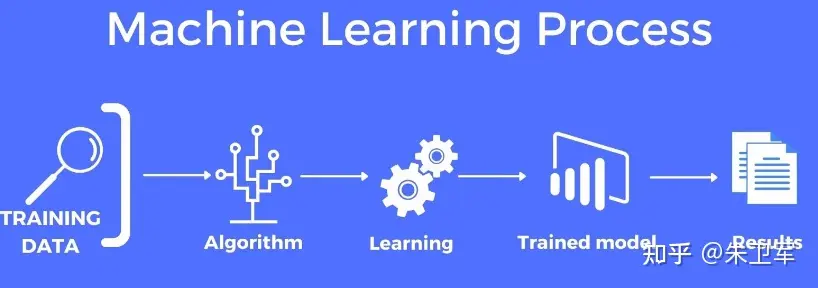
机器学习看似复杂,但简单地来说,机器学习是训练一个数学模型,用于预测的过程。
举个例子,你教小学生玩王者荣耀。你不需要告诉他每一个动作的每一个细节,只需要给他一些规则和一些练习,他就能自己学会如何玩这个游戏。这个学的过程就是在训练脑子里的模型。
机器学习也是差不多的原理,它通过分析大量数据来学习规律,然后根据这些规律对未来的数据做出预测。
小学生会通过不断玩某个英雄,然后技巧越来越厉害,最后升到王者。机器学习算法也是通过不断分析数据来提高自己的预测能力,基本上训练数据越大越准确。
机器学习算法不断尝试找到一个函数,这个函数能够最准确的映射输入数据(比如图片)到输出结果(比如识别"猫"或"狗")。
 再比如,你想要开发一款预测你家狗何时尿尿的机器学习应用。
再比如,你想要开发一款预测你家狗何时尿尿的机器学习应用。
你可以为机器学习模型提供大量狗的特征和生活习惯的数据,比如品种、年龄、体重、喝水量、喝水时间、尿尿时间、健康状态等等,直到机器学习模型最终学习到狗尿尿时间与其他特征之间的数学关系,可以推测出大致的的时间点。
比如下面用Python演示下这个预测过程。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 示例数据
data = {
'Age': [1, 3, 5, 2, 4], # 狗狗的年龄
'Weight': [10, 20, 15, 25, 18], # 狗狗的体重
'Water_Intake': [200, 250, 300, 350, 330], # 每日饮水量
'Last_Pee_Time': [120, 180, 240, 100, 150], # 自上次尿尿以来的分钟数
'Time_Since_Last_Pee': [30, 60, 45, 90, 75] # 目标变量:上次尿尿到现在的时间(分钟)
}
# 创建DataFrame
df = pd.DataFrame(data)
# 定义特征和目标
X = df.drop('Time_Since_Last_Pee', axis=1)
y = df['Time_Since_Last_Pee']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林模型
model = RandomForestClassifier(n_estimators=100)
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'模型准确率: {accuracy * 100:.2f}%')
现在基本可以把机器学习分为三类,我们拿学生考试做类比。
监督式学习:这类学生刷了很多旧题后考试
非监督式学习:这类学生不刷题,通过记公式和找规律来考试
强化学习:这类学生也不刷题,通过试错来考试,对了就奖励,错了就惩罚
 机器学习之所以会流行,因为它能够解决那些难以通过传统编程方法解决的复杂问题,比如预测、分类、推荐、聚合等等。
机器学习之所以会流行,因为它能够解决那些难以通过传统编程方法解决的复杂问题,比如预测、分类、推荐、聚合等等。
现在机器学习的应用已经非常多了,从简单的图像识别、语音识别,到复杂的医疗诊断、股市分析等,还有最近的大模型也属于机器学习的一种
学习机器学习需要对数学基础如线性代数、概率论和统计学有基本的了解。你可以从简单的模型开始,多参加一些比赛、项目,像kaggle之类,久而久之就会摸熟其中的原理。
Python中的sklearn库提供了大量机器学习算法调用接口,包括分类、回归、聚类、降维、模型选择、预处理等,你可以自定义参数进行模型调优。它建立在NumPy、SciPy和matplotlib之上,所以能很好的和Python其他库进行交互。
sklearn库核心功能如下:
-
分类:支持多种分类算法,如逻辑回归、决策树、随机森林、SVM等。
-
回归:提供线性回归、多项式回归、岭回归等算法。
-
聚类:如K-means、层次聚类等。
-
降维:包括PCA(主成分分析)、LDA(线性判别分析)等。
-
模型选择:交叉验证、网格搜索等用于选择最佳模型参数的工具。
-
数据预处理:特征选择、标准化、归一化等。
下面列举一些主要算法的使用方法。
逻辑回归
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建逻辑回归模型
model = LogisticRegression(max_iter=200) # 增加迭代次数以避免警告
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算准确率
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
决策树
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算准确率
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
线性回归
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
X = boston.data
y = boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
聚类算法
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 生成模拟数据
X, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 创建K-means模型,设置聚类数为4
kmeans = KMeans(n_clusters=4)
# 训练模型(即找到聚类中心)
kmeans.fit(X)
# 预测每个样本的聚类标签
y_kmeans = kmeans.predict(X)
# 这里可以进一步分析聚类结果,比如打印聚类中心等
print(kmeans.cluster_centers_)
其他还有很多算法,可以在sklearn中去摸索使用。