在 Linux 下实现高精度延时,网上所能找到的大部分方法只能实现 50us 左右的延时精度。今天让我们来看下嘉友创信息科技的董文会是如何解决这个问题的,将延时精度提升到 10us。{#profileBt}
问题描述
最近在开发一个项目,需要用到高精度的延时机制,设计需求是 1000us 周期下,误差不能超过 1%(10us)。
由于项目硬件方案是用英特尔的 x86 处理器,熟悉 Linux 硬件的人都知道这个很难实现。当时评估方案时候有些草率,直接采用了 "PREEMPT_RT 补丁+内核 hrtimer+信号通知" 的方式来评估。当时验证的结果也很满意,于是兴冲冲的告诉领导说方案可行,殊不知自己挖了一个巨大的坑......
实际项目开始的时候,发现这个方案根本行不通,有两个原因:
- 信号通知只能通知到进程,而目前移植的方案无法做到被通知的进程中无其他线程。这样高频的信号发过来,其他线程基本上都会被干掉。(补充说明:这里特指的是内核驱动通知到应用层,在用户层中是有专门的函数可以通知不同线程的。并且这个问题经过研究,可以通过设置线程的 sigmask 来解决,但是依旧无法改变方案行不通的结论)
- 这也是主要原因,项目中需要用的 Ethercat 的同步周期虽然可以在程序开始时固定,但是实际运行时的运行周期是需要动态调整的,调整范围在 5us 以内。这样一来,动态调整 hrtimer 的开销就变得无法忽略了,换句话说,我们需要的是一个延时机制,而不是定时器。
所以这个方案被否定了。
解决思路
既然信号方式不行,那只能通过其他手段来分析。总结下来我大致进行了如下的尝试:
1、sleep方案的确定
尝试过 usleep、nanosleep、clock_nanosleep、cond_timedwait、select 等,最终确定用 clock_nanosleep,选它的原因并不是因为它支持 ns 级别的精度 。因为经过测试发现,上述几个调用在周期小于 10000us 的情况下,精度都差不多,误差主要都来自于上下文切换的开销 。选它的主要原因是因为它支持 TIME_ABSTIME 选项,即支持绝对时间。这里举个简单的例子,解释一下为什么要用绝对时间:
while(1){
do_work();
sleep(1);
do_post();
}
假设上面这个循环,我们目的是让 do_post的执行以 1s 的周期执行一次,但是实际上,不可能是绝对的 1s,因为 sleep() 只能延时相对时间,而目前这个循环的实际周期是 do_work 的开销 + sleep(1) 的时间 。所以这种开销放在我们需求的场景中,就变得无法忽视了。而用 clock_nanosleep 的好处就是一方面它可以选择时钟源,其次就是它支持绝对时间唤醒,这样我在每次 do_work 之前都设置一下 clock_nanosleep下一次唤醒 时的绝对时间,那么 clock_nanosleep 实际执行的时间其实就会减去 do_work 的开销,相当于是闹钟的概念。
2、改用实时线程
将重要任务的线程改成实时线程,调度策略改成 FIFO,优先级设到最高,减少被抢占的可能性。
3、设置线程的亲和性
对应用下所有的线程进行规划,根据负载情况将几个负载比较重的任务线程分别绑定到不同的 CPU 核上,这样减少切换 CPU 带来的开销。
4、减少不必要的sleep调用
由于很多任务都存在 sleep 调用,我用 strace 命令分析了整个系统中应用 sleep 调用的比例,高达 98%,这种高频次休眠+唤醒带来的开销势必是不可忽略的 。所以我将 main 循环中的 sleep改成了循环等待信号量的方式 ,因为 pthread 库中信号量的等待使用了 futex,它使得唤醒线程的开销会小很多。其他地方的 sleep 也尽可能的优化掉。这个效果其实比较明显,能差不多减少 20us 的误差。
5、绝招
从现有应用中剥离出最小任务,减少所有外界任务的影响。
经过上述五点,1000us 的误差从一开始的 ±100us,控制到了 ±40us。但是这还远远不够......
黔驴技穷的我开始漫长的搜索研究中......
这期间也发现了一些奇怪的现象,比如下面这张图。
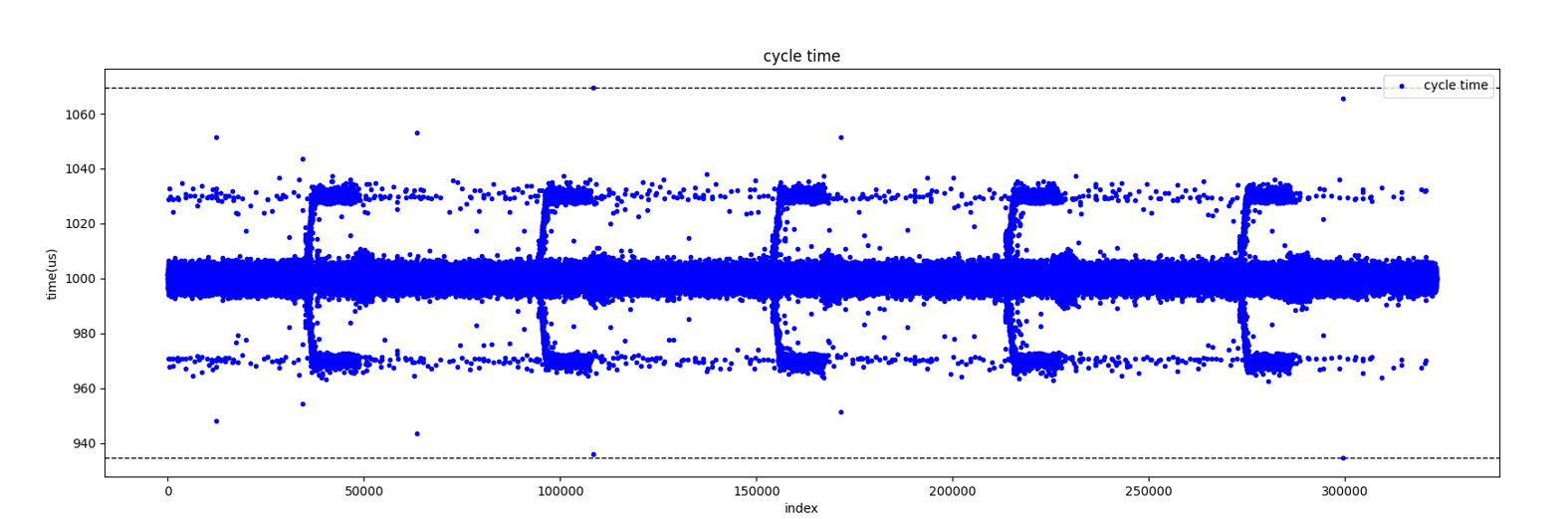
图片是用 Python 对抓包工具的数据进行分析生成的,参考性不用质疑。纵轴代表实际这个周期所耗费的时间。可以发现很有意思的现象:
- 每隔一定周期,会集中出现规模的误差抖动
- 误差不是正态分布,而是频繁出现在 ±30us 左右的地方
- 每次产生较大的误差时,下个周期一定会出现一次反向的误差,而且幅度大致相同(这点从图上看不出来,通过其他手段分析的)。
简单描述一下就是假设这个周期的执行时间是 980us,那下个周期的执行时间一定会在 1020us 左右。
第 1 点和第 2 点可以经过上面的 4 条优化措施消除,第 3 点没有找到非常有效的手段,我的理解可能内核对这种误差是知晓的并且有意在弥补,如果有知道相关背后原理的大神欢迎分享一下。
针对这个第三点奇怪的现象我也尝试做了手动的干预,比如设一个阈值,当实际程序执行的误差大于这个阈值时,我就在设置下一个周期的唤醒时间时,手动减去这个误差,但是运行效果却大跌眼镜,更差了......
柳暗花明
在尝试了 200 多次参数调整,被这个问题卡了一个多礼拜之后,偶然发现了一篇戴尔的技术文档《Controlling Processor C-State Usage in Linux》,受到这篇文章的启发,终于解决了这个难题。
随后经过一番针对性的查找终于摸清了来龙去脉:
原来英特尔的 CPU 为了节能,有很多功耗模式,简称 C-state。
|--------|-----------|--------------------------------------------------|------------------------------------------------------| | 模式 | 名字 | 作用 | CPU | | C0 | 操作状态 | CPU完全打开 | 所有CPU | | C1 | 停止 | 通过软件停止 CPU 内部主时钟;总线接口单元和 APIC 仍然保持全速运行 | 486DX4及以上 | | C1E | 增强型停止 | 通过软件停止 CPU 内部主时钟并降低 CPU 电压;总线接口单元和 APIC 仍然保持全速运行 | 所有socket 775 CPU | | C1E | --- | 停止所有CPU内部时钟 | Turion 64、65-nm Athlon X2和Phenom CPU | | C2 | 停止授予 | 通过硬件停止 CPU 内部主时钟;总线接口单元和 APIC 仍然保持全速运行 | 486DX4及以上 | | C2 | 停止时钟 | 通过硬件停止CPU内部和外部时钟 | 仅限486DX4、Pentium、Pentium MMX、K5、K6、K6-2、K6-III | | C2E | 扩展的停止授予 | 通过硬件停止 CPU 内部主时钟并降低 CPU 电压;总线接口单元和 APIC 仍然保持全速运行 | Core 2 Duo和更高版本(仅限Intel) | | C3 | 睡眠 | 停止所有CPU内部时钟 | Pentium II、Athlon以上支持,但Core 2 Duo E4000和E6000上不支持 | | C3 | 深度睡眠 | 停止所有CPU内部和外部时钟 | Pentium II以上支持,但Core 2 Duo E4000、E6000和Turion 64上不支持 | | C3 | AltVID | 停止所有CPU内部时钟和降低CPU电压 | AMD Turion 64 | | C4 | 更深入的睡眠 | 降低CPU电压 | Pentium M以上支持,但Core 2 Duo E4000、E6000和Turion 64上不支持 | | C4E/C5 | 增强的更深入的睡眠 | 大幅降低CPU电压并关闭内存高速缓存 | Core Solo、Core Duo和45-nm移动版Core 2 Duo支持 | | C6 | 深度电源关闭 | 将 CPU 内部电压降低至任何值,包括 0 V | 仅45-nm移动版Core 2 Duo支持 |
图表来自 DELL
当程序运行的时候,CPU 是在 C0 状态,但是一旦操作系统进入休眠,CPU 就会用 Halt 指令切换到 C1 或者 C1E 模式,这个模式下操作系统如果进行唤醒,那么上下文切换的开销就会变大!
这个选项按道理 BIOS 是可以关掉的,但是坑的地方就在于版本**相对较新的 Linux 内核版本,默认是开启这个状态的,并且是无视 BIOS 设置的!**这就很坑了!

针对性查找之后,发现网上也有网友测试,2.6 版本的内核不会默认开启这个,但是 3.2 版本的内核就会开启,而且对比测试发现,这两个版本内核在相同硬件的情况下,上下文切换开销可以相差 10 倍, 前者是 4us,后者是 40-60us。
解决办法
1、永久修改
可以修改 Linux 的引导参数,修改 /etc/default/grub 文件中的 GRUB_CMDLINE_LINUX_DEFAULT 选项,改成下面的内容:
intel_idle.max_cstate=0 processor.max_cstate=0 idle=poll
然后使用 update-grub 命令使参数生效,重启即可。
2、动态修改
可以通过向 /dev/cpu_dma_latency 这个文件中写值,来调整 C1/C1E 模式下上下文切换的开销。我选择写 0 直接关闭。当然你也可以选择写一个数值,这个数值就代表上下文切换的开销,单位是 us。比如你写 1,那么就是设置开销为 1us。当然这个值是有范围的,这个范围在 /sys/devices/system/cpu/cpuX/cpuidle/stateY/latency 文件中可以查到,X 代表具体哪个核,Y 代表对应的 idle_state。
至此,这个性能问题就得到了完美的解决,目前稳定测试的性能如下图所示:

实现了 x86 Linux 下高精度延时 1000us 精确延时,精度 10us。
本文作者董文会,经授权转载。
题图来源:网络。





