# (一)主从复制介绍 {#一-主从复制介绍}
前面所讲的关于redis的操作都属于单机操作,单机操作虽然操作简单,但是处理能力有限,无法高可用。所谓高可用性,就是指当一台服务器宕机的时候,有备用的服务器能顶替上,在单机操作上这是无法实现的,因此就出现了主从复制。 我们把一台服务器看作是主服务器(master),把另外多台服务器看作是从服务器(slave),主从复制就是将master中的数据即时有效的复制到slave中。
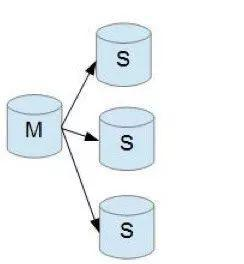
主从复制特征: 一个master可以拥有多个slave,一个slave只对应于一个master master负责执行写数据,将出现变化的数据自动同步到slave slave负责读数据,禁止写数据 有了主从复制之后,就可以实现高可用了,当一台slave宕机后,还有多台slave存在;当master宕机后,由于slave的数据和master是一样的,就可以推选一台slave为新的master,都能做到高可用。
主从复制的作用: 读写分离:master写,slave读 负载均衡:由slave分担master负载,并根据具体的需求可以改变slave的数量 故障恢复:当master出现问题时,可以由slave来代替master,实现快速恢复 数据冗余:有了多台slave,数据备份就变得更加容易
# (二)主从复制环境配置: {#二-主从复制环境配置}
环境配置 可通过info命令查看主从配置
>info replication # 查看当前库的信息
# Replication
role:master #角色 master
connected_slaves:0 # 从机个数
master_replid:8ff09770a496e8472fffef9f35ebdd1bc0b15ecb
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
1
2
3
4
5
6
7
8
9
10
11
12
复制三个配置文件,分别命名为redis6379.conf,redis6380.conf,redis6381.conf然后修改对应的信息
#端口
port 6379 #复制多个改为6380、6381
#pid名字
pidfile /var/run/redis_6379.pid #复制多个改为6380、6381
#log文件名字
logfile "6379.log" #复制多个改为6380、6381
#dump.rdb名字
dbfilename dump6379.rdb #复制多个改为6380、6381
1
2
3
4
5
6
7
8
分别通过配置文件启动redis-server
./redis-server ../redis6379.conf
./redis-server ../redis6380.conf
./redis-server ../redis6381.conf
1
2
3

一主二从的配置
默认情况下,每台redis服务器都是主节点:一般情况下只需要配置从机 在这里我们设置79为主机,80和81为从机
redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379 #设置6379为主机
#在从机中查看信息
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:3
master_sync_in_progress:0
slave_repl_offset:28
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:f669a0ed63ed7f23841baa0c708b3d757d7ccc54
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:28
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:28
在主机中查看信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=112,lag=0
master_replid:f669a0ed63ed7f23841baa0c708b3d757d7ccc54
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:112
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:112
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
同理,设置6381的主机为6379。通过这种方式配置出来的是暂时的主从配置,永久的主从配置我们在配置文件中进行配置。
replicaof <masterip> <masterport> #设置主机的ip和端口
masterauth <master-password> #如果主机有密码则设置密码
1
2
设置主从配置后,在主节点写入后,可在从节点读取,但是在从节点无法写入
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6380> get k1
"v1"
127.0.0.1:6380> set k2 v2
(error) READONLY You can't write against a read only replica.
1
2
3
4
5
6
但是如果主机端开连接后,从机依旧连接的是原来的主机,解决这个问题的话就需要引入哨兵了。 需要注意的是,当从机第一次连接主机后,会引发一次全量复制,后续主机有新的写入会触发增量复制。
# (三)主从复制工作流程 {#三-主从复制工作流程}
主从复制工作流程可以分为三个阶段:
1.建立连接阶段
2.数据同步阶段
3.命令传播阶段(反复同步)
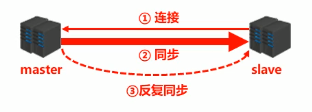
# 3.1 建立连接阶段 {#_3-1-建立连接阶段}
1.设置master的地址和端口号
2.建立socket连接
3.发送ping命令(定时器任务)
4.身份验证
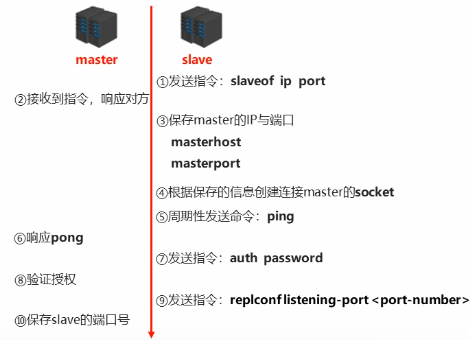
# 3.2 数据同步阶段 {#_3-2-数据同步阶段}
1.请求同步数据
2.创建RDB同步数据
3.恢复RDB同步数据
4.请求部分同步数据
5.恢复部分同步数据
光看这样5步可能有点抽象,用一张图来表示:
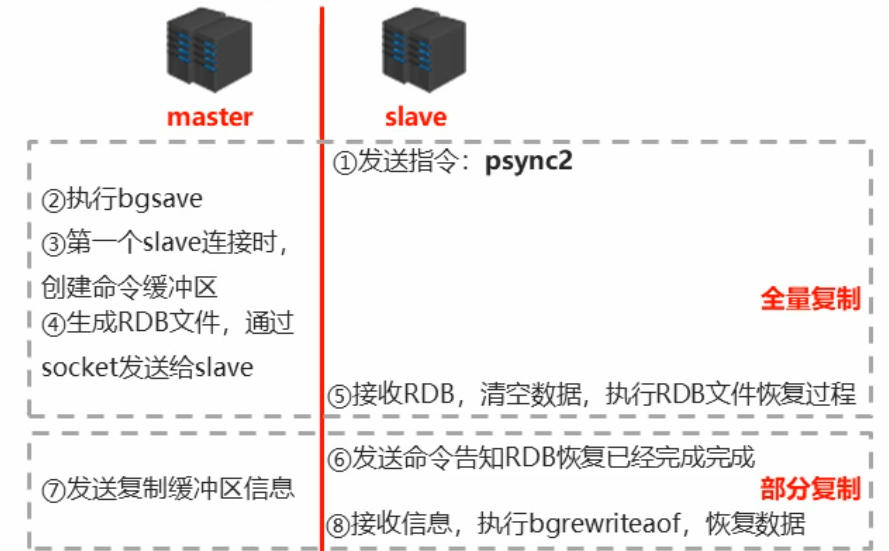
数据同步又分为全量复制和部分复制两块,其中全量复制就是你启动同步指令之后进行的RDB操作,把master中的数据通过RDB发送给slave。由于RDB采用bgsave指令,所以在全量复制期间master所做的操作会进入一个缓冲区,当全量复制结束后就需要通过部分复制来恢复缓冲区中的操作,这里采用AOF。
数据部分同步的注意事项:
通过上面的介绍我们知道了当在进行全量复制时所进行的操作会放入缓存区,但是如果缓存区设置过小就会导致master阻塞,通过下面方式可以设置缓存区大小:
repl-backlog-size 1mb
1
可以通过配置以下参数暂时关闭slave对外服务
slave-server-stable-data yes|no
1
# 3.3 命令传播阶段 {#_3-3-命令传播阶段}
命令传播阶段就是当master数据库状态发生变化,就会通过命令传播阶段同步给slave
命令传播阶段有三个核心要素:
服务器的运行id、主服务器的复制积压缓冲区、主从服务器的复制偏移量
服务器运行id: 服务器运行id是每台服务器每次运行的身份识别码,由40个字符组成,用于在服务器之间传输时识别身份。
主服务器的复制积压缓冲区: 复制积压缓冲区又称为复制缓冲区,是一个先进先出的队列。当master数据库发生变化时,master会将要传播给slave的命令保存在复制缓冲区中,slave分别从复制缓冲区接收信息。
主从服务器的复制偏移量: 因为命令传播阶段首先由master把数据放入缓冲区中,因此master需要一个复制偏移量记录发送给slave的指令对应的位置。而slave要把缓冲区中的数据同步到自己这里,因此也需要一个复制偏移量记录接收到的位置,如果因为意外断网,等网络再次连接之后就可以直接从复制偏移量的位置继续复制。
# 3.4 心跳机制 {#_3-4-心跳机制}
进入命令传播阶段后,master和slave需要通过心跳机制保持双方连接
master心跳:
通过ping指令查询slave是否在线,可由repl-ping-slave-period设置周期,默认10秒
slave心跳:
指令:
replconf ack {offset}
1
周期1秒;
作用:汇报slave自己的复制偏移量;判断master是否在线
当slave多数都掉线或者slave延迟过高时,可以强制关闭master的写功能,停止数据同步:
min-slaves-to-write 2 当连接的slave小于等于2台时停止数据同步
min-slaves-max-lag 10 当连接的slave延迟大于10秒,停止数据同步
1
2





