"""
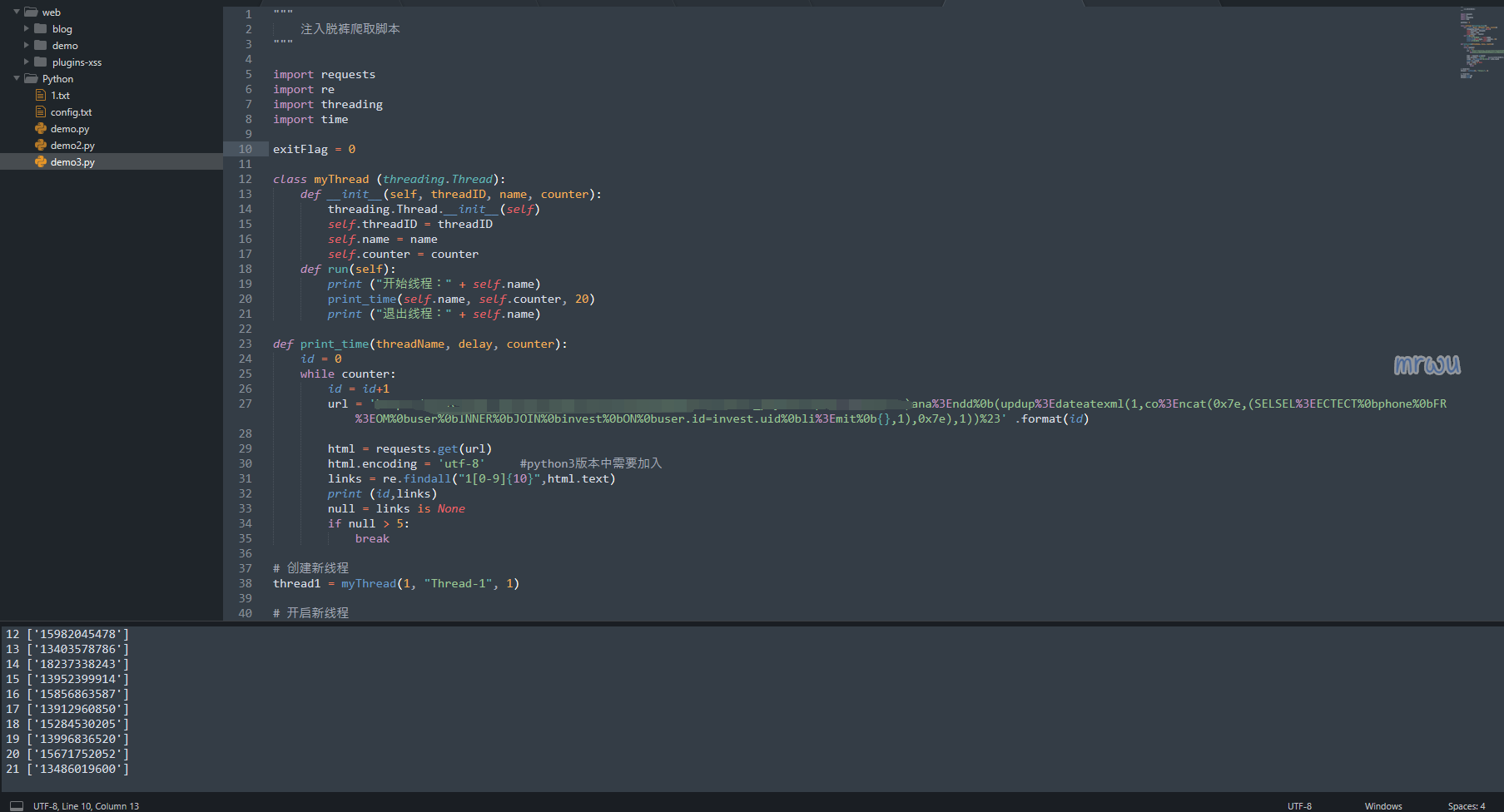
注入脱裤爬取脚本
"""
import requests
import re
import threading
import time
class myThread (threading.Thread):
def init(self, threadID, name, counter):
threading.Thread.init(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 3)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
id = 0
cs = 0
while counter:
id = id+1
url = 'https://www.mrwu.red/?id={}' .format(id)
` html = requests.get(url)
html.encoding = 'utf-8' #python3版本中需要加入
links = re.findall("1[0-9]{10}",html.text)
print (id,links)
#空三次停止
if not links:
cs = cs+1
if cs > 3:
break
`
创建新线程
thread1 = myThread(1, "Thread-1", 1)
开启新线程
thread1.start()
thread1.join()
最近开始学习 Python 了,一开始觉得真的好难好难,七秒记忆的我真的很难记住那么多内置库和函数;
经过几天的摸索,终于算是成功入手了,虽然还是很多不会的,但是至少学会了如何去百度,去搜索自己要的东西,能搜索到资料,那就能慢慢写和改 Python 了;
这算是一个不错的开始,写篇文章记录一下 [aru_17]
小笔记一则:
request.urlopen 请求方式总会出各种各样的问题,比如源码格式、需要用异常块等
requests.get 这个目前感觉没啥毛病,感觉挺好用,以后先一直用着