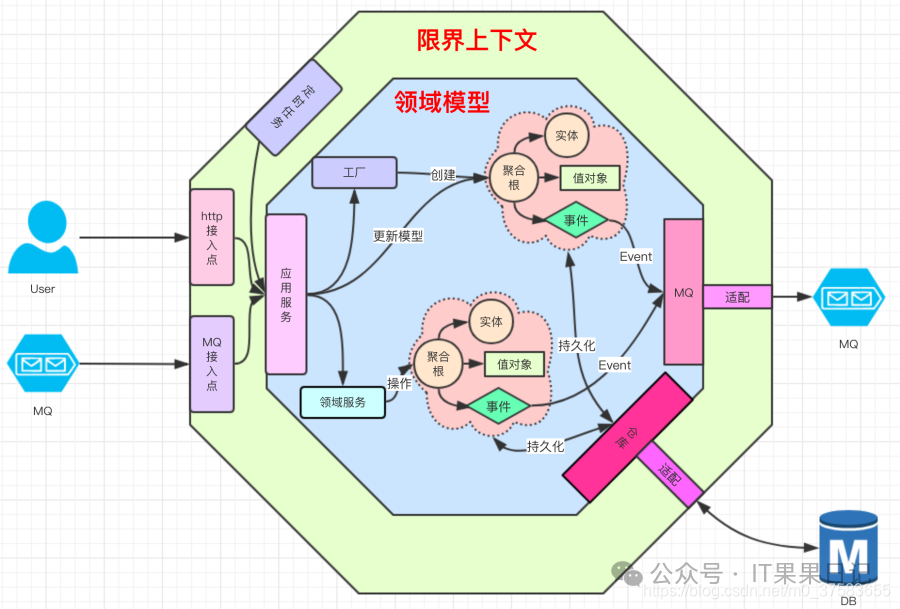
1.简介
领域驱动设计是一个应对复杂应用系统的设计方法,它通过一系列从粗到细粒度的逻辑边界划分,从而创建系列的高内聚的领域模型,并使用与领域模型一致性的代码实现。最终,高复杂度的应用系统被划分为一个个小的低复杂度服务/功能/任务。后续文章不按照常见的战略设计+战术设计实现,只按照自己的理解来展开。
2.基本概念
领域驱动设计核心是利用业务概念创建领域模型对象最终完成系统设计,而不是数据存储出发设计系统。业务概念的来源主要是用户故事中各种业务术语。下述概念的粒度由粗到细,例如一个上下文边界中包含一个及以上的应用服务。
2.1 上下文边界
在有界上下文中,领域对象才会具有确定的语义,保证没有二义性。划分好有界上下文,就可以知道领域对象应该放在哪个上下文中实现。实际上,微服务的拆分和设计是基于有界上下文,一个上下文对应一个微服务,但是防止过度拆分带来的维护成本激增,往往会将多个上下文边界作为一个服务管理。例如,在电商领域,一个"商品"在不同的上下文中可能有不同的含义和属性。在销售上下文中,它可能包括价格、促销信息等属性;而在库存管理的上下文中,它可能包含库存数量、存储位置等属性。通过定义这两个不同的上下文边界,我们可以清晰地区分"销售商品"和"库存商品",避免因概念混淆而导致的业务逻辑错误。
2.1.1 应用服务
应用服务通常以业务用例为粒度,每个服务对应一个独立的业务用例。应用服务主要负责对服务内部的领域服务编排。 假设我们有一个电子商务平台,该平台有一个功能是"用户提交订单"。这个业务用例可以由一个名为OrderSubmissionService的应用服务来实现。这个服务会处理用户提交订单的整个流程,包括验证用户输入的数据、创建订单、计算订单总额、检查库存、记录交易日志等。在这个过程中,OrderSubmissionService会调用领域层中的多个聚合根和实体来完成这些任务,例如调用Order聚合根的placeOrder方法,以及Product实体的decrementStock方法。
2.1.1.1 聚合
聚合由一个聚合根、多个实体、多个领域服务、多个领域事件以及一个仓储实现,这些对象在业务上高度关联,并且作为一个整体被统一管理,具有强一致性。聚合内实现高内聚的业务逻辑,如果特别复杂,则它的代码可以独立拆分为微服务。
聚合根
聚合根也是一个实体,但是封装了所在聚合内的所有领域对象的管理,并维护聚合内的强一致性。 聚合软件包的根目录,可以根据实际项目的聚合名称命名,比如权限聚合。在聚合内定义聚合根、实体和值对象以及领域服务之间的关系和边界。
领域事件
领域内产生的事件。可以关注用户故事中,"当...,则要...."这种描述。
领域服务
负责编排聚合内实体和值对象,组合出一段业务逻辑,一个聚合可以只有一个领域服务类,如果比较复杂再考虑拆分。
仓储
一个聚合对应一个仓储,负责聚合的查询和持久化。
实体
实体是最底层的领域对象之一,主要特征是:
-
具有唯一标识符,各种属性变更后标识符不变
-
包含属性和方法,使用充血模型
值对象
值对象也是最底层的领域对象之一,主要特征是:
-
不可变
-
通过对象属性值来区分而不是标识符
3.工程实现(or 分层架构)
服务内部代码的组织使用分层架构来组织,主要分为用户接入层、应用层、领域层、基础设施层来作为上述领域对象的载体。
3.1 用户接入层
负责将用户输入转换为领域对象,并调用应用服务产生结果,将结果转换为展现数据。
dto
存放web接口/soa接口的入参和出参
assembler
存放dto与领域对象的转换逻辑
facade
存放应用服务的编排代码
3.2 应用层
event
负责事件的发布和订阅
publish
subscribe
service
负责存放应用服务的业务,使用xxxCommand\xxxQuery\xxxEvent明确意图。
external
负责存放外部服务的接口
3.3 领域层
service
存放领域服务的逻辑,调用
entity
存放实体
valueObject
存放值对象
event
存放领域事件
仓储
存放仓储接口
3.4 基础设施层
负责存放rpc调用、mp配置以及事件订阅/发布接口的实现、仓储接口的数据库的实现以及缓存的实现等。
4 实践
背景
用例1:在一个设计工具中,家装设计师可以打开方案,在方案中选中想要生成台面的柜子,然后选择需要生成的台面材质样式,然后点击一键生成台面。同时,台面材质和前后挡水样式之间的约束关系有单独的配置。生成的台面块要能够恰好覆盖柜子表面。台面块和墙和柜子重叠的部分会生成后挡水,其余边生成前挡水。如果用户要求前挡水要内含,则柜子表面的轮廓要包含前挡水;如果是外扩,则前挡水可以在柜子外部。多个台面如果相邻等高,则需要合并一个台面。台面块是平面板件模型,而前后挡水则是扫掠模型。柜子和墙形成的闭合缝隙,如果面积小于100平米厘米则需要扩展台面,补上缝隙。
用例2: 生成好的台面可以根据用户的要求切割成多个台面块和多段前挡水和后挡水。
用例3: 用户选中方案中的柜子,进入脚线生成环境,选择脚线轮廓和材质样式以及脚线高度,可以使用设计工具一键生成脚线,脚线是扫掠模型。同时,首尾相接的多段脚线可以合并为一段。
任务
-
提取领域模型,并划分上下文,并再用上下文重新组织领域模型
-
完成代码的设计和组织
行动 && 结果
-
提取各种业务名词、行为还有事件 业务术语: 台面、台面块、前挡水、后挡水、内含外扩、户型、方案、墙、台面合并、台面补缝、台面切割、脚线、柜子、柜子上表面、柜子下表面、扫掠模型、放样模型、材质、轮廓样式。
-
划分上下文
-
柜子模型、扫掠模型、放样模型
-
方案
-
户型
-
柜子、柜子上表面、柜子下表面
-
脚线、脚线高度、脚线材质、脚线样式、脚线扫掠
-
台面、台面块、前挡水、后挡水、台面厚度、内含外扩、台面合并、台面补缝、台面切割、前挡水样式、台面材质、前挡水材质、后挡水材质、后挡水样式、前挡水扫掠、后挡水扫掠、台面块板件
-
台面上下文边界(核心)
-
脚线上下文边界(核心)
-
柜子上下文边界(支撑)
-
户型上下文边界(通用)
-
方案上下文边界(通用)
-
建模上下文边界(通用)
-
-
提取隐藏概念以及上下文
对上述的部分行为详细展开,比如台面合并:台面合并是指两个台面材质、样式一致、厚度一致且几何图形做交集,因此还有几何的上下文,包含常用的3维长方形、3维长方体、3维多边形、特殊的柱体(三维多边形沿着面的法向量拉伸形成)以及相应的相交/差/并集操作等。
同时,考虑到维护性,两个核心上下文分别使用单独的服务作为载体会导致维护成本比较高,尤其是脚线业务逻辑简单,因此考虑放在使用同一个服务作为载体。同时作为支撑脚线和台面的柜子、扫掠、板件则作为原子领域概念,组合构建出更高层的领域对象。 -
识别领域对象并分层
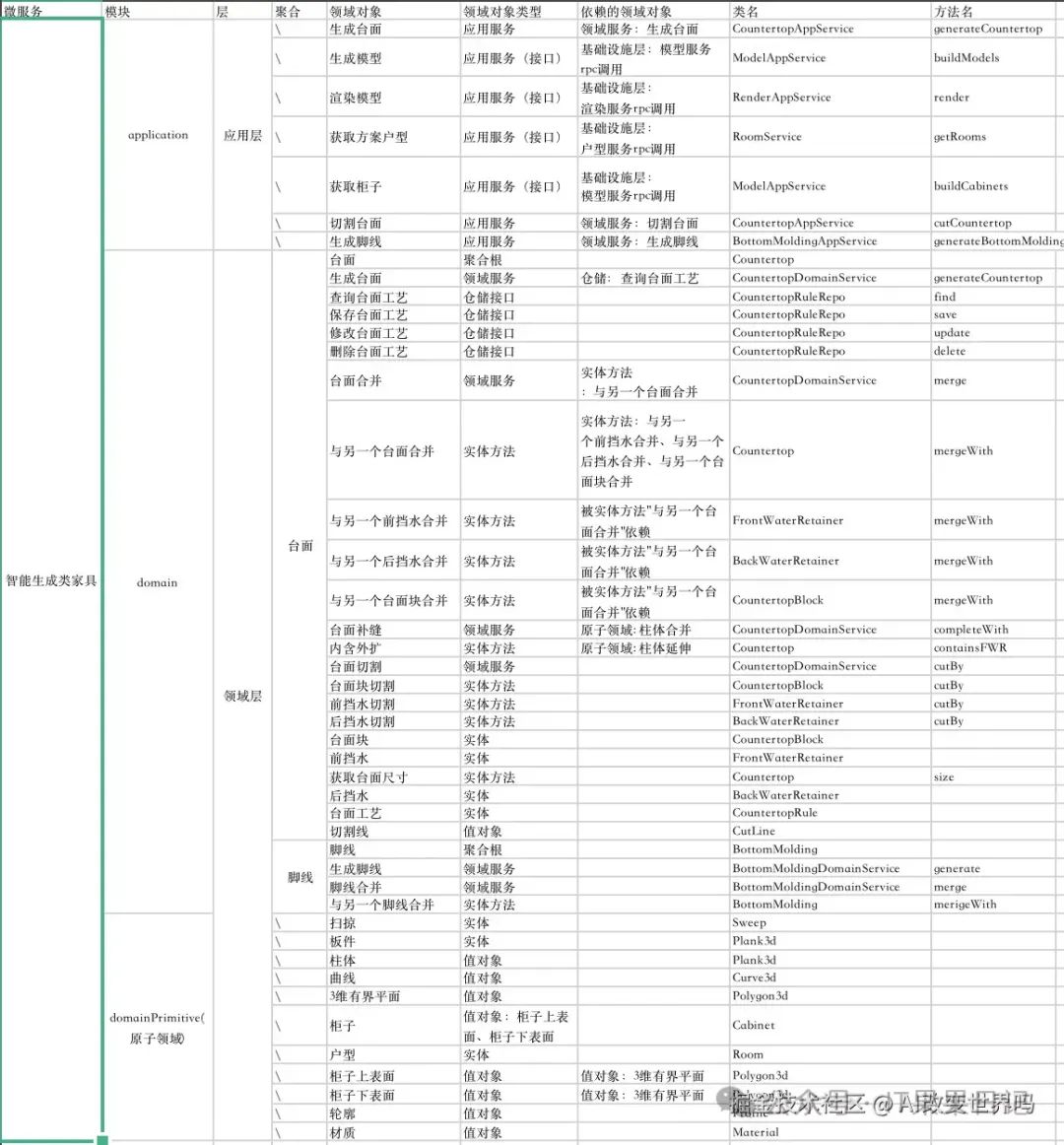 image.png
image.png
-
基础设施层
-
数据配置+mapper.xml以及mapper以及接口实现
-
redis配置+caffeine缓存实现
-
rpc client调用以及dto与do转换以及限流和熔断机制
-
动态配置实现
-
线程池实现
-
-
代码结构(部分)
目录:-
mq
-
storage
-
rpc
-
rocketMQ
-
数据库A
-
数据库B
-
config (数据源配置以及事务管理器配置)
-
po
-
assembler
-
mysql
-
redis
-
dto
-
assembler
-
facade(包含rpc的各种调用,渲染、模型以及户型服务的实际调用)
-
util
-
entity
-
valueObject
-
Cabinet
-
Room
-
Sweep
-
Plank3d
-
Polygon3d
-
Curve3d
-
countertop
-
bottomMolding
-
CountertopRuleRepo
-
Countertop
-
CountertopBlock
-
CountertopDomainService
-
service
-
entity
-
repo
-
valueObject
-
event(空的)
-
exception
-
switch (业务开关,接口与实现分离)
-
service
-
event (没用到可删除)
-
ModelAppService
-
RenderAppService
-
RoomAppService
-
CountertopAppService
-
BottomMoldingAppService
-
extern
-
subscribet
-
publish
-
interface
-
controller
-
facade
-
dto
-
assembler
-
CountertopController
-
BottomMoldingController
-
web层
-
application (依赖领域层)
-
domain
-
domain-primitive
-
infras(依赖领域层的接口)
-
基础设施层部分代码展示: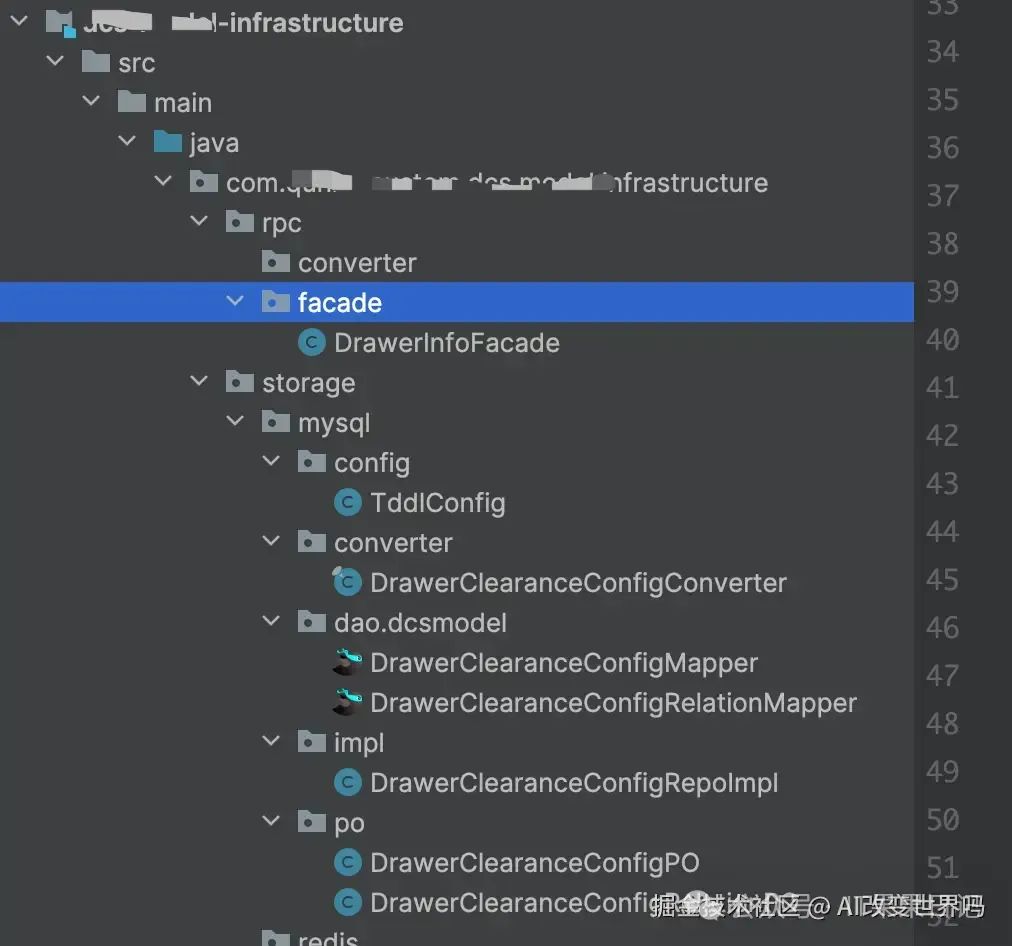 image.png
image.png
@Repository
public class DrawerClearanceConfigRepoImpl implements DrawerClearanceConfigRepo {
@Resource
private DrawerClearanceConfigMapper drawerClearanceConfigMapper;
@Resource
private DrawerClearanceConfigRelationMapper drawerClearanceConfigRelationMapper;
/**
* 通过抽屉ID列表查找配置。
*
* @param drawerId 抽屉的唯一标识ID
* @return 一个映射,将抽屉ID映射到它们的配置
*/
@Override
@Cacheable(value = "drawerClearanceConfigs", key = "#rootAccountId + '-' + #drawerId")
public DrawerClearanceConfig findConfigsByDrawerId(Long drawerId, long rootAccountId) {
final List<DrawerClearanceConfigRelationPO> drawerClearanceConfigRelationPOList
= drawerClearanceConfigRelationMapper.selectByDrawerBgIds(Collections.singletonList(drawerId), rootAccountId);
if (CollectionUtils.isEmpty(drawerClearanceConfigRelationPOList)) {
return null;
}
DrawerClearanceConfigRelationPO drawerClearanceConfigRelationPO = drawerClearanceConfigRelationPOList.get(0);
DrawerClearanceConfigPO drawerClearanceConfigPO = drawerClearanceConfigMapper.selectById(drawerClearanceConfigRelationPO.getConfigId(), rootAccountId);
return DrawerClearanceConfigConverter.toDrawerClearanceConfig(drawerClearanceConfigPO);
}
/**
* 通过配置ID删除一个配置。
*
* @param configId 配置的唯一标识ID
*/
@Override
@Transactional(transactionManager = "dcsModelTransactionManager", rollbackFor = {Exception.class}, propagation = Propagation.REQUIRED)
public void removeConfigById(long configId, long rootAccountId) {
LOGGER.message("removeConfigById").with("configId", configId).with("rootAccountId", rootAccountId).info();
drawerClearanceConfigMapper.deleteById(configId, rootAccountId);
drawerClearanceConfigRelationMapper.deleteByConfigId(configId, rootAccountId);
}
}
5 一些BP
-
聚合之间的关联要使用id
-
聚合是某个实体
-
事务的粒度就是一个聚合,多个聚合之间只能通过领域事件保证最终一致性
-
聚合设计要尽量小,如果一个实体不是根实体,但同时需要被外界直接访问到,那么这个实体不应该在这个聚合中,应该独立成新的聚合。
-
聚合根作为外界访问的入口
-
值对象和实体的equal和hash方法需要重写
-
常见的insert、select、update、delete都属于SQL语法,使用这几个词相当于和DB底层实现做了绑定。相反,我们应该把Repository当成一个中性的类似Collection的接口,使用语法如find、save、remove。
-
让Domain Service与Repository打交道,而不是让领域模型Entity与Repository打交道
原文:https://juejin.cn/post/7404739357083697188
作者:AI改变世界吗