HBase 参数调优
1.Region 相关参数
hbase.hregion.max.filesize
默认 10G,Region 中任意 HStore 所有文件大小总和大于该值就会进行分裂。实际生产环境中该值不建议太大,也不能太小,太大会导致系统后台执行 compaction 消耗大量系统资源,一定程度上影响业务响应;太小会导致Region 分裂比较频繁,分裂本身其实对业务读写会有一定影响,使单个RegionServer 中存在大量 Region,太多 Region 会消耗大量维护资源,并且在 RegionServer 下线迁移时比较耗时。建议线上设置为 50G~80G 左右。
2.BlockCache 相关参数
BlockCache 相关的参数非常多,不同 BlockCache 策略对应不同的参数,RegionServer 内存在 20G 以内的就选择 LRUBlockCache,大于 20G 的就选择 BucketCache 中的 Offheap 模式。
BucketCache 的 offheap 模配置:
file.block.cache.size:默认 0.4,该值用来设置 LRUBlockCache 的内存大小,0.4 表示 JVM 内存的 40%,当前 HBase 系统默认采用 LRUBlockCache策略,BlockCache 大小和 Memstore 大小均为 JVM 的 40%。但对于BucketCache 策略来讲,Cache 分为了两层,L1 采用 LRUBlockCache,主要存储 HFile 中的元数据 Block,L2 采用 BucketCache,主要存储业务数据Block。因为只用来存储元数据 Block,所以只需要设置很小的 Cache 即可。建议线上设置为 0.05~0.1 左右。
hbase.bucketcache.ioengine:offheap
hbase.bucketcache.size:堆外存大小,设置多大就看自己的物理内存大小了
3.刷写参数
HBase 写入数据时会先写 WAL 日志,再将数据写到写缓存 MemStore中,等写缓存达到一定规模或其他触发条件时会 Flush 刷写到磁盘,生成一个 HFile 文件,这样就将磁盘随机写变成了顺序写,提高了写性能。
随着时间推移,写入的 HFile 会越来越多,读取数据时就会因为要进行多次 io 导致性能降低,因此 HBase 会定期执行 Compaction 操作以合并减少HFile 数量,提升读性能。
有 7 种情况会触发 Flush:
- 当一个 MemStore 大小达到阈值
hbase.hregion.memstore.flush.size ( 默 认 128M ) 时 , 会 触 发MemStore 的刷写,此时不会阻塞写请求。
- 当一个 Region 中所有 MemStore 总大小达到
hbase.hregion.memstore.block.multiplier
hbase.hregion.memstore.flush.size( 默 认 4*128M=512M) 时
会触发 MemStore 的刷写,并阻塞 Region 所有的写请求,此时写数据会出现 RegionTooBusyException 异常。
- 当一个 RegionServer 中所有 MemStore 总大小达到
hbase.regionserver.global.memstore.size.lower.limit* hbase.regionserver.global.memstore.size * hbase_heapsize(低水位阈值,默认 0.95 * 0.4 * RS 堆大小)时,会触发 RegionServer 中内存占用大的 MemStore 的刷写;
达到hbase.regionserver.global.memstore.size * hbase_heapsize ( 高
水位阈值,默认 0.4 * RS 堆大小)时,不仅会触发 Memstore 的刷写,还会阻塞 RegionServer 所有的写请求,直到 Memstore 总大小降到低水位阈值以下。
-
当一个 RegionServer 的 HLog 即 WAL 文件数量达到上限(可通过参数 hbase.regionserver.maxlogs 配置,默认 32)时,也会触发MemStore 的 刷 写 , HBase 会 找 到 最 旧 的 HLog 文 件 对 应 的Region 进行刷写 。
-
当一个 Region 的更新次数达到hbase.regionserver.flush.per.changes(默认 30000000 即 3 千万)时,也会触发 MemStore 的刷写。
-
定期 hbase.regionserver.optionalcacheflushinterval(默认3600000 即一个小时)进行 MemStore 的刷写,确保 MemStore 不会 长 时 间 没 有 持 久 化 。 为 避 免 所 有 的 MemStore 在 同 一 时 间 进 行flush 而导致问题,定期的 flush 操作会有一定时间的随机延时。
-
手动执行 flush 操作,我们可以通过 hbase shell 或 API 对一张表或一个 Region 进行 flush
上面是 Flush 的几个触发条件,5 个和 Flush 有关的重要参数及调整建议:
hbase.hregion.memstore.flush.size
默认值 128M,单个 MemStore 大小超过该阈值就会触发 Flush。如果当前集群 Flush 比较频繁,并且内存资源比较充裕,建议适当调整为 256M。调大的副作用可能是造成宕机时需要分裂的 HLog 数量变多,从而延长故障恢复时间。
hbase.hregion.memstore.block.multiplier
默认值 4,Region 中所有 MemStore 超过单个 MemStore 大小的倍数达到该参数值时,就会阻塞写请求并强制 Flush。一般不建议调整,但对于写入过快且内存充裕的场景,为避免写阻塞,可以适当调整到 5~8。
hbase.regionserver.global.memstore.size
默 认 值 0.4 , RegionServer 中 所 有 MemStore 大 小 总 和 最 多占 RegionServer 堆内存的 40%。这是写缓存的总比例,可以根据实际场景适当调整,且要与 HBase 读缓存参数 hfile.block.cache.size
( 默 认 也 是 0.4 ) 配 合 调 整 。 旧 版 本 参 数 名 称为 hbase.regionserver.global.memstore.upperLimit。
hbase.regionserver.global.memstore.size.lower.limit
默认值 0.95,表示 RegionServer 中所有 MemStore 大小的低水位是 hbase.regionserver.global.memstore.size 的 95%,超过该比例 就 会 强 制 Flush 。 一 般 不 建 议 调 整 。 旧 版 本 参 数 名 称为 hbase.regionserver.global.memstore.lowerLimit。
hbase.regionserver.optionalcacheflushinterval
默 认 值 3600000 ( 即 1 小 时 ) , HBase 定 期 Flush 所 有MemStore 的时间间隔。一般建议调大,比如 10 小时,因为很多场景下 1 小时 Flush 一次会产生很多小文件,一方面导致 Flush 比较频繁,另一方面导致小文件很多,影响随机读性能,因此建议设置较大值。
4.合并相关参数
HBase 会定期执行 Compaction 合并 HFile,提升读性能,其实就是以短时间内的 io 消耗,换取相对稳定的读取性能。Compaction 类型分为两种:Minor Compaction 与 Major Compaction,可以称为小合并、大合并,简单示意图:
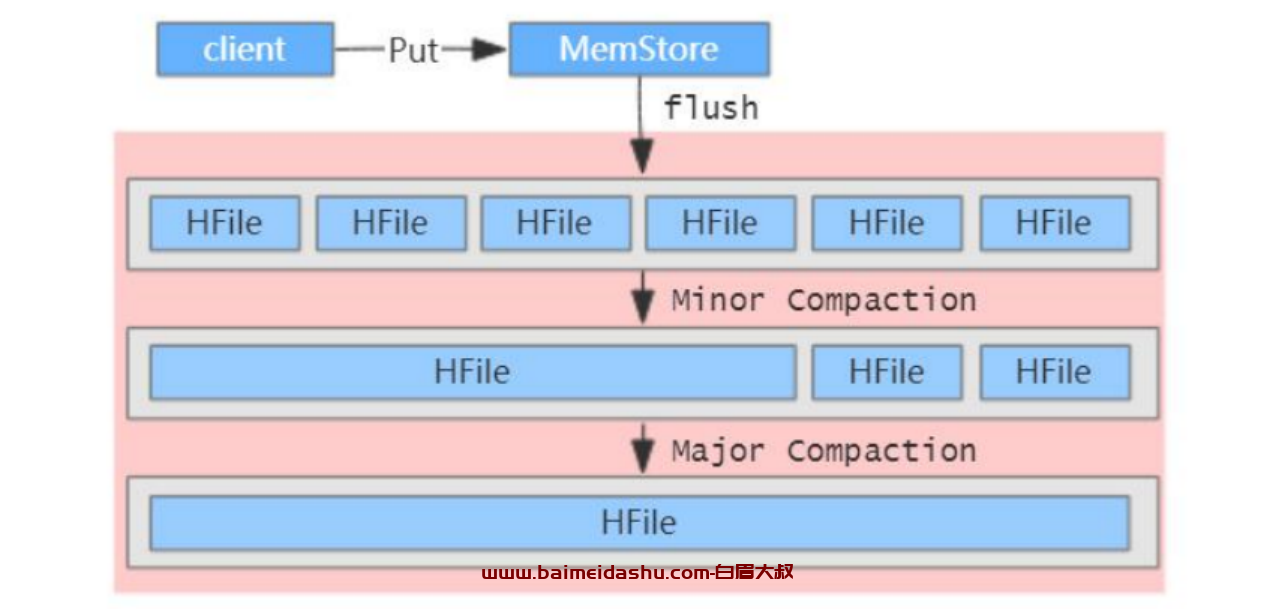
Minor Compaction 是指选取一些小的、相邻的 HFile 将他们合并成一个更大的 HFile,Minor Compaction 会删除选取 HFile 中的 TTL 过期数据。
Major Compaction 是 指 将 一 个 Store 中 所 有 的 HFile 合 并成一个 HFile,这个过程会清理三类没有意义的数据:被删除的数据(打了 Delete 标记的数据)、TTL 过期数据、版本号超过设定版本
号的数据。另外,一般情况下,Major Compaction 时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此,生产环境下通常关闭自动触发 Major Compaction 功能,改为手动在业务低峰期触发。
Compaction 触发时机
HBase 会在三种情况下检查是否要触发 Compaction,分别是MemStore Flush、后台线程周期性检查、手动触发。
- MemStore Flush:
可以说 Compaction 的根源就在于 Flush,MemStore 达到一定阈值或触发条件就会执行 Flush 操作,在磁盘上生成 HFile 文件,正是因为 HFile 文件越来越多才需要 Compact。
HBase 每次 Flush 之后,都会判断是否要进行 Compaction,一旦满足 Minor Compaction 或 Major Compaction 的条件便会触发执行。
- 后台线程周期性检查:
后台线程 CompactionChecker 会定期检查 是 否 需 要 执 行 Compaction , 检 查 周 期 为hbase.server.thread.wakefrequency *
hbase.server.compactchecker.interval.multiplier , 这 里 主 要 考 虑的 是 一 段 时 间 内 没 有 写 入 仍 然 需 要 做 Compact 检 查 。 其 中 参 数hbase.server.thread.wakefrequency 默 认 值 10000 即 10s , 是
HBase 服 务 端 线 程 唤 醒 时 间 间 隔 , 用 于 LogRoller 、MemStoreFlusher 等的周期性检查;参数
hbase.server.compactchecker.interval.multiplier 默 认 值 1000 ,是 Compaction 操作周期性检查乘数因子,10 * 1000 s 时间上约等于 2hrs, 46mins, 40sec。
3)手动触发:通过 HBase Shell、Master UI 界面或 HBase API 等任 一 种 方 式 执 行 compact、 major_compact 等 命 令 , 会 立 即 触 发Compaction
Compaction 核心参数
1)hbase.hstore.compaction.min
默认值 3,一个 Store 中 HFile 文件数量超过该阈值就会触发一次 MinorCompaction,这里称该参数为 minFilesToCompact。一般不建议调小,重写场景下可以调大该参数,比如 5~10 之间。老版本参数名称为
hbase.hstore.compactionthreshold。
2)hbase.hstore.compaction.max
默认值 10,一次 Minor Compaction 最多合并的 HFile 文件数量,这里称该参数为 maxFilesToCompact。这个参数也控制着一次压缩的耗时。一般不建议调整,但如果上一个参数调整了,该参数也应该相应调整,一般设为 minFilesToCompact 的 2~3 倍。
3)hbase.regionserver.thread.compaction.throttle
评估单个 compaction 为 small 或者 large 的判断依据。为了防止 largecompaction 长时间执行阻塞其他 small compaction,hbase 将这两种compaction 进行了分离处理,每种 compaction 会分配独立的线程池
HBase RegionServer 内部设计了两个线程池 large compactions 与 smallcompactions,用来分离处理 Compaction 操作,该参数就是控制一个Compaction 交由哪一个线程池处理,默认值是 2 * maxFilesToCompact *hbase.hregion.memstore.flush.size(默认 2*10*128M=2560M 即 2.5G),建议不调整或稍微调大
4)hbase.regionserver.thread.compaction.large/small
默认值 1,表示 large compactions 与 small compactions 线程池的大小。一般建议调整到 2~5,不建议再调太大比如 10,否则可能会消费过多的服务端资源造成不良影响。
5)hbase.hstore.blockingStoreFiles
默认值 10,表示一个 Store 中 HFile 文件数量达到该值就会阻塞写入,等待 Compaction 的完成。一般建议调大点,比如设置为 100,避免出现阻塞更新的情况,
阻塞日志如下:
too many store files; delaying flush up to 90000ms
生产环境建议认真根据实际业务量做好集群规模评估,如果小集群遇到了持续
写入过快的场景,合理扩展集群也非常重要。
6、hbase.hregion.majorcompaction
默认值 604800000 ms 即 7 天,这是 Major Compaction 周期性触发执行
的时间间隔。通常 Major Compaction 持续时间较长、资源消耗较大,一般
设为 0,表示关闭自动触发,建议在业务低峰期时手动执行。
5.HLog 相关参数
1)hbase.regionserver.maxlogs
默认为 32,region flush 的触发条件之一,wal 日志文件总数超过该阈值就会强制执行 flush 操作。该默认值对于很多集群来说太小,生产线上具体设置参考 HBASE-14951
2)hbase.regionserver.hlog.splitlog.writer.threads
默认为 3,regionserver 恢复数据时日志按照 region 切分之后写入 buffer,重新写入 hdfs 的线程数。生产环境因为 region 个数普遍较多,为了加速数据恢复,建议设置为 10。
6.Call Queue 相关参数
1)hbase.regionserver.handler.count
默认为 30,服务器端用来处理用户请求的线程数。生产线上通常需要将该值调
到 100~200
解读:response time = queue time + service time,用户关心的请求响应时间由两部分构成,优化系统需要经常关注 queue time,如果用户请求排队时间很长,首要关注的问题就是hbase.regionserver.handler.count 是否没有调整。
2)hbase.ipc.server.callqueue.handler.factor
默认为 0,服务器端设置队列个数,假如该值为 0.1,那么服务器就会设置handler.count * 0.1 = 30 * 0.1 = 3 个队列。
3)hbase.ipc.server.callqueue.read.ratio
默认为 0,服务器端设置读写业务分别占用的队列百分比以及 handler 百分比。假如该值为 0.5,表示读写各占一半队列,同时各占一半 handler
7.其他参数
1)hbase.online.schema.update.enable
默认为 false,表示更新表 schema 的时候不再需要先 disable 再 enable,直接在线更新。该参数在 HBase 2.0 之后将会默认为 true。生产线上建议设置为true。
2)hbase.quota.enabled
默认为 false,表示是否开启 quota 功能,quota 功能主要用来限制用户/表的QPS,起到限流作用。生产线上建议设置为 true。
3)hbase.snapshot.enabled
默认为 false,表示是否开启 snapshot 功能,snapshot 功能主要用来备份HBase 数据。生产线上建议设置为 true。
4)zookeeper.session.timeout
默认 180s,表示 zookeeper 客户端与服务器端 session 超时时间,超时之后RegionServer 将会被踢出集群。
解读:有两点需要重点关注,其一是该值需要与 Zookeeper 服务器端 session相关参数一同设置才会生效,一味的将该值增大而不修改 ZK 服务端参数,可能并不会实际生效。其二是通常情况下离线集群可以将该值设置较大,在线业务需要根据业务对延迟的容忍度考虑设置。
5)hbase.zookeeper.useMulti
默认为 false,表示是否开启 zookeeper 的 multi-update 功能,该功能在某些场景下可以加速批量请求完成,而且可以有效防止部分异常问题。生产线上建议设置为 true。注意设置为 true 的前提是 Zookeeper 服务端的版本在 3.4以上,否则会出现 zk 客户端夯住的情况.