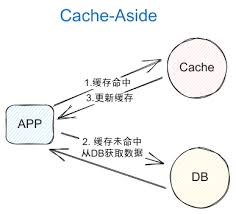
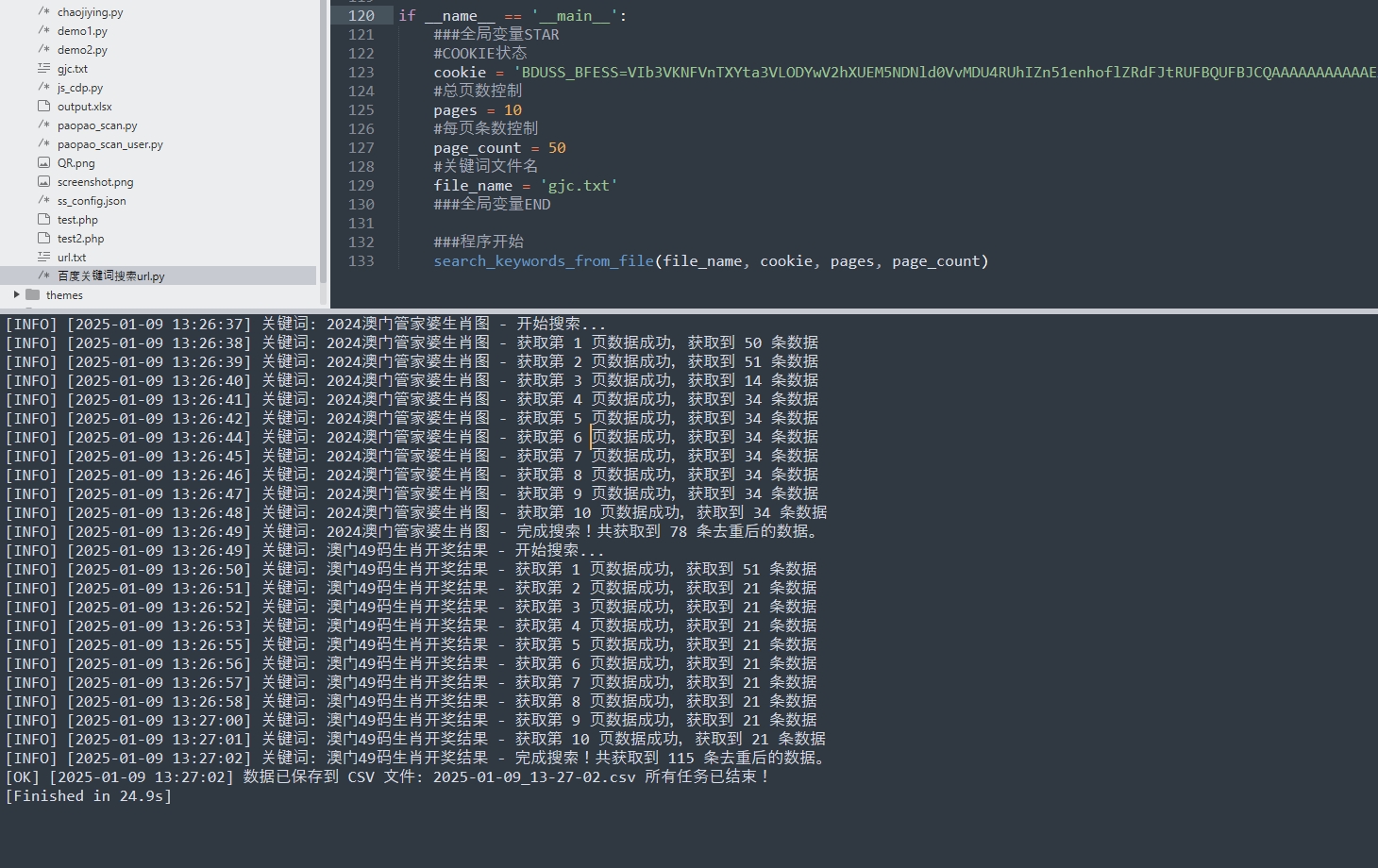
通过关键词字典,百度批量搜索网站URL,主要是方便做涉网打黑时目标批量寻找等,没加入多线程是为了避免被百度反爬虫拦截,送给有需要的人。
import requests
import json
from urllib.parse import urlparse
from fake_useragent import UserAgent
import time
import os # 用于退出脚本
import csv
def get_current_time():
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
def print_info(message_type, keyword, message):
if keyword:
print(f"[{message_type}] [{get_current_time()}] 关键词: {keyword} - {message}")
else:
print(f"[{message_type}] [{get_current_time()}] {message}")
def get_web_page(wd, pn, url_set, search_lists, Cookie, page_count):
url = 'http://www.baidu.com/s'
ua = UserAgent()
headers = {
'User-agent': ua.random,
'Cookie': Cookie,
'Host': 'www.baidu.com'
}
params = {
'word': wd,
'pn': str((pn - 1) * 50),
'tn': 'json',
'ie': 'utf-8',
'rn': page_count,
'sa': 'ib',
}
`while True: # 无限重试
try:
response = requests.get(url, headers=headers, params=params, timeout=10)
# 检查 HTTP 状态码
if response.status_code == 200:
# 状态码是 200,表示请求成功,开始解析 JSON 数据
response.encoding = 'utf-8'
search_list = json.loads(response.text)['feed']['entry']
for search_key in search_list:
raw_url = search_key.get('url', None) # 使用 .get() 方法,若没有 'url' 则返回 None
category = search_key.get('category', {}).get('value', 'No category') # 使用 .get() 获取 category['value'],若没有则返回默认值
if raw_url: # 如果 url 存在,处理 url
# 提取域名部分
parsed_url = urlparse(raw_url)
domain = parsed_url.netloc # 获取域名,去掉协议和路径部分
# 如果域名不在集合中,则添加到列表和集合中
if domain not in url_set:
search_lists.append((raw_url, category))
url_set.add(domain) # 使用域名去重,而不是完整 URL
print_info('INFO', wd, f"获取第 {pn} 页数据成功,获取到 {len(search_list)} 条数据")
return True # 获取成功,返回 True
elif response.status_code in [301, 302]:
# 如果是 301 或 302 重定向状态码,退出程序
print_info('ERROR', wd, "检测到脚本出现验证码,程序退出,出现这个问题就自己浏览百度,然后将所有COOKIE复制到下面的cookie变量中替换就行了。")
os._exit(0) # 立即结束脚本
else:
# 处理其他状态码,例如 400、404 等
print_info('ERROR', wd, f"请求失败,状态码: {response.status_code}")
print_info('INFO', wd, f"1秒后开始重试...")
time.sleep(1) # 等待 1 秒后重试
except Exception as e:
print_info('ERROR', wd, f"获取第 {pn} 页数据失败: {e}")
print_info('INFO', wd, f"1秒后开始重试...")
time.sleep(1) # 每次重试等待 1 秒
`
def save_to_csv(search_lists):
# 使用当前时间作为文件名
filename = get_current_time().replace(" ", "_").replace(":", "-") + ".csv"
`# 打开 CSV 文件,写入数据
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
# 写入列头
writer.writerow(["URL", "关键词"])
# 写入每一行数据
for url, category in search_lists:
writer.writerow([url, category])
print_info('OK', '', f"数据已保存到 CSV 文件: {filename} 所有任务已结束!")
`
def search_keywords_from_file(filename, cookie, pages, page_count):
search_lists = [] # 用来存储所有的搜索结果
url_set = set() # 用来存储已添加的 URL 的域名部分
`with open(filename, 'r', encoding='utf-8') as file:
keywords = file.readlines()
for keyword in keywords:
keyword = keyword.strip() # 去掉关键词两侧的空格或换行符
if not keyword:
continue # 如果为空行,跳过
print_info('INFO', keyword, "开始搜索...")
for page in range(1, pages + 1): # 每个关键词翻10页
success = get_web_page(keyword, page, url_set, search_lists, cookie, page_count)
if not success: # 如果请求失败,继续重试
print_info('ERROR', keyword, f"第 {page} 页获取失败,正在重试...")
page -= 1 # 保持在当前页,继续重试
time.sleep(1) # 每个请求间加一点延时
# 打印每个关键词的去重后数据数量
print_info('INFO', keyword, f"完成搜索!共获取到 {len(search_lists)} 条去重后的数据。")
# 保存数据到 CSV 文件
save_to_csv(search_lists)
`
if name == 'main':
###全局变量STAR
#COOKIE状态
cookie = 'BDUSS_BFESS=VIb3VKNFVnTXYta3VLODYwV2hXUEM5NDNld0VvMDU4RUhIZn51enhoflZRdFJtRUFBQUFBJCQAAAAAAAAAAAEAAAANAu4nQ3JhY2tlcl9XYWxrZXIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANW1rGbVtaxmSk;'
#总页数控制
pages = 10
#每页条数控制
page_count = 50
#关键词文件名
file_name = 'gjc.txt'
###全局变量END
`###程序开始
search_keywords_from_file(file_name, cookie, pages, page_count)</pre>
`