https://humanaigc.github.io/emote-portrait-alive/
https://humanaigc.github.io/emote-portrait-alive/
对我们来说,使用Stable Diffusion或Midjourney生成单张2D图像已不再是难题。
然而,当我们尝试将这些连续生成的2D图像串联起来,以期望制作出流畅的视频时,问题就变得复杂了。
在3D生成技术中,数字人(Avatar)技术一直备受关注。
这项技术大致可以分为两大方向:数字人的创建和驱动。
今天,我们将重点探讨数字人驱动方向的一项新进展。
近日,阿里开源了一个名为EMO的项目:Emote Portrait Alive。
在传统技术下,生成的头像视频往往显得生硬、不自然,就像简单拼凑出来的一张张表情图片。
但是,EMO技术的出现改变了这一切。
EMO成功生成了会唱歌的头像视频,效果自然且生动。
那么,EMO技术是如何实现的呢?
它生成的头像视频效果又如何呢?
我们一起探究下。
技术实现
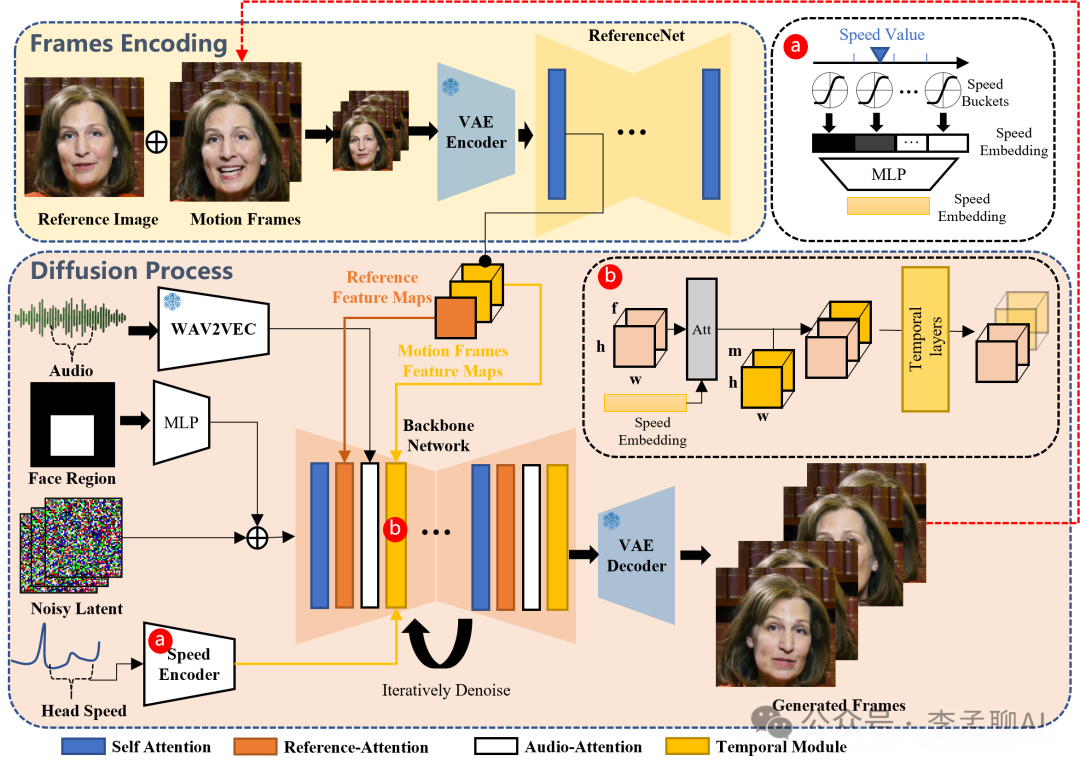 要创造出生动逼真的说话头部视频,EMO框架独辟蹊径,采取了直接音频到视频的合成策略。
要创造出生动逼真的说话头部视频,EMO框架独辟蹊径,采取了直接音频到视频的合成策略。
不同于传统的繁琐流程,它摒弃了3D模型或面部标记点的使用,这种简洁性是否真能达到理想的效果呢?
EMO框架的核心在于,它运用了一个名为Stable Diffusion(SD)的文本 到图像模型。
这个模型能够神奇地将输入的音频信号与图像特征结合起来。
但这里有一个疑问:音频与图像,这两种截然不同的数据形式,真的能够如此和谐地融合吗?
事实上,SD模型借助变分自编码器(VAE)的力量,成功地将原始图像映射到潜在空间。
这一过程不仅降低了计算的复杂性,还保证了图像的高清晰度。
然而,单纯的映射并不足以生成动态的说话视频。
EMO的巧妙之处在于,它引入了适量的噪声,并通过去噪过程逐步揭示出与音频相匹配的面部运动。
为了验证这一创新方法的有效性,研究者们构建了一个庞大的音视频数据集。
这个数据集包含了超过250小时的视频和1.5亿张图像,涵盖了从演讲到歌唱表演的各种场景。
如此丰富多样的数据,无疑为EMO提供了充足的学习资源。  https://arxiv.org/pdf/2402.17485.pdf
https://arxiv.org/pdf/2402.17485.pdf
但与此同时,一个显而易见的问题是:在众多现有的音视频合成方法中,EMO真的能够脱颖而出吗?
为了回答这个问题,研究者们进行了一系列严格的实验和评估。
令人惊讶的是,与当前最先进的几种方法相比,如DreamTalk、Wav2Lip和SadTalker,EMO在各项指标上都展现出了优越的性能。
头像视频
输入一张人像和一段音频,人像就能唱歌?
只需单张人像图和一段唱歌的音频,我们的新方法就能生成表情丰富、头部姿态多变的虚拟歌手视频。
视频时长随音频长短而定,人物特征始终保持一致。
而且,这种方法支持多种语言和画像风格。
无论哪种语言的歌曲,都能通过音频的音调变化,让人像生动起来。
节奏快也不怕,我们的虚拟歌手能紧跟节奏,就算歌词再快,也能保证表情和动作的同步。
除了唱歌,这种方法还能用于对话。
无论是哪种语言的口语音频,都能让人像动起来。
甚至,它还能让历史人物、画作人物、3D模型和AI生成内容"复活"。
想象一下,电影角色用不同语言表演,会是什么样子?
我们的方法就能实现这一点,为角色扮演带来更多可能性。
结语
技术的边界在不断拓展,而我们的想象力是无尽的。
EMO的出现,不仅是数字人技术的一次突破,更是对未来虚拟表达方式的一次大胆预演。
在技术与创意的碰撞中,我们将共同见证一个更加丰富多彩的虚拟世界的诞生。
EMO的成功是否意味着传统制作方式的终结?
音频与图像的深度融合又将引领我们走向怎样的未来?
欢迎留言讨论!