mysql数据库索引构建过程
在MySQL数据库服务中,是有很多种索引类型的,但是比较常用的索引类型主要有:
| 序号 | 类型 | 说明 |
|------|----------|--------|
| 类型01 | B+Tree | 默认类型索引 |
| 类型02 | Hash | 算法类型索引 |
| 类型03 | R+Tree | 空间类型索引 |
| 类型04 | Fulltext | 全文类型索引 |
数据库服务在进行BTree索引构建时,是比较重要的知识点,因为最终还是会应用BTree算法知识进行索引的构建,常用方法有:
索引方式一:聚簇索引(集群索引/聚集索引)
索引方式二:辅助索引
1-索引方式一:聚簇索引(集群索引/聚集索引)
聚簇索引主要是:将多个簇(区-64个数据页-1M)聚集在一起就构成了所谓聚簇索引,也可以称之为主键索引;
聚簇索引作用是:用来组织存储表的数据行信息的,也可以理解为数据行信息都是按照聚簇索引结构进行存储的,即按区分配空间的;
聚簇索引的存储:聚簇是多个簇,簇是多个连续数据页(64个),页是多个连续数据块(4个),块是多个连续扇区(8个);
总结:利用聚簇索引可以实现从物理上或逻辑上,都能满足数据存储的连续性关系,方便进行数据查找的有序性IO;(IOT组织表)
聚簇索引的构建方式:
数据表创建时,显示的构建了主键信息(pk),主键(pk)就是聚簇索引;
数据表创建时,没有显示的构建主键信息时,会将第一个不为空的UK的列做为聚簇索引;
数据表创建时,以上条件都不符合时,生成一个6字节的隐藏列作为聚簇索引
结合下图信息,可以看出聚簇索引组织存储数据过程与加速查询过程原理:
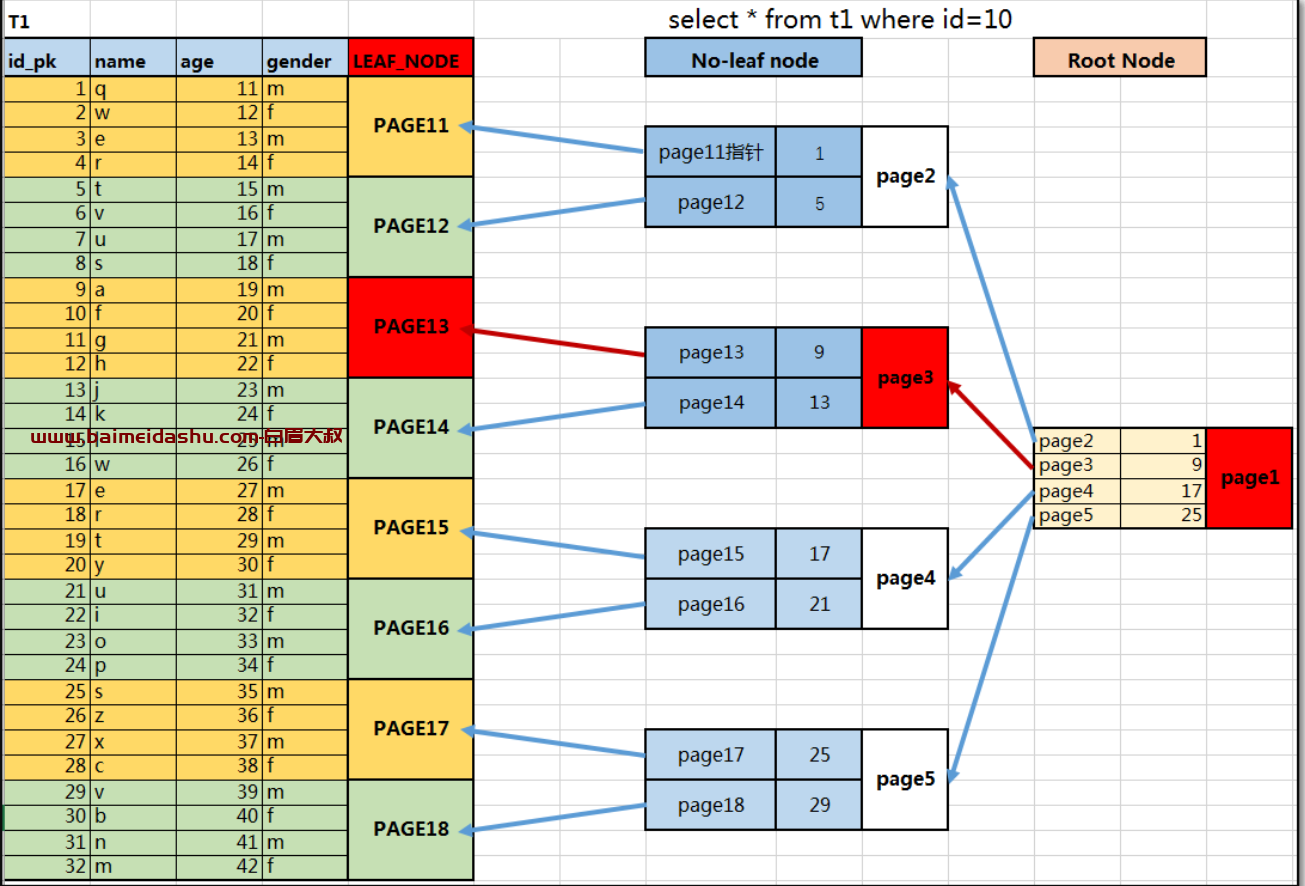
以上图信息为例,若显示创建ID列为pk自增列:
① 按照ID逻辑顺序,在同一个区中连续的数据页上,有序存储数据行;
② 数据行所在的数据页,作为聚簇索引的叶子节点(叶子节点就是所有数据行);
③ 叶子节点构建完后,可以构建no-left(支节点),用于保存的是leaf节点中的ID范围和指针信息;
④ 支节点构建完后,可以构建root(根节点),用于保存的是no-leaf节点中的ID范围和指针信息;
⑤ 并且leaf节点和no-leaf相邻数据页之间都具有双向指针,从而加速数据的范围查找;
2-索引方式二:辅助索引
辅助索引主要是:主要用于辅助聚簇索引查询的索引,一般按照业务查找条件,建立合理的索引信息,也可以称之为一般索引;
辅助索引作用是:主要是将需要查询的列信息可以和聚合索引信息建立有效的关联,从而使数据查询过程更高效,节省IO和CPU消耗
辅助索引的存储:调取需要建立的辅助索引列信息,并加上相应主键列的所有信息,存储在特定的数据页中;
总结:利用辅助索引与聚合索引建立的关联,先经过辅助索引的查询获取对应聚簇索引,在经过聚簇索引回表查询获取详细数据;
辅助索引的构建方式:
必须手动构建。
数据表创建时,显示的构建了一般索引信息(mul),一般索引信息(mul)就是辅助索引;
数据表创建时,没有显示的构建一般索引信息时,在查询检索指定数据信息,会进行全表扫描查找数据;
结合下图信息,可以看出辅助索引组织存储数据过程与加速查询过程原理:
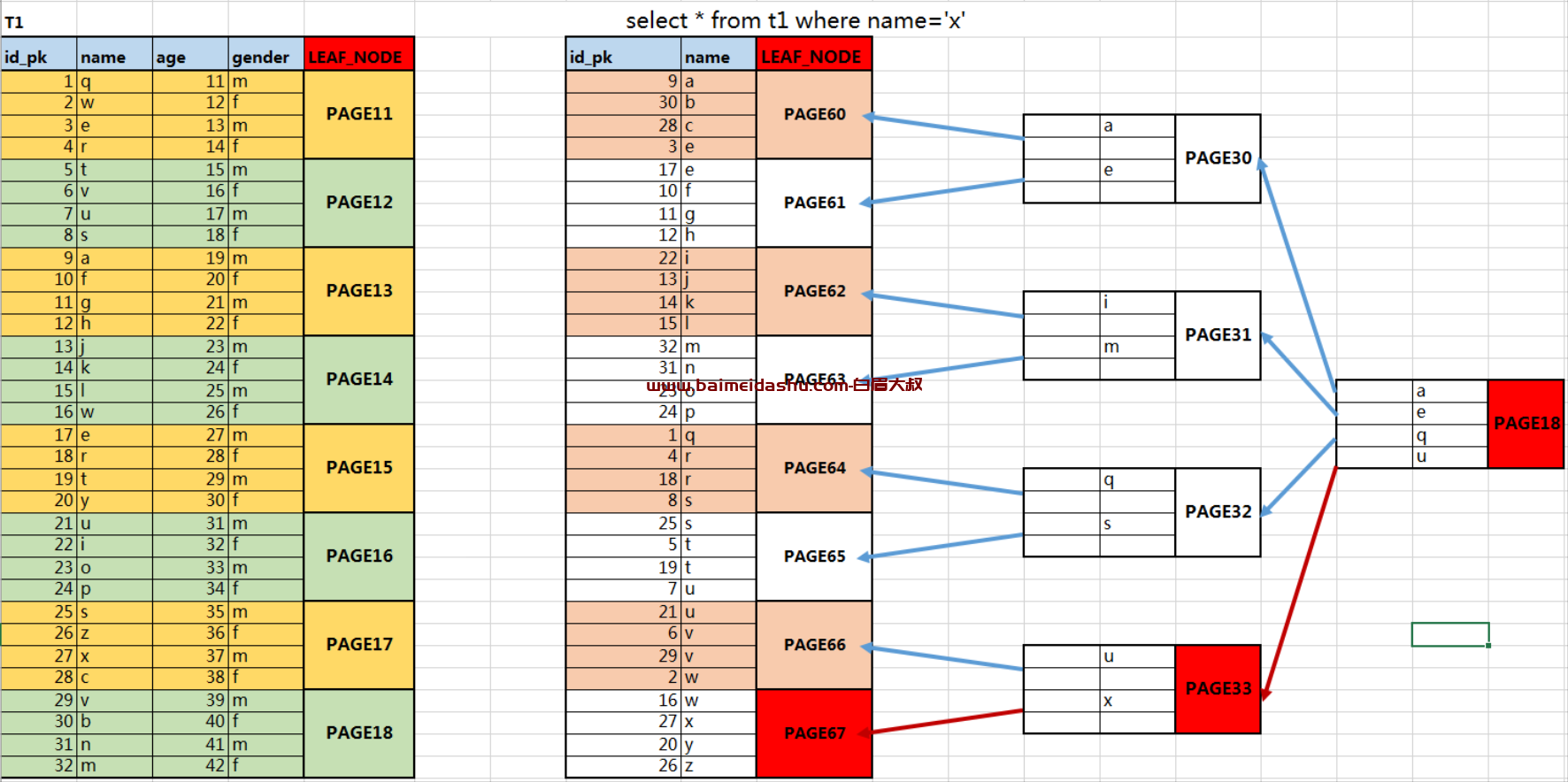
白话说明:
先找到 name =x 所在的page , 在 page67 上, 然后, 找到 id_pk = 27 . 然后就 回表 (聚簇索引表)找到 id_pk =27 所在 page . 这样就是一个过程。
如果有3个 x ,就回 有3次回表。
以上图信息为例,若显示创建name列为mul查询列:
① 调取需要建立的辅助索引列信息,并加上相应主键列的所有信息,存储在特定的内存区域中;
② 根据调取的辅助索引列信息,进行字符的顺序排序,便于形成范围查询的区间,并将排序后的数据信息存储在特定数据页中;
③ 叶子节点构建完后,可以构建no-left(支节点),用于保存的是leaf节点中的字符范围和指针信息;
④ 支节点构建完后,可以构建root(根节点),用于保存的是no-leaf节点中的字符范围和指针信息;
⑤ 找到相应辅助索引的数据信息后,在根据辅助索引与聚簇索引的对应关系,获取到相应的主键信息,从而获取相应其他数据信息
在利用聚簇索引获取其他数据信息的过程,也可以称之为回表查询过程;
优化思路:
(1)回表次数越少越好
(2)索引树越低越好。
辅助索引检索数据产生回表问题分析: (回表次数越少越好)
产生问题:
① 在回表过程中,有可能会出现多次的回表,从而造成磁盘IOPS的升高;(因为是随机IO操作过程)
② 在回表过程中,有可能会出现多次的回表,从而造成磁盘IO量的增加;
解决方法:
① 可以建立联合索引,调整查询条件,使辅助索引过滤出更精细主键ID信息,从而减少回表查询的次数;
比如 查询, select * from t1 where name ='x' and age =19 可以创建 联合索引。
如果查询数据还是很慢,可以多加条件信息, 创建联合索引。 这样回表次数就减少了。
② 可以控制查询信息,实现覆盖索引,辅助索引完全覆盖查询结果;
减少 select * 的使用
③ 优化器算法做调整???(MRR-多路读功能 ICP-索引下推功能 )
构建索引树高度问题分析: (索引树高度越低越好)
影响索引树高度因素:
① 数据行数量会对高度产生影响;(3层BTREE -- 可以实现一般2000万行数据索引的存储-20~30列表)
解决方法:可以拆分表 拆分库 或者实现分布式式存储;
② 索引字段长度过大会对高度产生影响;
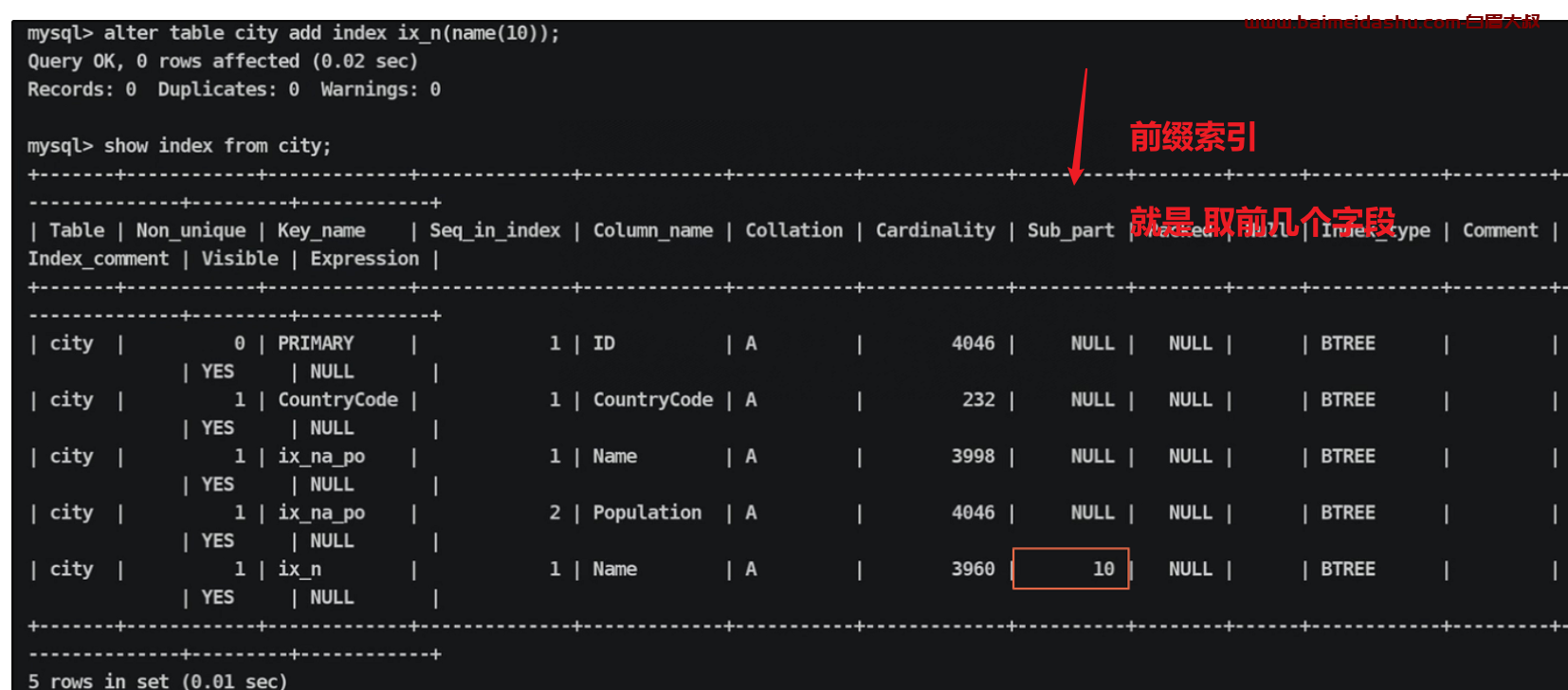
解决方法:利用前缀索引解决问题
③ 数据类型设定会对高度产生影响;
解决方法:列定义时,选择简短合适的数据类型;
数据库索引应用方法
在进行索引操作之前,可以进行一个压力测试,将一个100W数据量的数据库备份数据进行备份恢复:
准备 数据:
mysql: https://url69.ctfile.com/d/253469-56755836-403176?p=2206 (访问密码: 2206)
# 进行测试数据恢复操作:
mysql> source ~/t100w_baimei.sql
# 进行数据库程序服务压测:
mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='baimei' --query="select * from baimei.t100w where k2='VWlm'" engine=innodb --number-of-queries=2000 -uroot -p123456 -h192.168.30.101 -verbose
-- concurrency=100 模拟同时100会话连接;
-- iterations=1 测试执行的迭代次数,代表要在不同并发环境下,各自运行测试多少次
-- create-schema='test' 指定操作的数据库信息;
-- query="select * from test.100w where k2='780P'" 指定压测过程具体执行了什么语句操作
-- number-of-queries=2000 指定一共做了多少次查询,总的测试查询次数(并发客户数×每客户查询次数)
/usr/local/mysql/bin/mysqlslap --defaults-file=/data/3306/my.cnf --concurrency=100 --iterations=1 --create-schema='oldboy' --query="select * from oldboy.t100w where k2='VWlm'" engine=innodb --number-of-queries=2000 -uroot -p123456 -verbose;

进行索引建立优化:
mysql> alter table baimei.t100w add index idx_k2(k2);
在进行压测检查确认:
desc t100w;
show index from t100w;


索引信息的展示形式:
| 序号 | 索引标识 | 解释说明 | |----|---------|--------------------| | 01 | PK(PRI) | 表示为聚簇索引,也可以理解为主键索引 | | 02 | K(MUL) | 表示为辅助索引,也可以理解为一般索引 | | 03 | UK | 表示唯一键索引 |
总结:
创建单列索引方法:
mysql> ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
-- 创建主键索引
mysql> alter table city add index idx_name(name);
-- 创建辅助索引
mysql> ALTER TABLE `table_name` ADD UNIQUE (`column`)
-- 创建唯一键索引
创建联合索引方法:
mysql> alter table city add index ix_na_po(name,population);
创建前缀索引方法:
mysql> alter table city add index ix_n(name(10));
删除索引信息:
# 删除索引信息(一般索引)
alter table 表名 drop index 索引名;
mysql> alter table t100w drop index idx_name;
-- 删除辅助索引
mysql> alter table t100w drop index baimei;
-- 删除联合索引
mysql> alter table t100w drop index id;
-- 删除唯一索引
# 删除索引信息(聚簇索引)
alter table 表名 drop primary key;
mysql> alter table t100w drop primary key;
-- 删除聚簇索引