3、每个小节点的范围都在大节点之间
4、叶子节点用指针相连,提高访问性能,比如条件是>或者<的查询就可以直接按指针找(Mysql中的B+树叶子节点中的指针是双向指针)
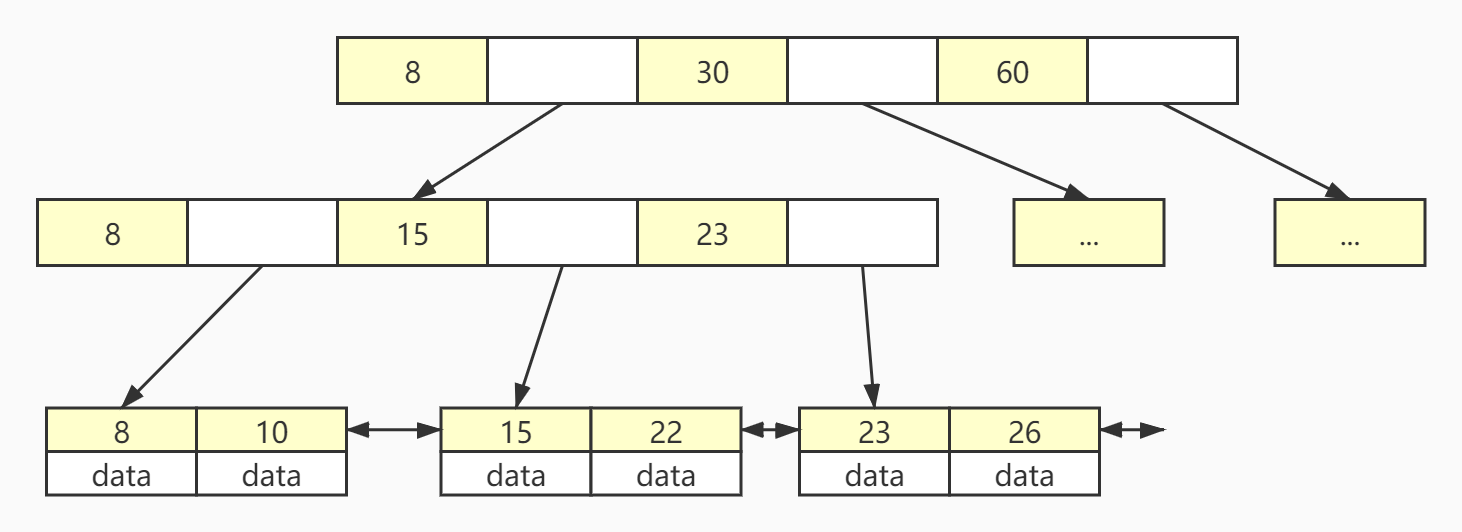
B+树的数据结构如图所示,首先非叶子节点只存储索引,且每个指针所指向的节点最左边的索引都是该指针对应的索引值,比如头节点的第一个索引值8,指向的非叶子节点的第一个索引值也是8。
# (三)为什么索引这么快? {#三-为什么索引这么快}
索引可以支撑千万级表的快速查找,为什么呢?下面就来解释一下:
show GLOBAL STATUS like 'Innodb_page_size'
1
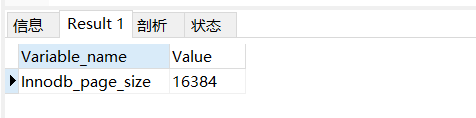
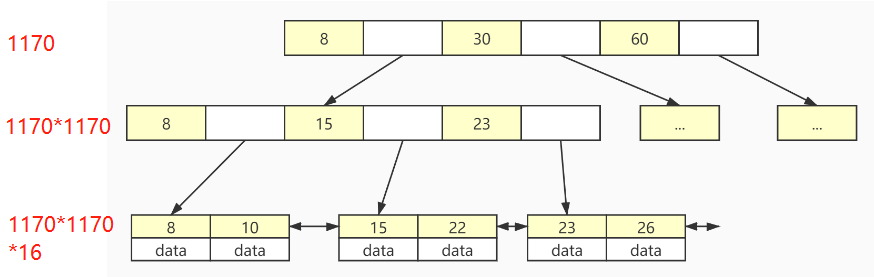
在Innodb中,默认的innodb_page_size大小为16kb ,这就相当于上面每一个节点的大小默认情况下是16kb。一个索引值的大小为8B ,索引后的指针所占大小为4B ,因此可以解算出一个节点中大约可以存储1170个索引。
对于叶子节点,由于存储了数据,我们可以大方地估计每个数据的大小为1kb ,相当于在叶子节点中每个节点可以存储16个数据。
这样就可以计算出一个三层的B+树结构的索引一共可以存储11701170 16=2190万条 数据,这就意味着只需要三次磁盘IO,就可以检索两千万条数据,由此可见索引可以支撑千万级表的快速查找。
# (四)Innodb索引的实现 {#四-innodb索引的实现}
Mysql中的存储引擎有Innodb 和Myisam两种,两种索引的实现底层虽然都是B+树,但是实现形式还是略有不同。
Innodb属于聚簇索引,即叶子节点包含了完整的数据记录。下面这张图是innodb的主键索引,所有的数据都放在叶子节点中。
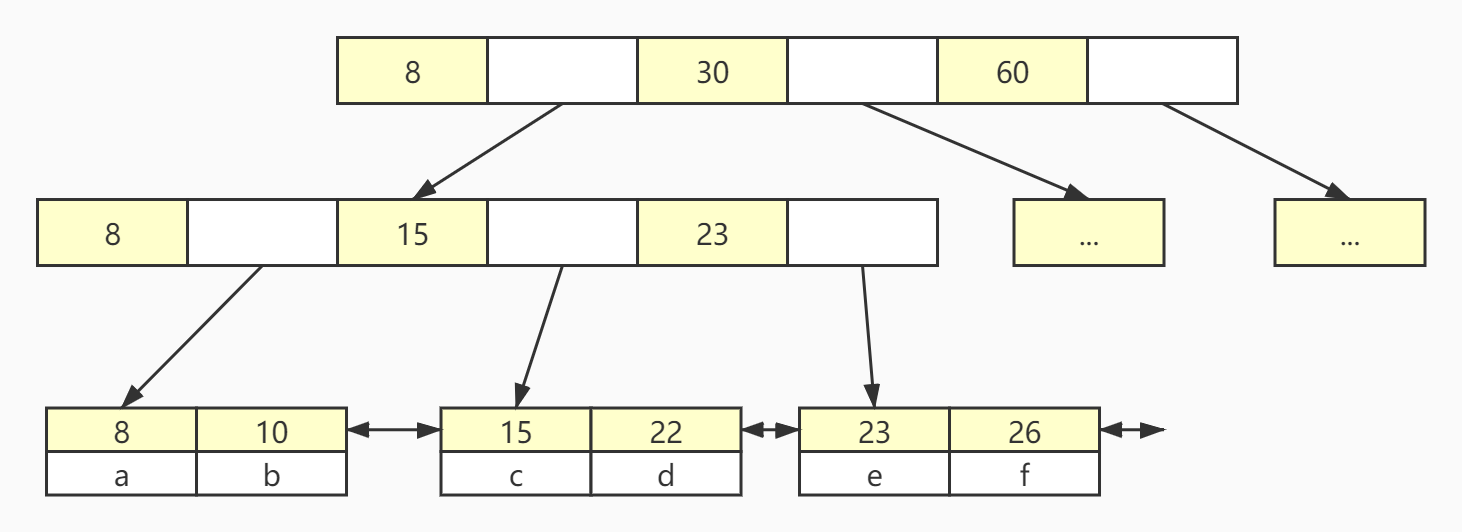
Innodb要求表必须有主键 ,并且推荐使用整型的自增主键,这也和他索引的实现有关,使用整型可以更好的进行B+树的排序,同时采用自增的方式可以在插入数据时将数据插入到最后一个节点的后一个,而不用对已产生的索引拆分。
非主键索引和主键索引略有不通,非主键索引的叶子节点存储的是主键的key值:
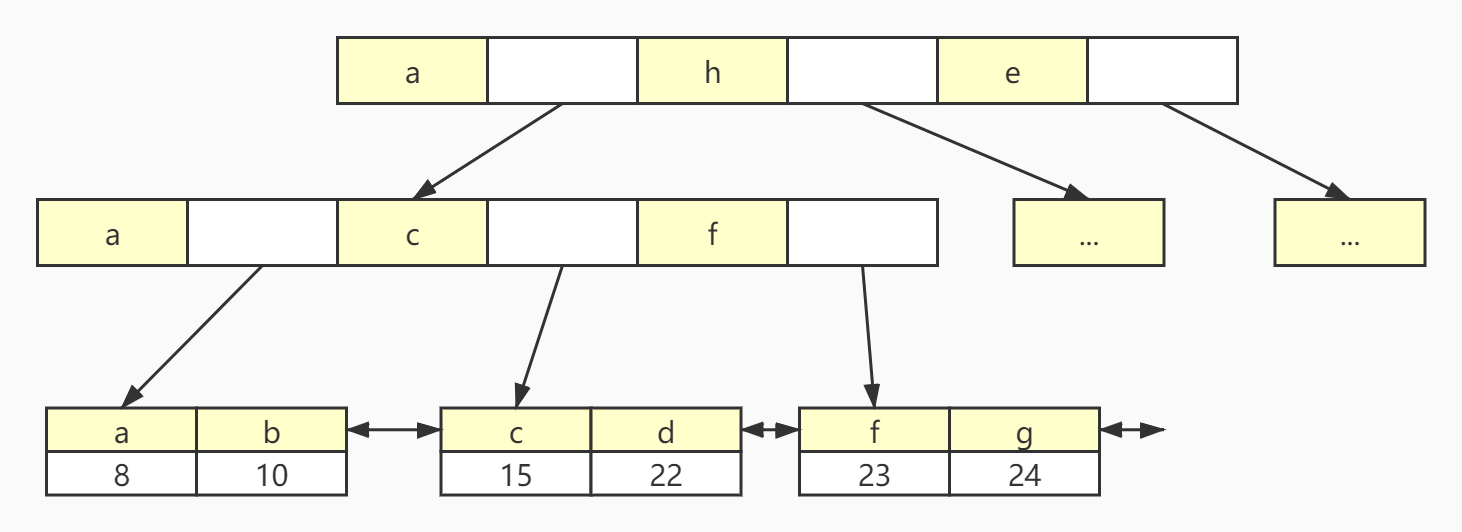
采用这种方式保持了数据的一致性,当新增一条数据时,只需要在主键索引处修改数据即可,而不会出现每个索引各自维护的情况。第二个优势是节省了存储的空间,数据只需要保存一份即可。
# (五)MyIsam索引的实现 {#五-myisam索引的实现}
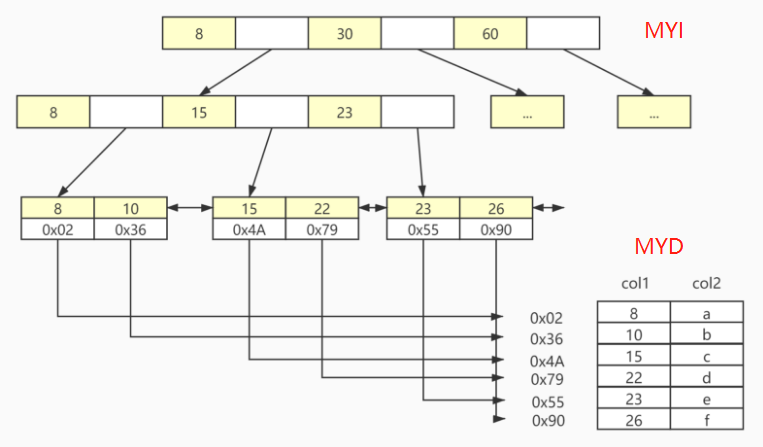
Myisam索引文件和数据文件是分离的,在MyIsam存储引擎中,新建一张表后会在磁盘中增加三个文件:

.frm 文件存储的是表结构,.MYI文件存储的是B+树的索引表,MYD存储的是数据,我通过下面这张表展示MyIsam索引:
# (六)总结 {#六-总结}
关于数据库的索引,绝对是工作中常用,面试常考的问题,他太重要了。理解索引底层数据结构更加重要,这是后续优化的基础,好了,我们下期再见!