本文翻译自:https://itsfoss.com/privategpt-setup/ 作者:Abhishek Kumar
设置PrivateGPT AI工具,并完全控制您的数据,与您的文档进行交互或总结。
你有没有想过和你的文档*"* 聊天 "?
比如,你有一篇很长的PDF文档,你非常抗拒阅读它,但它对你的工作或任务很重要。
如果你可以向它提问,比如***"文档中提到了哪些关键特征*** ?"或者"概括一下作者的观点",会怎样呢?
如果几年前有人这么说,这听起来可能太科幻或太未来主义了,但随着市场上各种AI工具的出现,这已经成为了一件很正常的事情。
不仅仅是ChatGPT,现在还有很多免费和付费的基于AI的服务可以完成这样的工作。
但我不太愿意分享我的文档和数据去训练别人的AI。我会自己来做。
我将向你展示我是如何设置PrivateGPT AI的,这是一个开源项目,可以帮助我"与文档聊天 "。你可以尝试并遵循相同的步骤,在你的家庭实验室或个人电脑上设置你自己的PrivateGPT。
不要期待像
ChatGPT那样的快速响应。计算是在您的本地系统上进行的,因此响应速度将取决于您系统的性能。
要实现这样的功能,对计算配置要求如下:
-
基于
X64的Intel/AMD CPU -
8GB RAM(最低要求),但越多越好 -
专用显卡,配备至少
2GB VRAM -
任何
Linux发行版均可正常工作,只需注意包管理命令。此处我使用的是Ubuntu Server 22.04。 -
Python 3.11(重要) -
充足的时间和耐心
下面开始配置过程:
1.更新系统
确保我们的系统安装了所有软件包的最新版本是非常重要的。
sudo apt update && sudo apt upgrade -y
2.安装Python3.11
我们需要Python 3.11。Ubuntu 22.04和许多其他发行版默认安装了较旧的Python 3.10.12版本。因此,您需要升级Python版本。
要检查您的Python版本,请输入:
python3 --version
在Ubuntu中,您可以使用PPA(Personal Package Archive)来获取较新版本的Python。
sudo add-apt-repository ppa:deadsnakes/ppa
在这里,我也将安装另一个名为python3.11-venv的包(了解更多关于Python虚拟环境的信息)。
sudo apt install python3.11 python3.11-venv -y
尽管安装了新版本的Python,但默认版本仍然是3.10。为了更改默认版本,您需要更新我们的alternatives(可选项)。
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.10 110
然后:
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.11 100
现在您在可选项(alternatives)中有两个配置,并且您所需要做的就是更新它们:
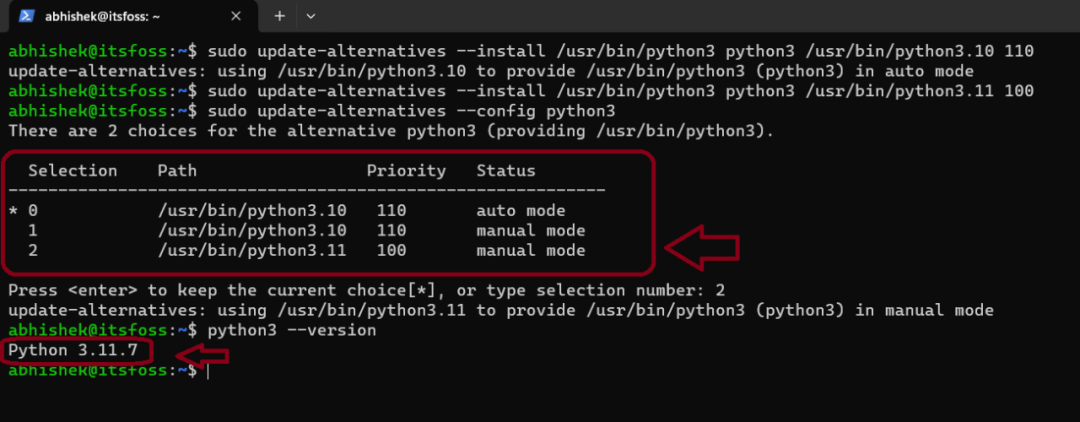
sudo update-alternatives --config python3
您将会被呈现两个选项来选择Python版本,正如您在我提供的截图中所看到的那样,您选择了数字2,这是您所需的版本。
如果您在未来想要切换回早期版本的Python,您可以运行相同的命令并选择您偏好的版本。
3.安装Poetry
可以使用pip来安装Poetry。如果您还没有安装pip,您可以在Ubuntu上使用以下命令来安装pip:
sudo apt install python3-pip
然后:
pip install poetry
在这个步骤中,安装程序可能会抛出一些与PATH相关的错误,就像下面的截图所显示的那样:
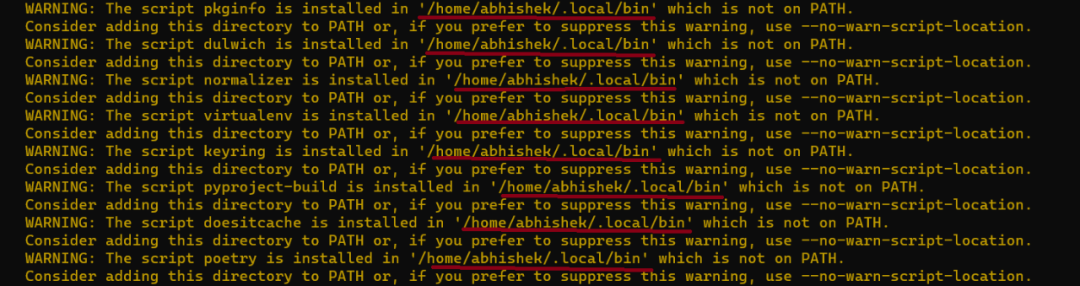
需要将 /home/user/.local/bin 这个目录添加到我们的PATH环境变量中:
nano ~/.bashrc
在这里,您需要在配置文件的末尾添加:
export PATH="$HOME/.local/bin:$PATH"
我使用了确切的值,而没有使用$HOME变量。
为了保存并退出 nano 编辑器,您需要按 CTRL+X,然后会提示您是否保存更改。此时按 y 表示"是",然后按下 Enter 键确认文件名:
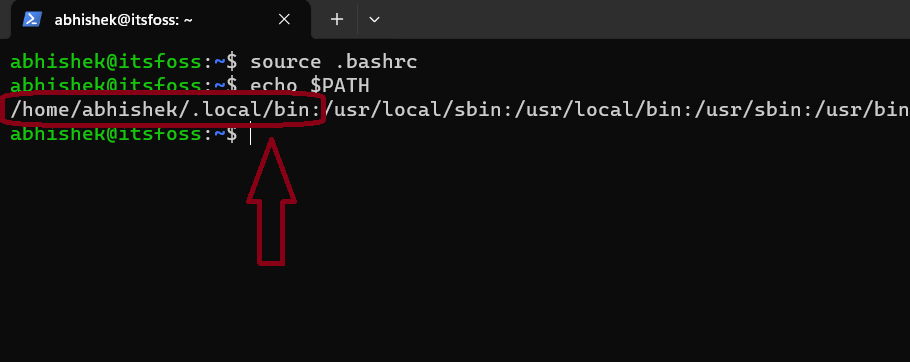
source .bashrc
echo $PATH
输出类类似这样:
现在我们来检查已安装的 Poetry 的版本。它应该是 1.7 或更高版本。
poetry --version
然后,输出信息如下:
Poetry (version 1.7.1)
4.设置 PrivateGPT
首先,您需要在我们的系统中克隆Private GPT仓库。我假设您的系统上已经安装了Git。
git clone https://github.com/imartinez/privateGPT
然后进入目录:
cd privateGPT
现在您需要设置一个新环境,以防止整个系统变得混乱:
python3 -m venv venv
创建新的目录后,然后用下面命令激活虚拟环境:
source venv/bin/activate
5.安装ui和local
因为我们需要与AI进行交互的用户界面,我们需要安装Poetry的用户界面功能,并且由于我们正在托管自己的本地大型语言模型(LLM),所以我们需要本地安装。
poetry install --with ui,local
由于需要安装图形驱动程序和其他对运行大型语言模型(LLMs)至关重要的依赖项,因此这将需要一些时间。
6.安装大语言模型LLM
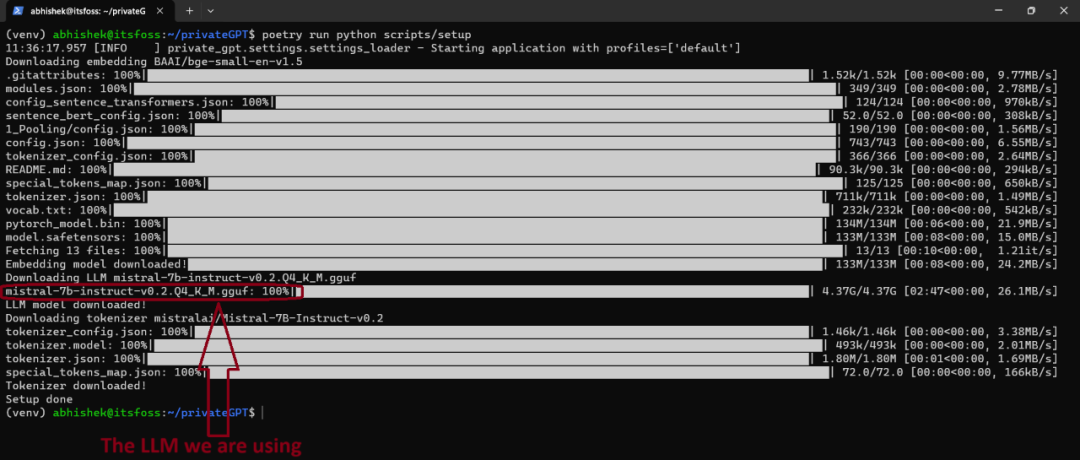
poetry run python scripts/setup
确实,这个过程可能会花费相当长的时间,因为首先需要下载模型,然后才能进行安装。大型语言模型(LLM)的大小通常都很大,超过4GB是很常见的。
7.安装NVIDIA CUDA Toolkit
如果你打算只在你的CPU上运行任何AI模型,那么我有一个坏消息要告诉你。我是说,从技术上讲你仍然可以这样做,但速度会非常慢,甚至可能无法工作。
因此,最好使用具有大量VRAM的专用GPU。我有一个具有2GB VRAM的Nvidia GPU。
sudo apt install nvidia-cuda-toolkit -y
8.编译大型语言模型(LLMs)
你需要编译LLMs就可以开始了:
CMAKE_ARGS='-DLLAMA_CUBLAS=on' poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python
如果你正在使用Windows子系统Linux(WSL)或Mac电脑来跟随这个教程,那么我建议你查看这个官方文档,以找到适合你当前平台的正确命令。
9.运行privateGPT
这一步要求您设置一个本地配置文件,您可以在名为settings-local.yaml的privateGPT文件夹内的文件中进行编辑,但为了不使本教程过长,让我们使用以下命令来运行它:
PGPT_PROFILES=local make run
在您的终端中,它应该看起来像这样,并且您可以在下面看到我们的privateGPT现在已经在我们的本地网络上运行了。
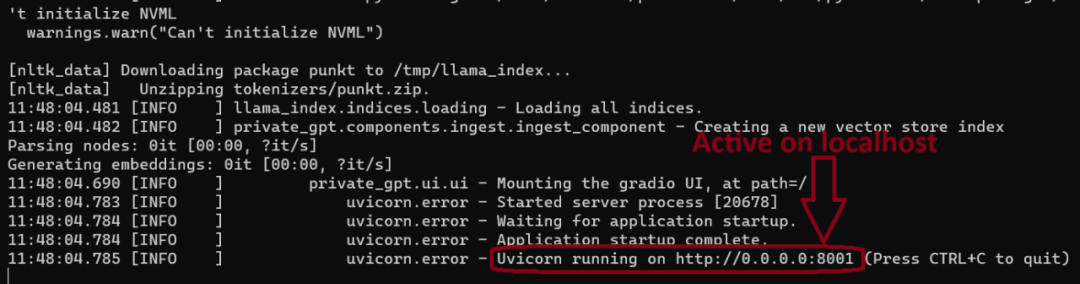
10.用privateGPT和文档进行交互
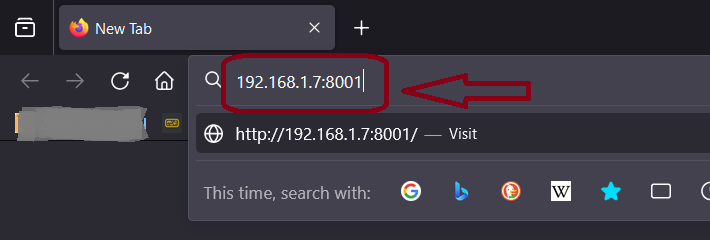
要在浏览器中打开您的第一个PrivateGPT实例,只需在地址栏中输入127.0.0.1:8001即可。它也将通过网络可用,所以请检查您的服务器的IP地址并使用它。
在这里,服务器的IP地址为:192.168.1.7
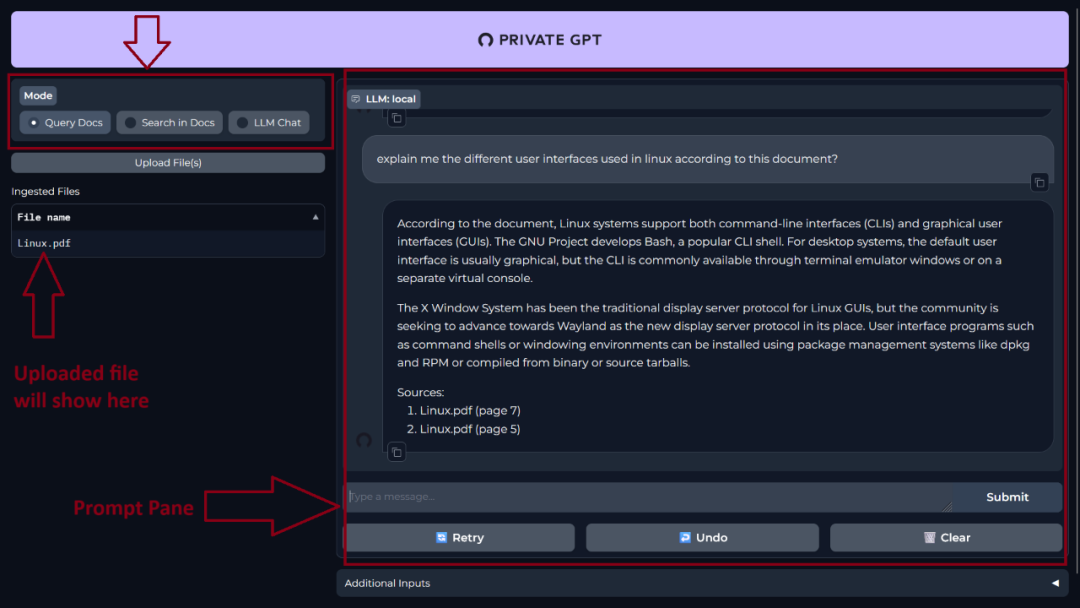
一旦您的页面加载完毕,您将会看到PrivateGPT的简洁用户界面。
在左侧,您可以上传您的文档,并选择您实际想要与AI执行的操作,即"查询文档、在文档中搜索、LLM聊天",而在右侧则是"提示"面板。在这里,您将输入您的提示并收到回复。
我正在使用一篇从维基百科下载的关于Linux的文章。这是一个28页的PDF文档。
以下是我向PrivateGPT提出的一些问题:
以下是另一个问题:

您还可以像与ChatGPT一样与您的LLM(大型语言模型)进行聊天。
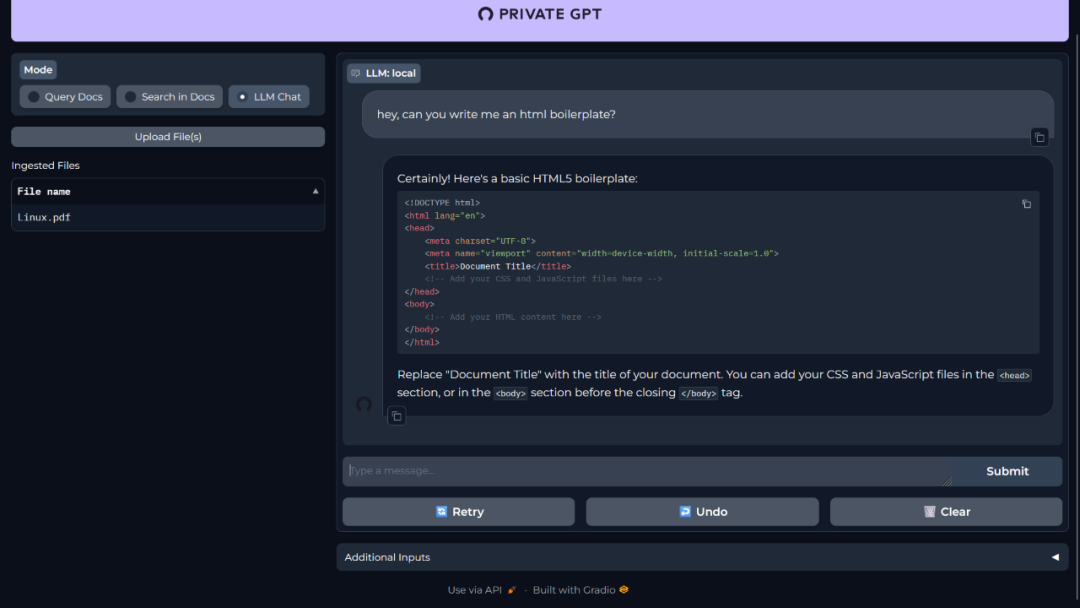
您可以给出更详细和复杂的提示,并且它会给出回答。在我的测试过程中,我发现由于系统性能的不同,响应时间会有很大差异。由于我使用的是较旧的系统,我不得不等待大约2分钟才能得到一次回复。
# 结论
好了,就是这样,您已经设置并托管了自己的PrivateGPT。实际上,您还可以将此服务端口转发到一个域名上,以便在家庭网络之外进行访问。
我知道这个解决方案并不适合所有人,而且这个项目也一直在不断发展中,但它对于想要踏上开源AI旅程的爱好者来说是一个很好的起点。
如果您想尝试更多的大型语言模型(LLMs),您可以跟随我们的教程,在Linux系统上设置Ollama。