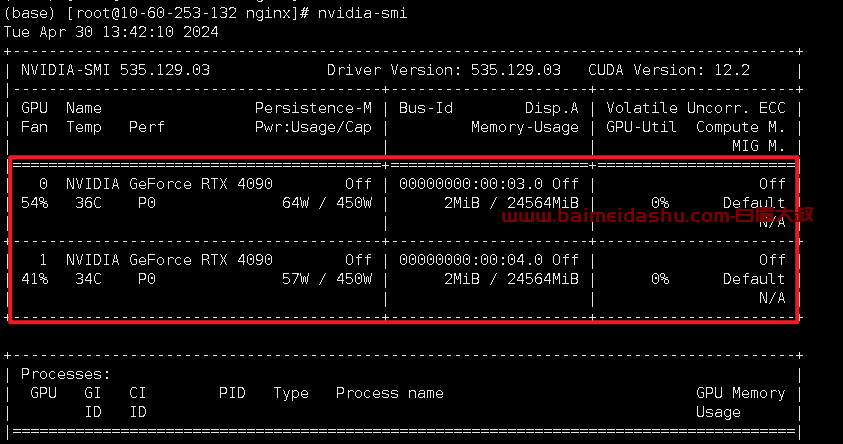
场景, 宿主机有GPU ,2个 4090显卡
1- 需要提前禁用nouveau:
lsmod | grep nouveau
没有输出即禁用了
2- 需要安装
参考: https://blog.csdn.net/qq_42152032/article/details/131342043
1、显卡驱动
2、cuda库(安装cuda会自动安装显卡驱动)
3、cudnn(深度神经网络的GPU加速库,需要神经网络则安否则可以不安)
安装完成后,可以在本机运行nvidia-smi查看GPU设备的状态。
Docker使用gpu:
nvidia-docker2.0对nvidia-docker1.0进行了很大的优化,不用再映射宿主机GPU驱动了,直接把宿主机的GPU运行时映射到容器即可,容器内无需安装gpu驱动和cuda了。
https://blog.csdn.net/qq_42152032/article/details/131342043
二、Docker19.03之后,内置gpu支持
增加了对--gpus选项的支持,我们在docker里面想读取nvidia显卡再也不需要额外的安装nvidia-docker2了。
安装nvidia-container-runtime
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
sudo yum install -y nvidia-container-toolkit nvidia-container-runtime
这个地方要重启 一下docker 才能生效
systemctl restart docker
3、运行容器时,添加--gpu参数启用gpu支持。
使用所有GPU
docker run --gpus all nvidia/cuda:9.0-base nvidia-smi
使用两个GPU
docker run --gpus 2 nvidia/cuda:9.0-base nvidia-smi
指定GPU运行
docker run --gpus '"device=1,2"' nvidia/cuda:9.0-base nvidia-smi
或者:
docker run --gpus '"device=UUID-ABCDEF,1"' nvidia/cuda:9.0-base nvidia-smi
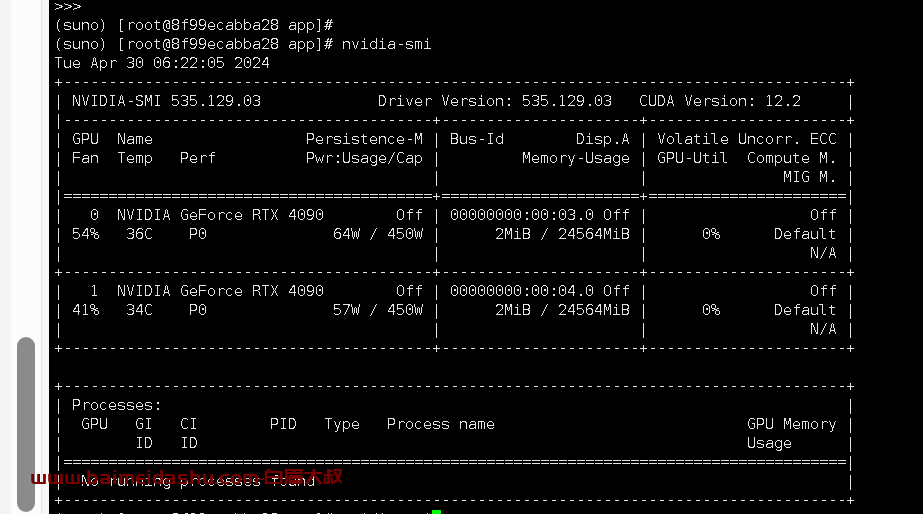
检测:
docker exec -it centos #进入容器
nvidia-smi #容器内查看gpu使用情况 这样就表明,容器中可以使用宿主机的显卡了
测试:
docker pull ufoym/deepo:keras-py36-cu80
#拉取支持gpu的keras & tensorflow环境
docker run --gpus all --rm -it ufoym/deepo:keras-py36-cu80
#启动后,进入容器。
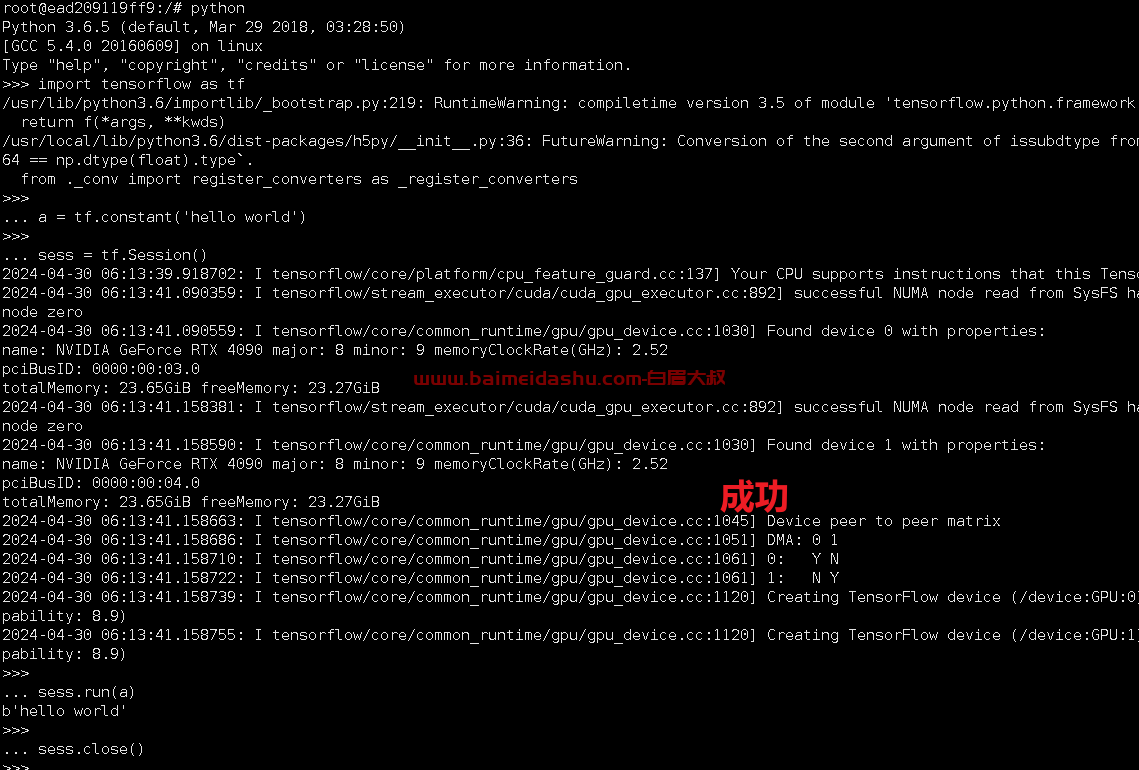
进入python环境 (docker run --gpus all --rm -it ufoym/deepo)
python
输入代码:
import tensorflow as tf
a = tf.constant('hello world')
sess = tf.Session()
sess.run(a)
sess.close()
报错:docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].
解决:确保安装了nvidia-container-runtime,然后 重启 docker : systemctl restart docker即可。
还有nvidia-container-toolkit这个插件
这个插件是对k8s集群的,能够让pod识别到GPU资源