Important:本文章原始发布地址为微信公众号:时光历程,点击 链接 访问原文。
大家好,平时我们想提取图片的文字,可能用微信自带的提取就很方便了,但是我们是否可以自己自建一个这样的服务呢?今天给大家分享一下。
特性
- 中文识别
快速高识别率 - 文字检测
支持一定角度的旋转 - 并发请求
由于模型本身不支持并发,但通过tornado多进程的方式,能支持一定数量的并发请求。
具体并发数取决于机器的配置。
最低配置要求
- CPU: 1核
- 内存: 2G
- SWAP: 2G
运行平台
- ✔ Python 3.6+
- ✔ Ubuntu 16.04
- ✔ ️Ubuntu 18.04
- ✔ CentOS 7
- ✔ Docker
搭建trwebocr
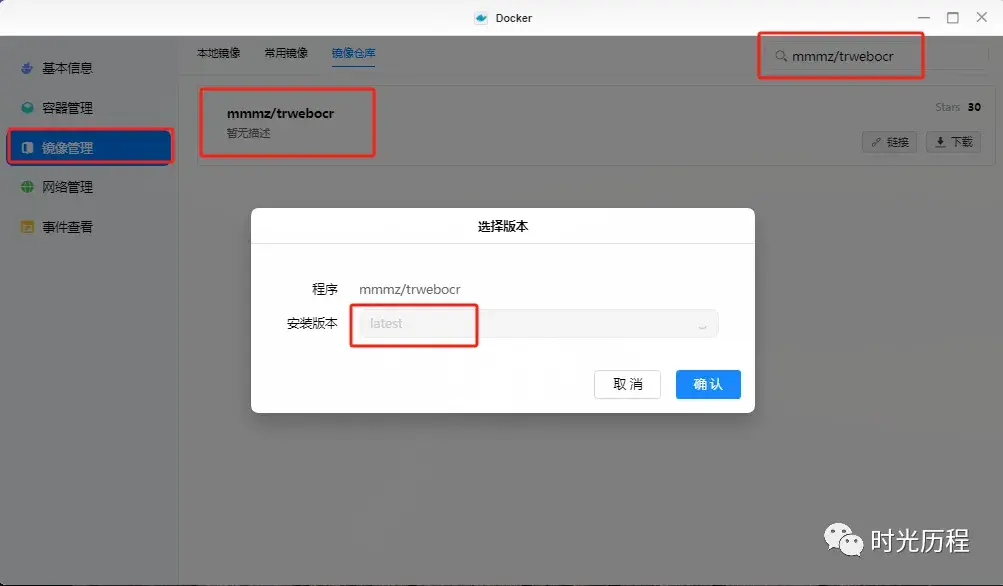
绿联 DX4600 为例,首先我们打开 Docker 管理器,进入镜像管理,然后在镜像仓库中搜索 mmmz/trwebocr,选择 latest 版本并下载。
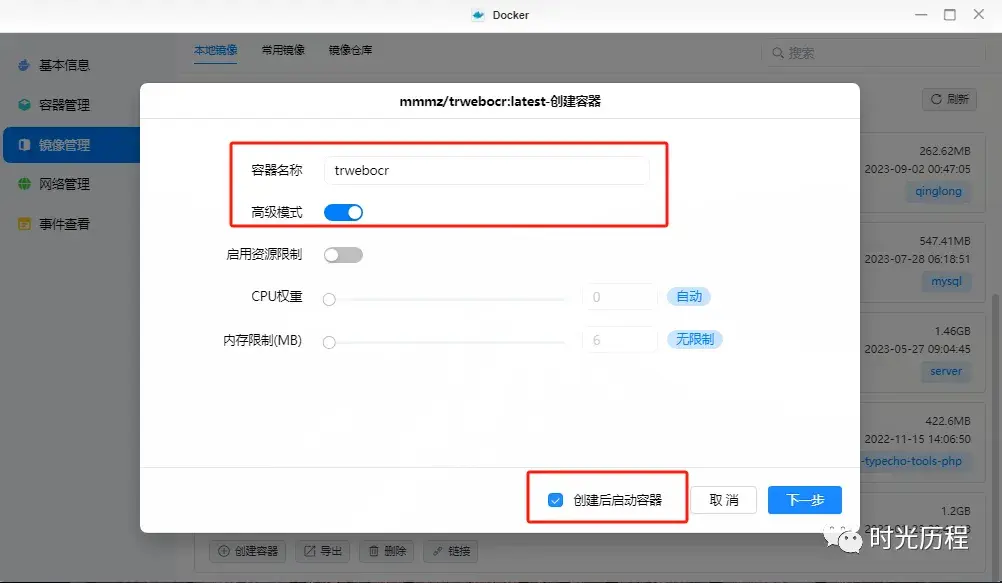
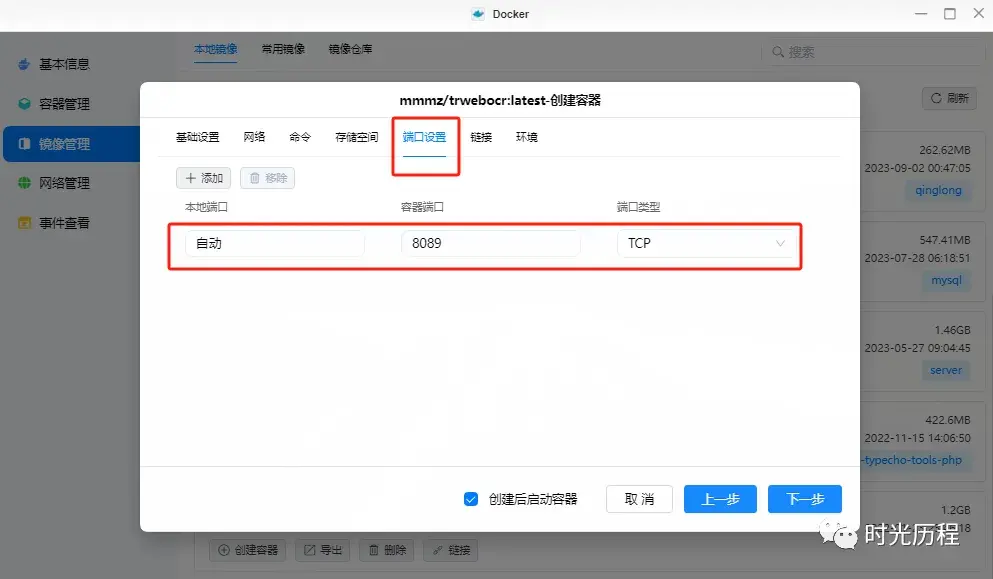
下载完成后,我们在本地镜像中找到刚刚下载的镜像,点击创建容器,起一个英文名,勾选创建后启动容器,点击下一步。
在基础设置中,重启策略选择"容器退出时总是重启容器"。
设置一个喜欢的本地端口号。
此时,输入我们的 IP+端口 或者 域名+端口 即可在线访问。
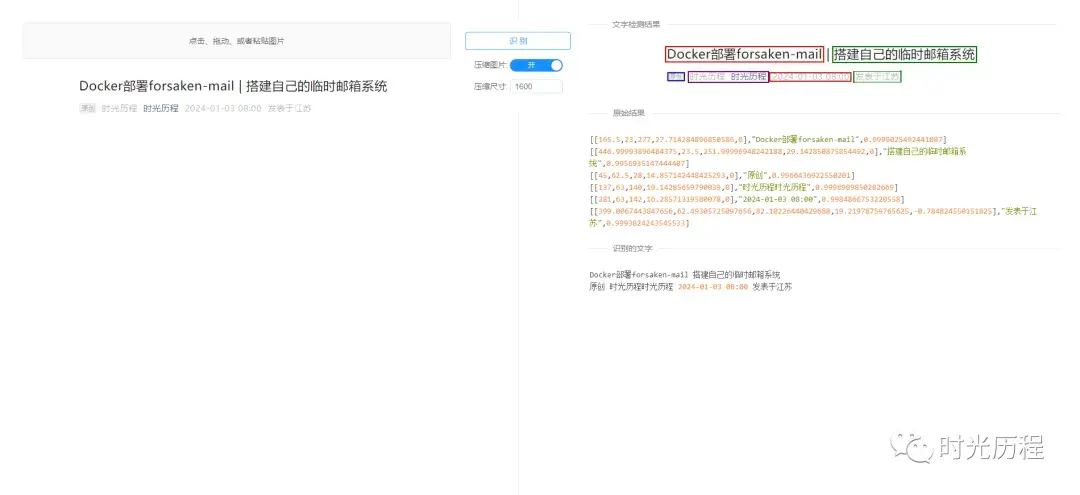
来测试一下效果
命令部署
# 从 dockerhub pull
docker pull mmmz/trwebocr:latest
`# 运行镜像
docker run -itd --rm -p 8089:8089 --name trwebocr mmmz/trwebocr:latest
`
这里把容器的8089端口映射到了物理机的8089上,但如果你不喜欢映射,去掉run后面的-p 8089:8089 也可以使用docker的IP加8089来访问
接口调用示例
Python 使用File上传文件
import requests
url = 'http://192.168.31.108:8089/api/tr-run/'
img1_file = {
'file': open('img1.png', 'rb')
}
res = requests.post(url=url, data={'compress': 0}, files=img1_file)
Python 使用Base64
import requests
import base64
def img_to_base64(img_path):
with open(img_path, 'rb')as read:
b64 = base64.b64encode(read.read())
return b64
url = 'http://192.168.31.108:8089/api/tr-run/'
img_b64 = img_to_base64('./img1.png')
res = requests.post(url=url, data={'img': img_b64})
接口说明
描述: 进行文字识别与检测的接口
地址: /api/tr-run/
方法 :POST
请求参数:
| 参数名称 | 是否必选 | 数据类型 | 描述 | |----------|------------|--------|----------------------------------------------------------| | file | 和 img 二选一 | file | 通过上传的方式来发送图片的字段 | | img | 和 file 二选一 | string | 图片的base64值,不需要前缀。 | | compress | 否 | int | 值为空时,默认将图片最长边压缩到1600px。值为 0 时,不压缩图片。值为非0 时,将最长边压缩到该值的大小。 | | is_draw | 否 | int | 值为 0 时,不返回图片。(没有data['img_detected']返回) |
返回参数:
| 参数名称 | 是否必选 | 数据类型 | 描述 | |------------------------|------|--------|----------------------------| | code | 是 | int | 识别结果的状态码,识别成功为200,有异常为 400 | | msg | 是 | string | 识别结果的文字信息 | | data | 否 | dict | 识别结果,若识别异常则没有此字段 | | data['img_detected'] | 是 | string | 画出文字区域的图片base64值 | | data['raw_out'] | 是 | list | 识别结果的输出 | | data['speed_time'] | 是 | float | 识别的耗时 |
返回示例:
{"code": 200,
"msg": "\u6210\u529f",
"data": {
"img_detected": "data:image/jpeg;base64,/9j/4AAQSkZJR5t...",
"raw_out": [[[11, 13, 402, 36], "\u753b\u51fa\u6587\u5b57\u533a\u57df\u7684\u56fe\u7247base64\u503c", 0.9999545514583588], [[11, 112, 215, 36], "\u8bc6\u522b\u7ed3\u679c\u7684\u8f93\u51fa", 0.999962397984096], [[11, 171, 158, 36], "\u8bc6\u522b\u7684\u8017\u65f6", 0.999971580505371]],
"speed_time": 0.67}}
开源地址: https://github.com/alisen39/TrWebOCR
感谢各位小伙伴阅读本文!希望这篇文章能对大家有所帮助。如果大家觉得这篇文章还不错,别忘了点赞、评论和关注哦!你们的支持是我最大的动力,我会继续努力,为大家带来更多优质内容。非常感谢大家的三连,咱们下期再见!