上期的【保姆级教程】小爱同学+AI!魔改小爱音箱,接入本地AI大模型,打造你的专属语音助手!不少小伙伴表示感兴趣,这一期我们继续搞大模型,同样用Ollama。
通过这篇文章,我们最终会实现:
大模型跑在本地的Mac上,通过ngrok穿透,让所有能联网的 iOS 生态系统(macOS、iOS、WatchOS、Vision Pro)中的所有设备都能用上端侧大模型,实现无过滤、安全、私密和多模态的体验。
MacBook:
iPhone:
Vision Pro
实际演示:
视频之后补充
- Mac安装端侧大模型 {#1--Mac安装端侧大模型}
这部分上一期已经完成的可以直接跳到下一部分2. 在Mac上使用ngrok。
1.1 安装Ollama {#1-1-安装Ollama}
在准备我们的本地大模型之前,我们先安装Ollama。
Ollama你也可以理解成一个容器平台类似的东西,我们的本地AI模型是跑在Ollama上(因为本机不通过Ollama直接跑模型的话需要搞一堆复杂的配置,跑Ollama上就会简单很多)
我们直接来到官网:https://ollama.com/
点击Download下载,
选择自己的操作系统下载即可。
下载完成之后也一样打开。

就是这个小羊驼。
接着,我们同样然后Mac上打开"终端"
输入ollama -v
出现版本号证明我们安装好了。
浏览器上访问:http://localhost:11433/或者http://127.0.0.1:11433/
会出现Ollama is running
1.2 下载本地AI模型 {#1-2-下载本地AI模型}
接下来我们就可以来下载本地AI模型了。
细心的小伙伴可能已经发现了,刚ollama的右上角有一个"Models"
点进去就能看到有很多模型可以下载。
比如非常火的llama3、阿里的千问等等。
然后我们看到每个模型的下面有蓝色的8B、70B的字样,这个其实就是参数量(B代表Billion,十亿),一般来说,参数量越大,模型越牛逼。当然也越消耗机器的性能,如果你机器的配置足够高的话,可以下载参数量大一些的模型试试。
比如这个llama3的700亿参数的模型,大小是40G左右,(对比GPT-4 估计拥有约 1.8 万亿个参数)
下载方法是:ollama run llama3:70b
Mac上打开"终端"

它就会自己去下载这个40G的模型了。
当然相信绝大多数人都跑不动这个"大"模型(机器性能不够)
所以最近有一个词火了起来"小语言模型"(SLM,Small Language Model),对应于"大语言模型"(LLM,Large Language Model)
小语言模型的最大优势就是参数小但是性能不弱,对机器的配置要求也会低一些,之后甚至可能可以在手机、树莓派这些设备上很好运行。
4 月底,微软发布了其 Phi-3 SLM 系列,拥有 38 亿到 140 亿个参数(3.8B------14B之间)。
在一系列测试中,微软最小的模型 Phi-3-mini 与 OpenAI 的 GPT-3.5(1750 亿个参数)不相上下,其表现也优于谷歌的 Gemma(70 亿个参数)。
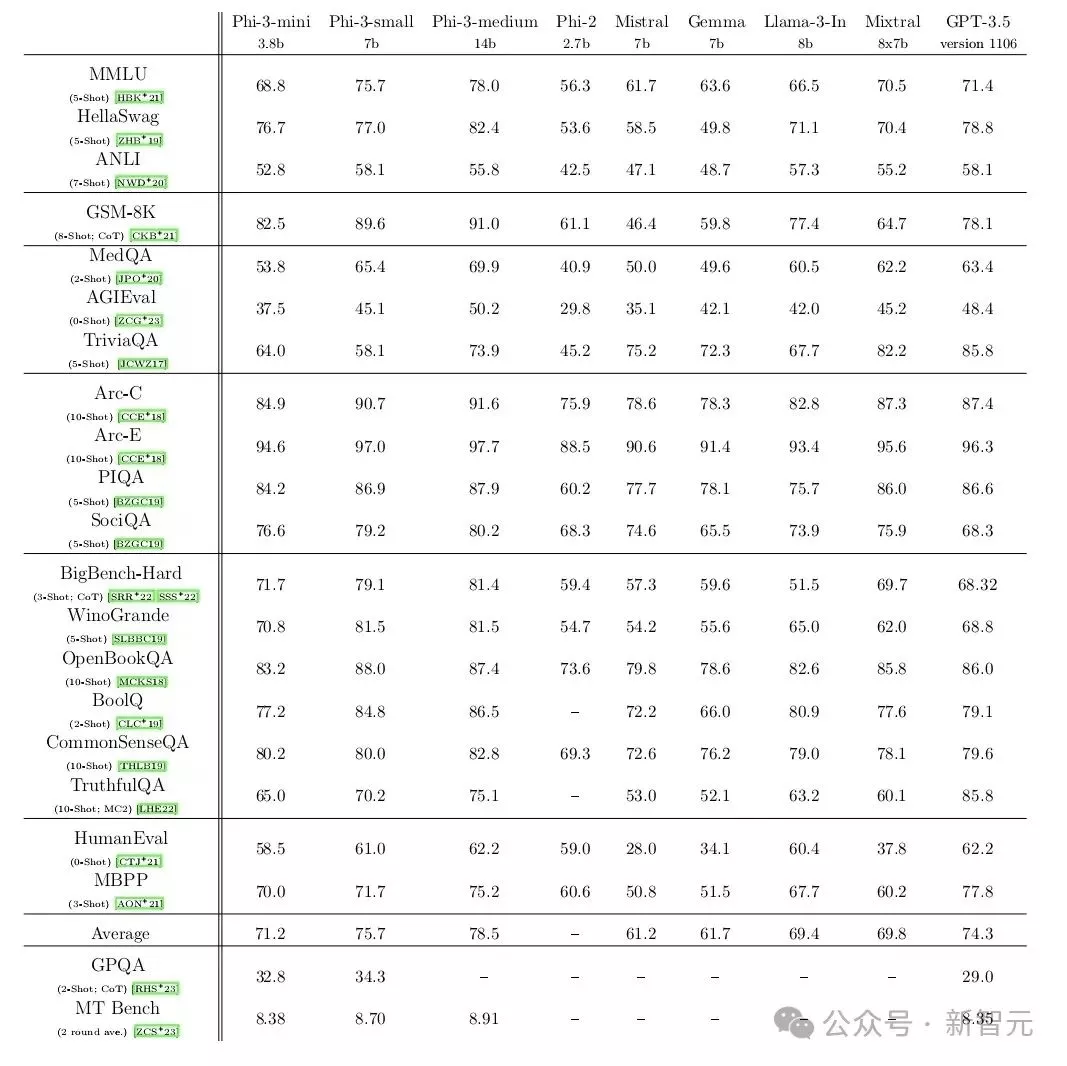
测试通过向模型提出有关数学、哲学、法律等方面的问题,评估了模型对语言的理解能力。
更有趣的是,拥有 70 亿个参数的微软 Phi-3-small 在许多基准测试中的表现都明显优于 GPT-3.5。
资料来自:https://m.ithome.com/html/779732.htm
所以我们就来装一个Phi-3试试吧。
Mac上打开"终端"
运行:
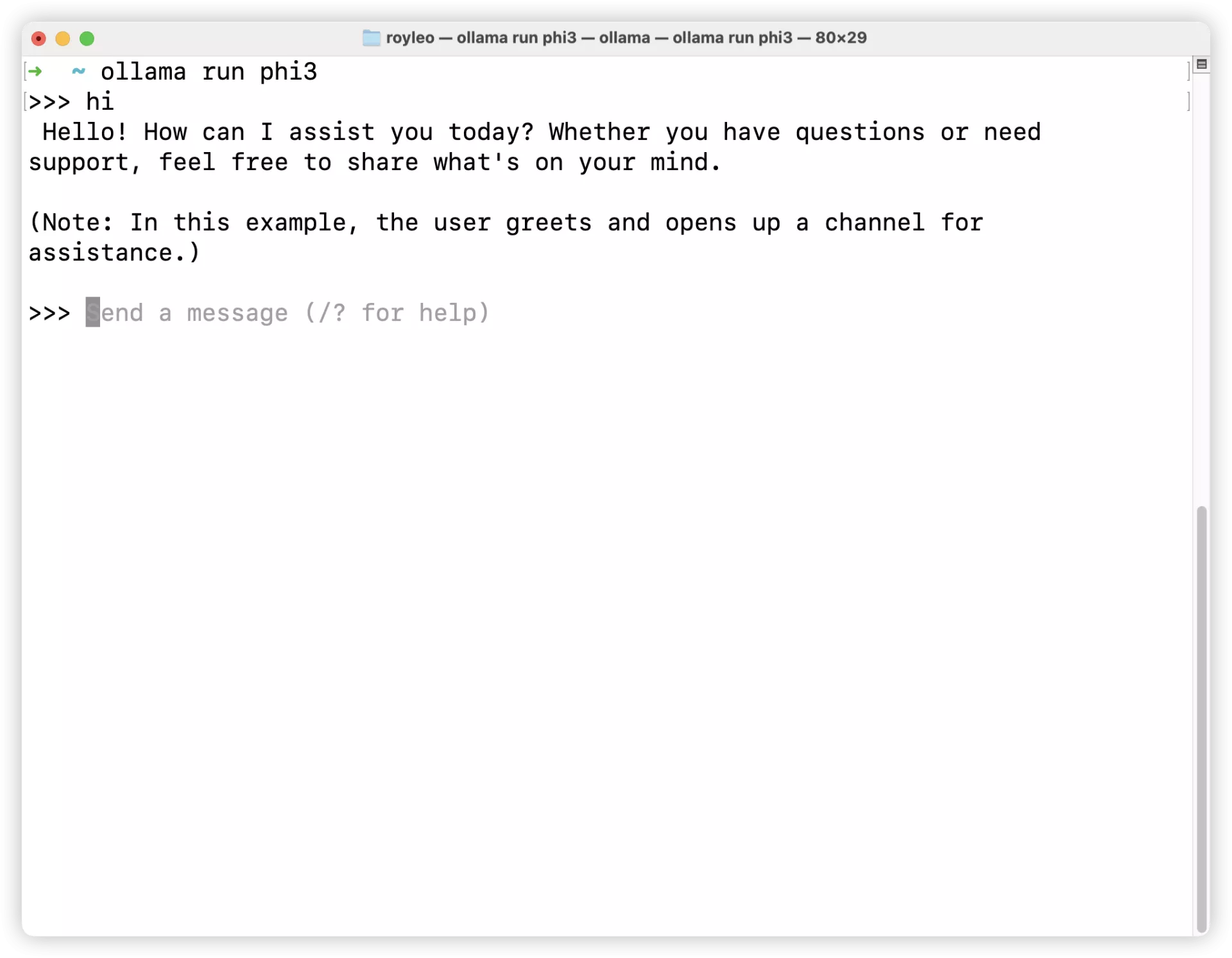
ollama run phi3
第一次ollama会去下载这个模型,下载完之后会出现这个个交互界面:
其实这个时候我们已经可以和模型对话了。
直接输入:hi
它会回复我们:
我们先输入:/bye 退出,一会儿再来用它。
- 在Mac上使用ngrok {#2--在Mac上使用ngrok}
本地大模型搞定了,Mac本机上已经可以访问了,但是这还不够。
我们现在想要在我们的iPhone上或者iPad上也能访问,希望在任何地方都能用上这个部署的模型,应该怎么做呢?
我们可以借助ngrok这个东西来完成。
ngrok是一个反向代理工具,它允许你将本地运行的服务器暴露到公网上,提供一个通过互联网可访问的公网URL。这使得无需进行复杂的网络配置或拥有公网IP,你就可以轻松地进行Web开发测试、演示或其他需要公网访问的场景。ngrok支持多种协议,包括HTTP、HTTPS和TCP,并提供安全的隧道服务。使用ngrok可以极大地简化开发和测试过程,提高效率。
刚刚上面提到,ollama运行的时候,访问http://localhost:11433/或者http://127.0.0.1:11433/
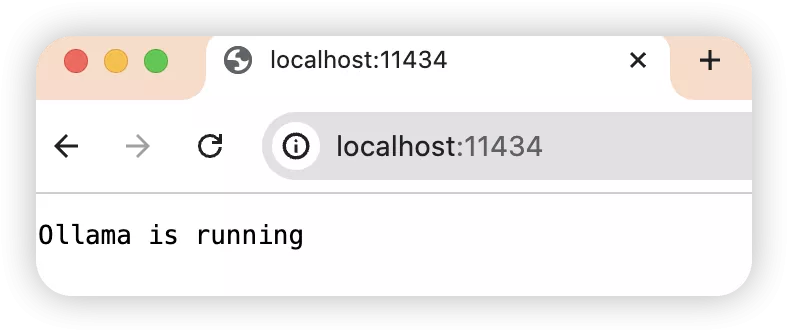
会显示Ollama is running,但是由于localhost和127.0.0.1都是本地地址,只有本地可以访问,我们借助ngrok这个工具,把http://localhost:11433/或者http://127.0.0.1:11433/变成一个类似www.baidu.com的地址,是不是就可以在任何有互联网的地方访问了?!
2.1 下载ngrok {#2-1-下载ngrok}
打开浏览器,访问ngrok的官方网站:https://ngrok.com/
点击网站上的"Sign up"进行注册,或者"Log in"如果你已经有账号。
验证邮箱:
点击邮件链接之后,这个之后会有一个二维码,让你用1Password, Google Authenticator, 或者Microsoft Authenticator这几个APP来扫描,做二步验证用的。
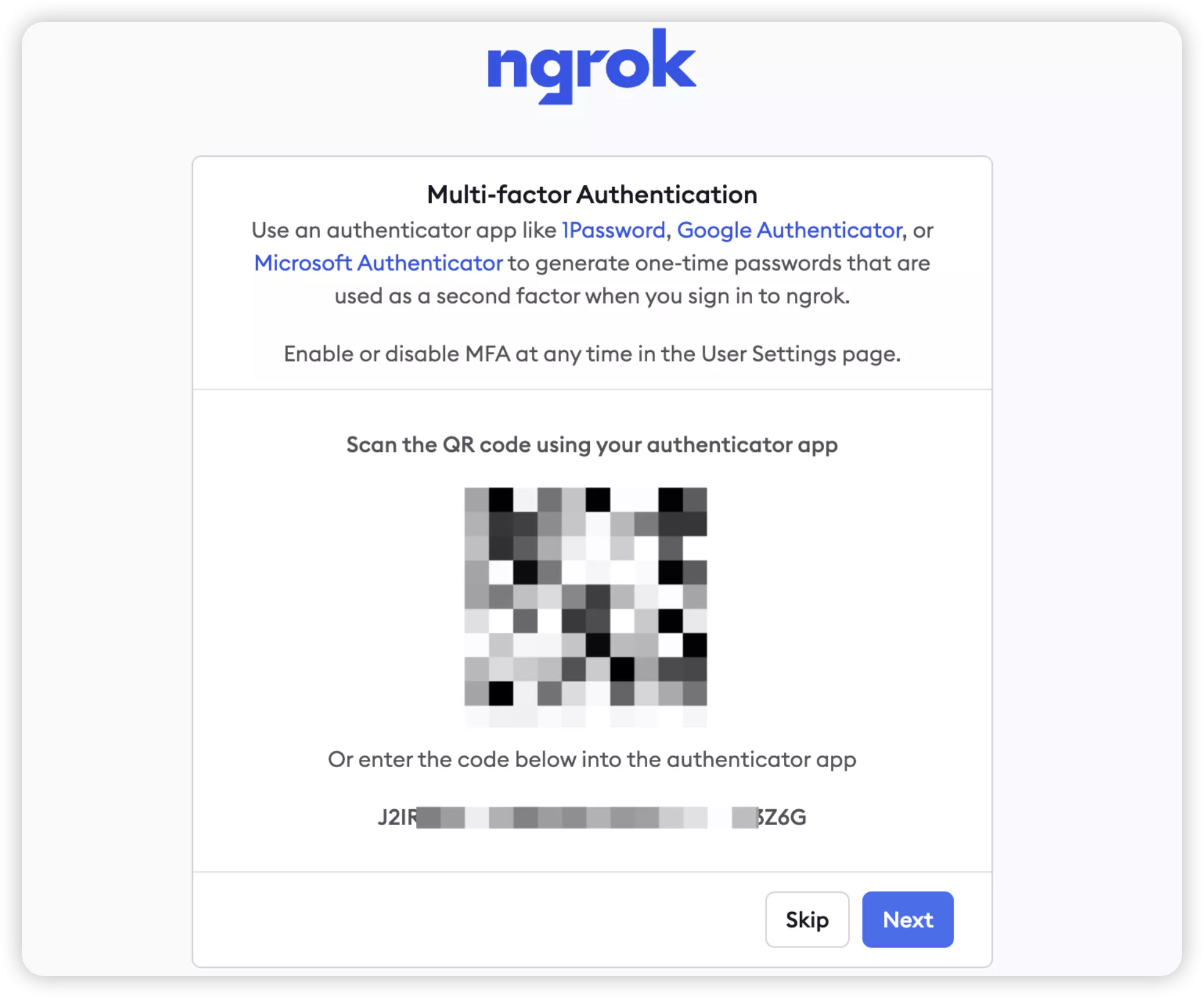
记得保存好后面的代码,万一手机丢了可以恢复。
2.2 安装ngrok {#2-2-安装ngrok}
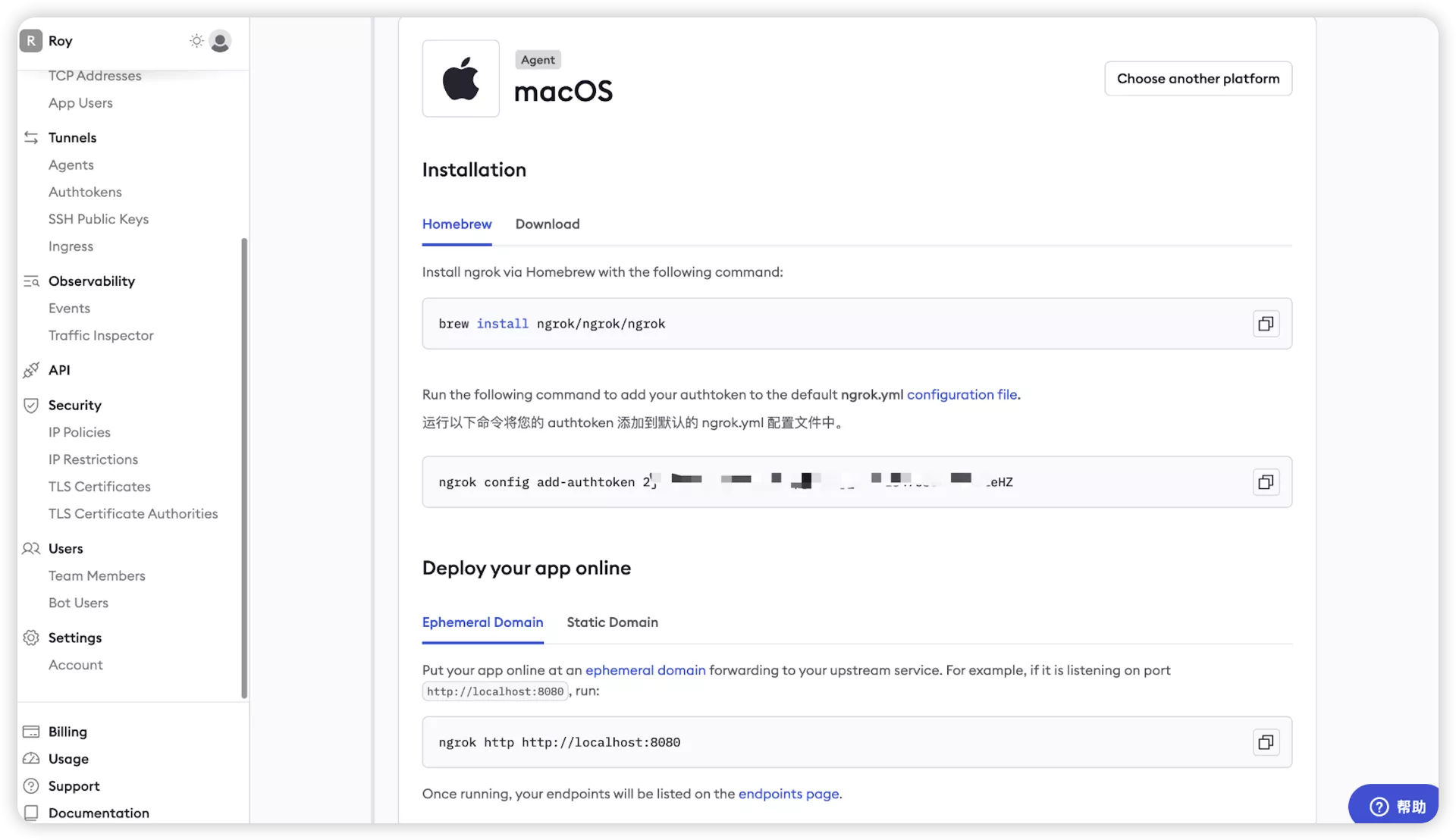
可以看到提供了两种安装方式:
(一)通过homebrew来安装:
brew install ngrok/ngrok/ngrok
做一个账号绑定:
ngrok config add-authtoken 2j5XZ1512rSs4pjUn6Nj_4HWtzdaklejawo12343alodjieHZ
(二)通过普通方式安装(记得同样需要账号绑定):
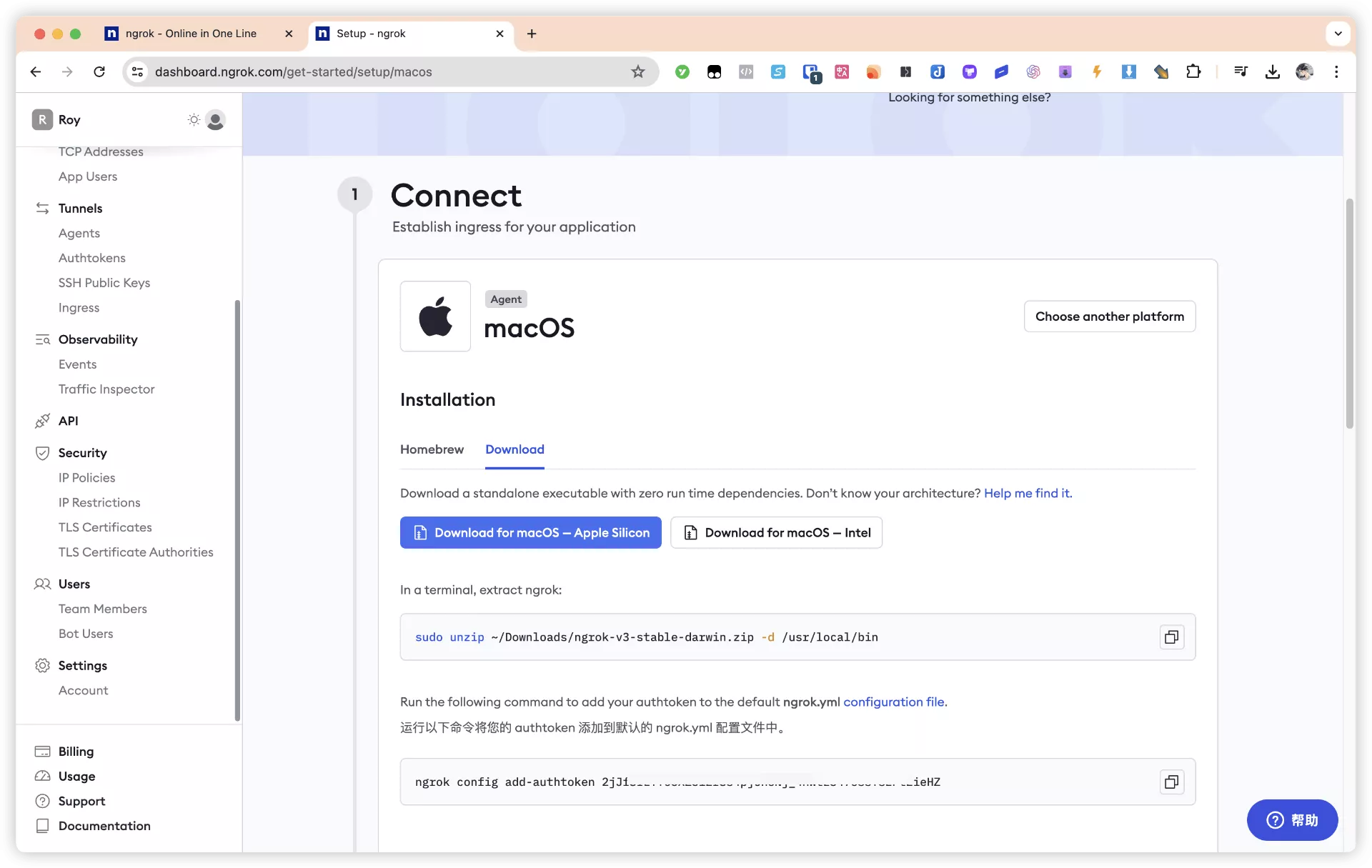
2.3 使用ngrok {#2-3-使用ngrok}
在终端中,你可以通过下面的命令来启动一个HTTP隧道,代理本地的某个端口(如代理本地的11434端口):
ngrok http 11434 --host-header="localhost:11434"
运行该命令后,ngrok会提供一个公网可访问的URL,通过这个URL可以访问到你本地运行的服务。
2.4 确认ngrok运行 {#2-4-确认ngrok运行}
当你运行ngrok命令后,终端会显示当前隧道的状态,包括公网URL等信息。
运行情况:
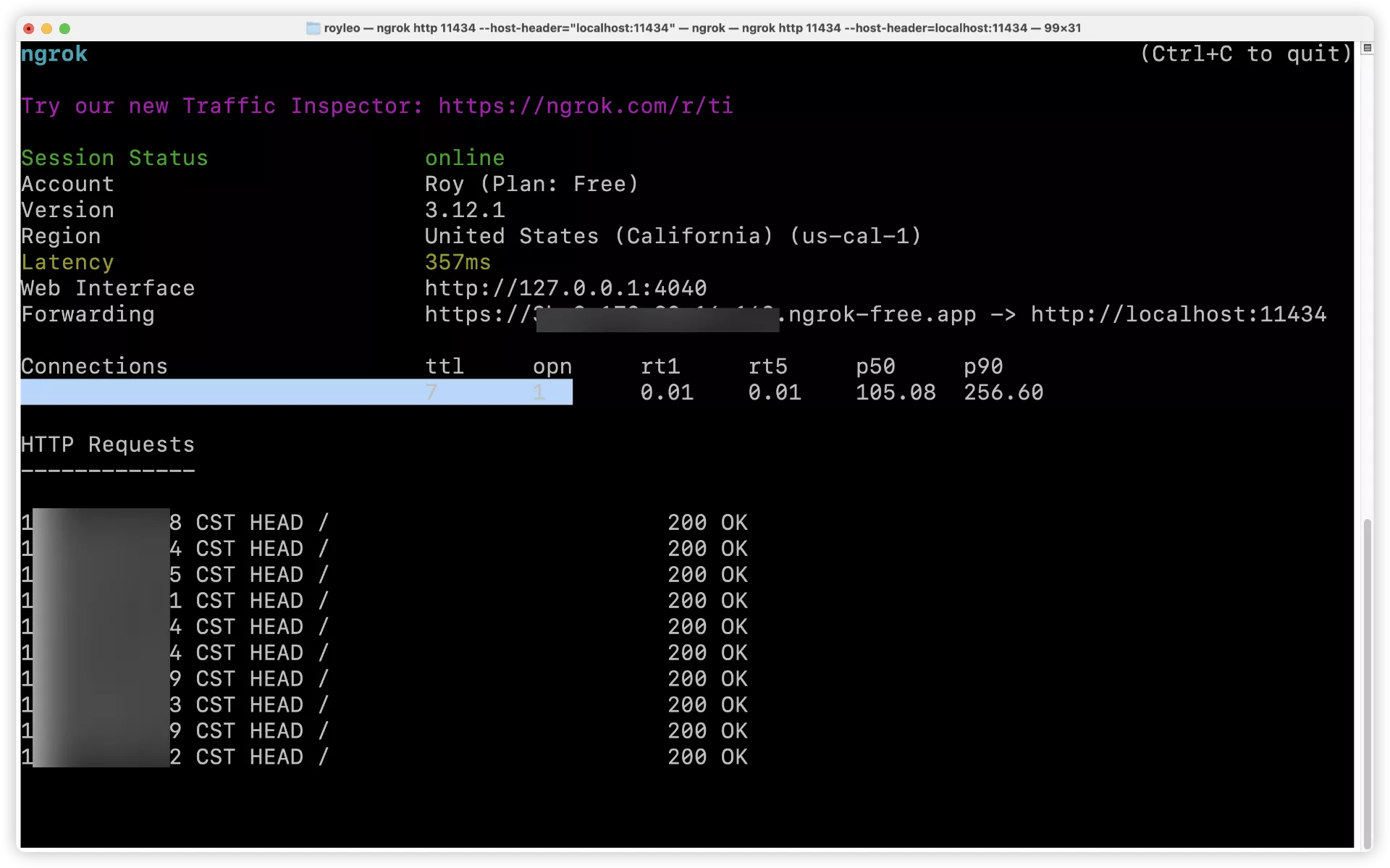
每次运行会变的:
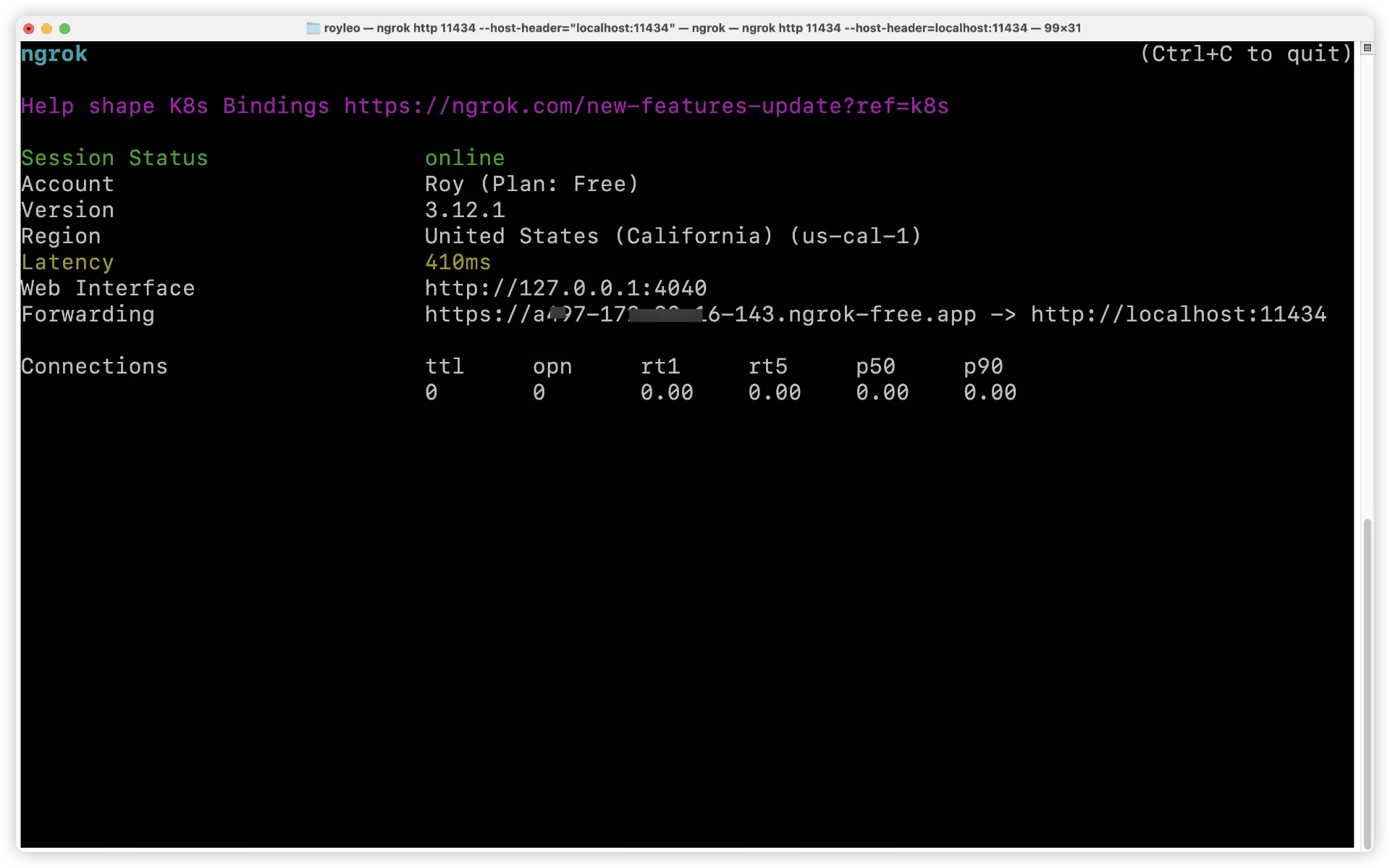
我们需要的就是
Forwarding https://09e1-173-81-26-133.ngrok-free.app -> http://localhost:11434
https://09e1-173-81-26-133.ngrok-free.app 这个是我们需要的网址。
注意,不要关闭这个窗口。
在任意设备(只要能联网)访问它:
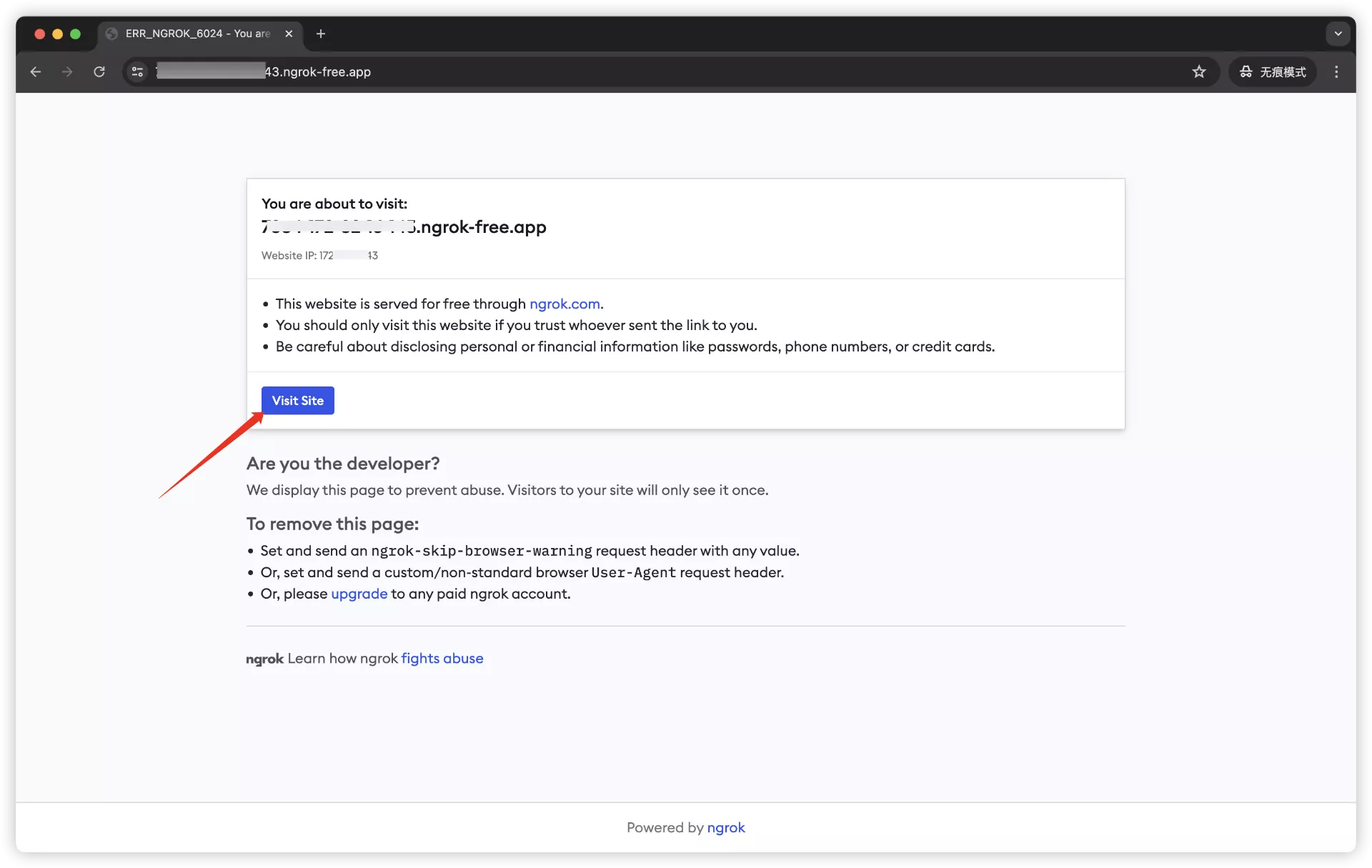
点击Visit site
显示这个Ollama is running说明成功了!
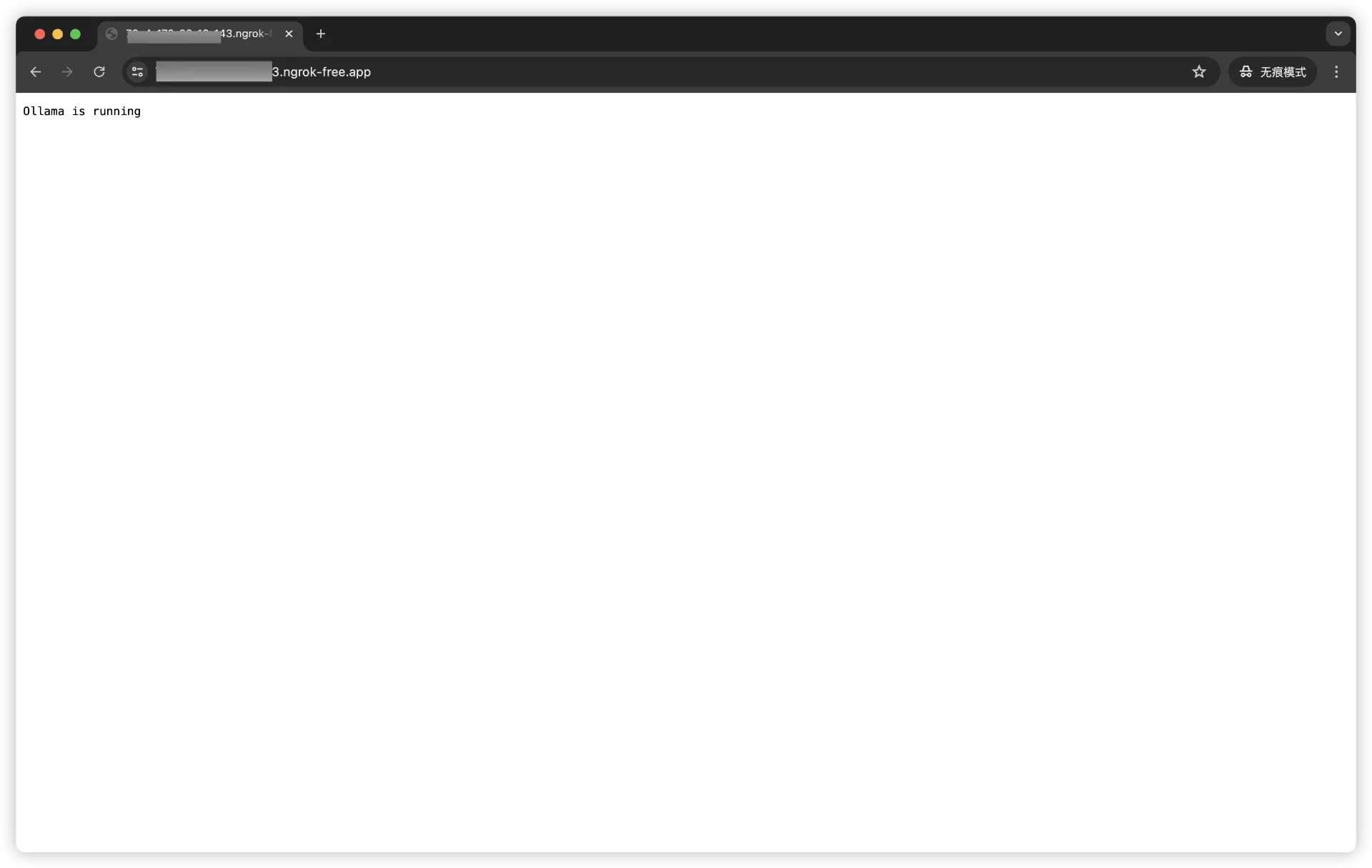
使用ngrok可以非常方便地将你的本地服务器暴露到公网上,非常适合进行Web开发的测试和演示。记得每次使用时都要检查安全设置,确保不会暴露敏感数据。
- Enchanted app下载 {#3--Enchanted-app下载}
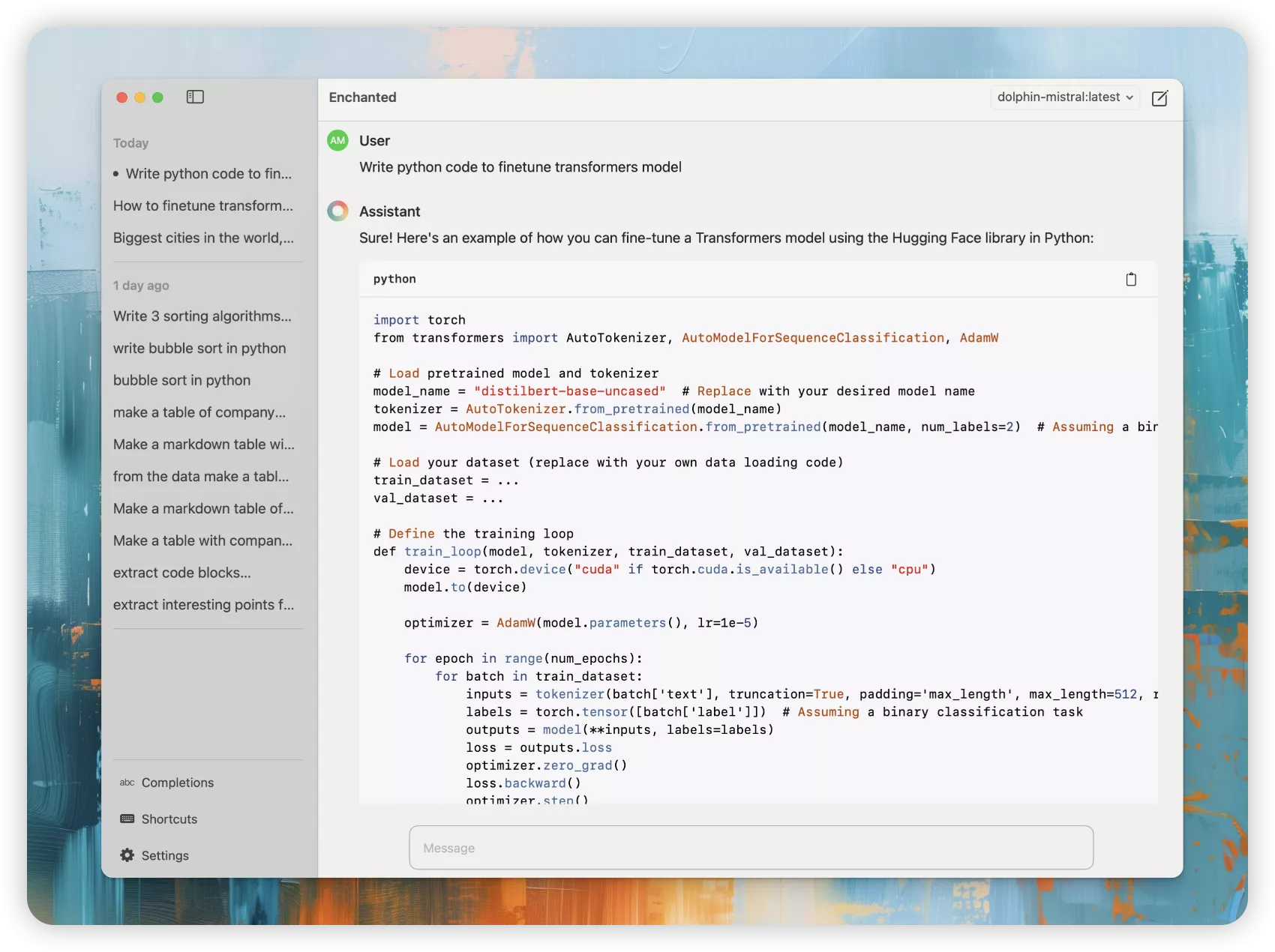
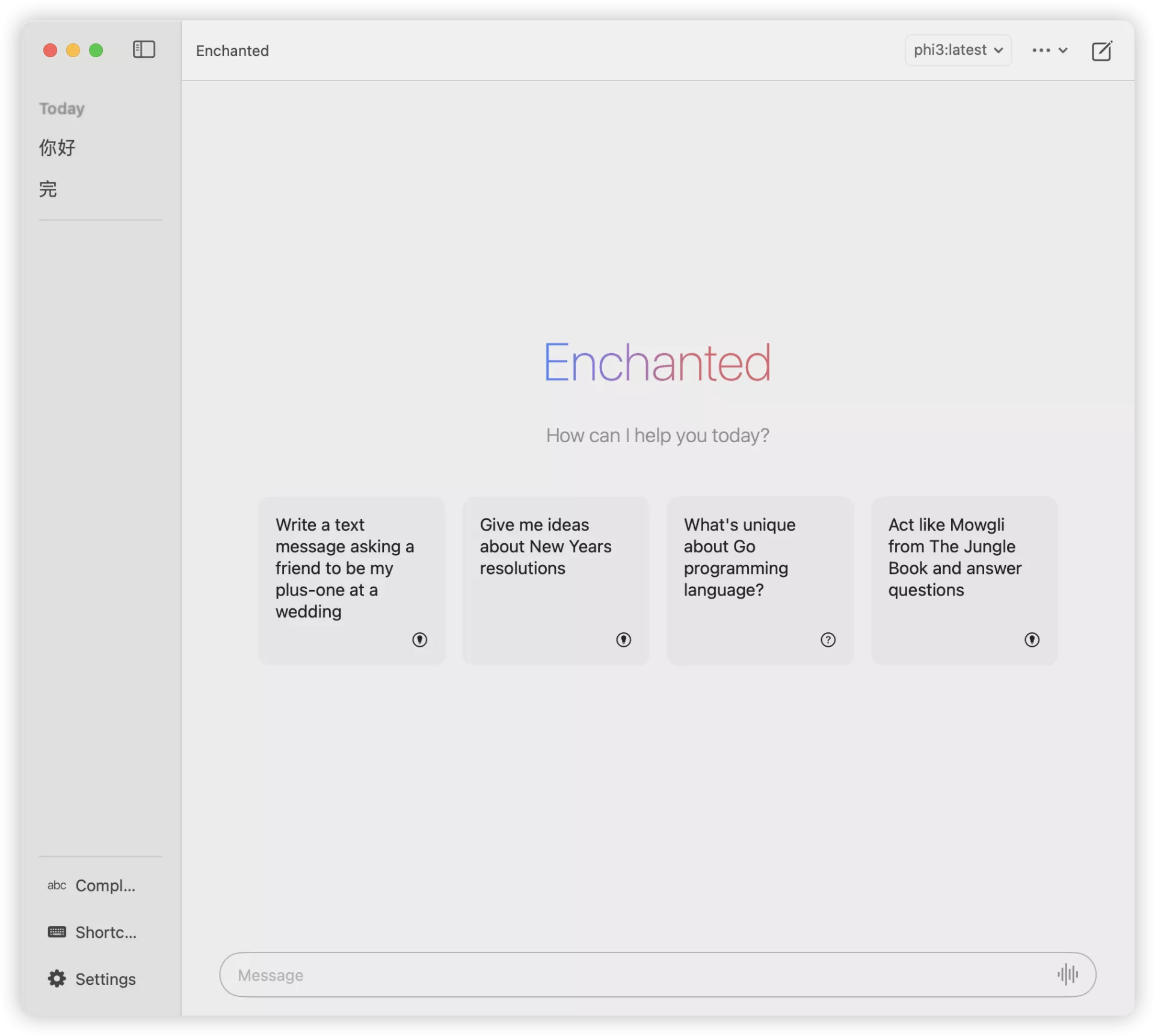
OK,万事俱备,就差一个用户访问的前端了,这边我们可以用Enchanted这个APP。
Enchanted 是一款适用于 iOS 和 macOS 的应用程序,可使用 Ollama 与私有自托管语言模型(如 Llama2、Mistral 或 Vicuna)进行聊天。
GitHub地址:https://github.com/AugustDev/enchanted?tab=readme-ov-file
App Store下载地址:https://apps.apple.com/gb/app/enchanted-llm/id6474268307
Enchanted支持如下功能:
- 文本转语音(朗读)
- API 调用中包含的对话历史
- 暗/亮模式
- 对话历史存储在您的设备上
- 支持Markdown(优雅显示表格/列表/代码块)
- 语音提示
- 为提示添加图像附件
- 指定系统提示用于每次对话
- 编辑消息内容或使用不同模型提交消息
- 删除单个对话/删除所有对话记录
- macOS Spotlight 面板
Ctrl+⌘+K快速调出 - 所有功能离线工作
- 连接Enchanted与本地Ollama {#4--连接Enchanted与本地Ollama}
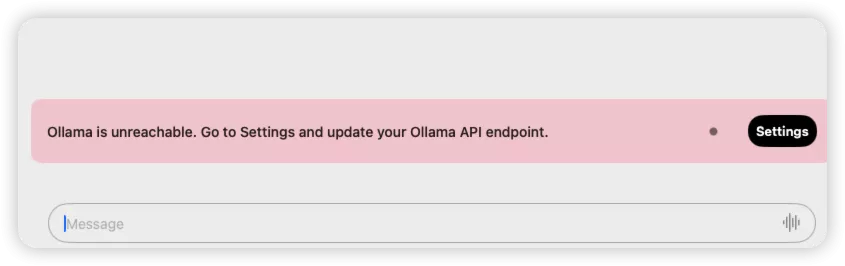
到设置里面,填入我们刚刚的那个公网可访问的URL,就可以使用了!
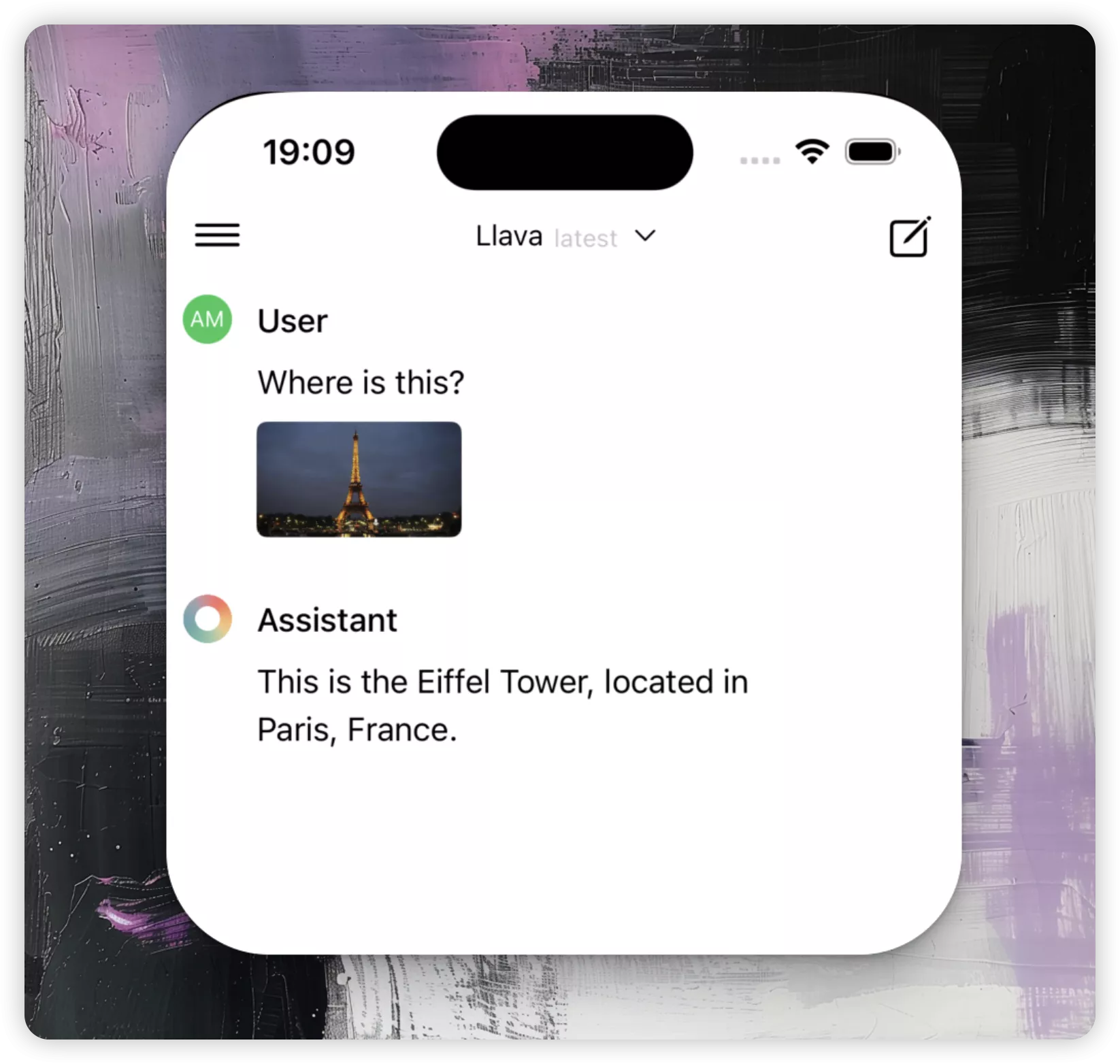
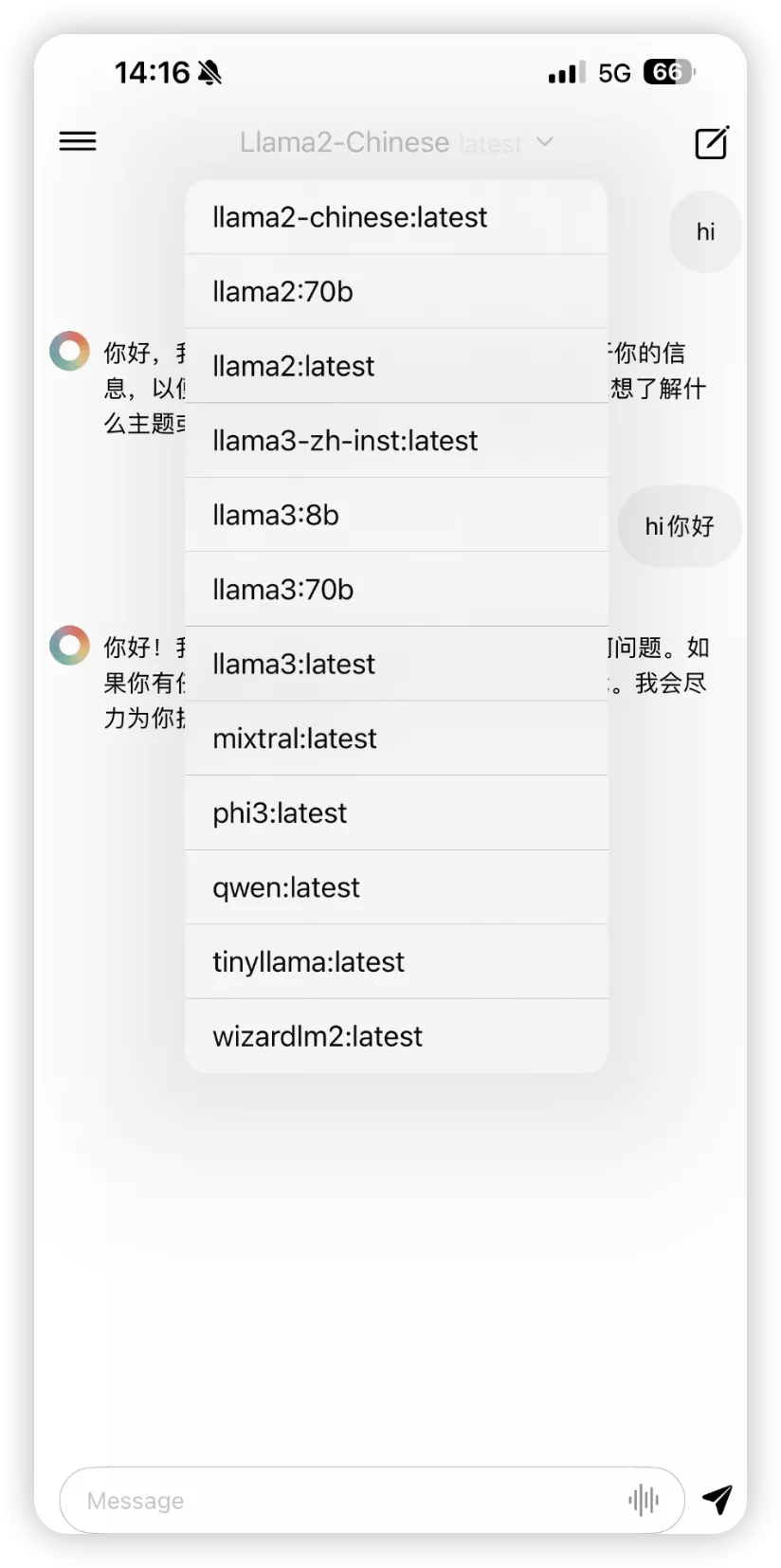
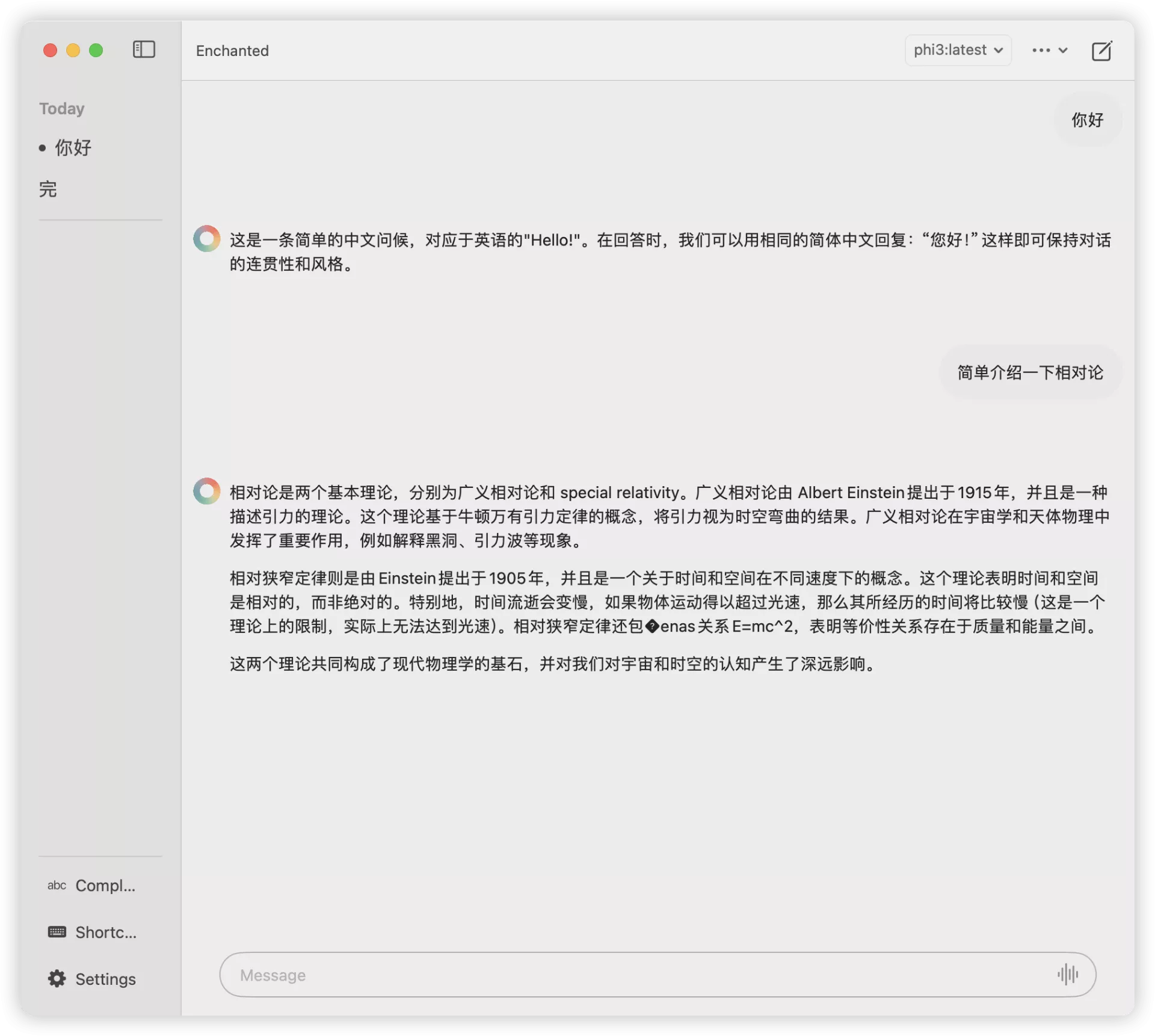
模型展示
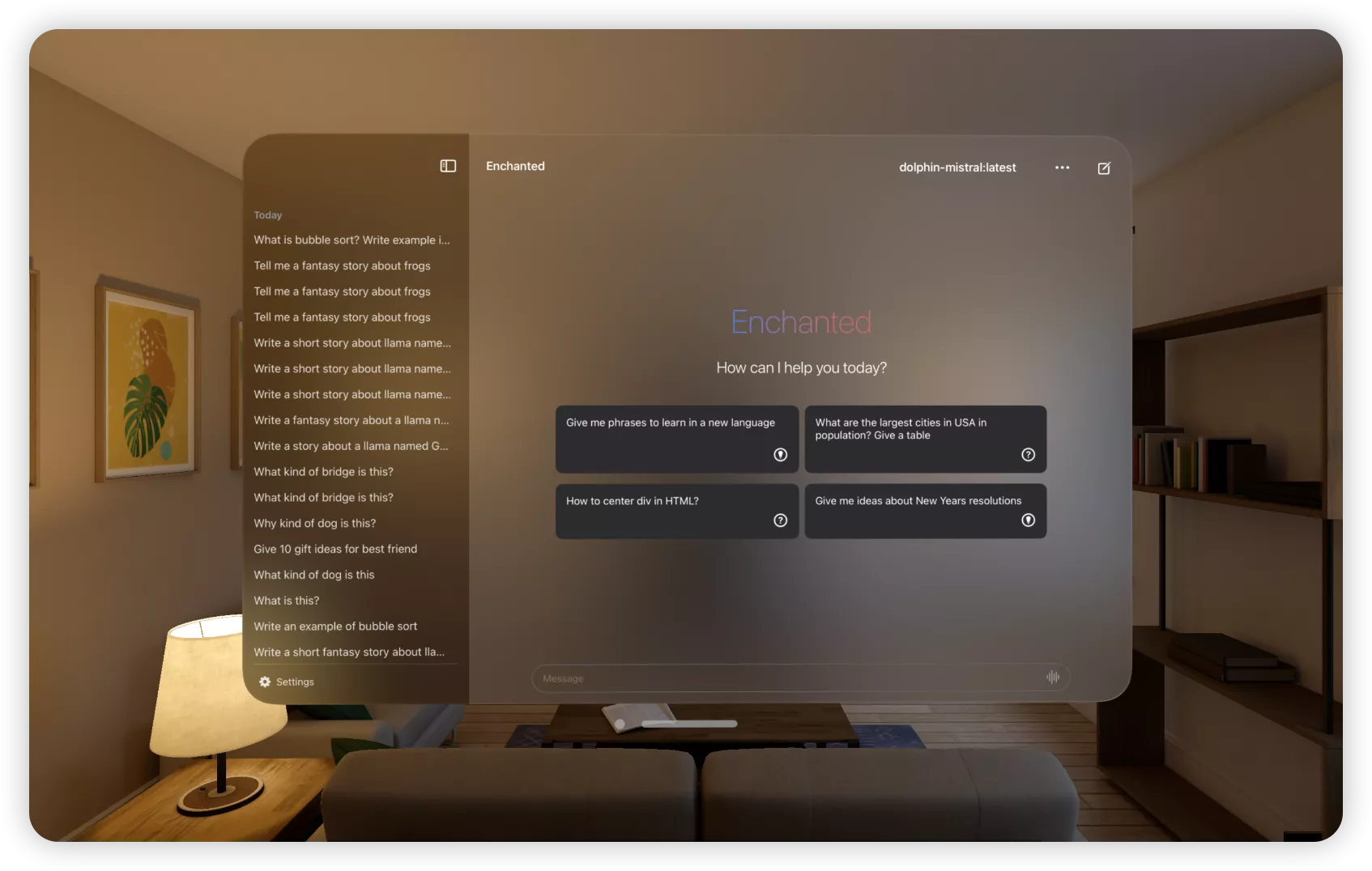
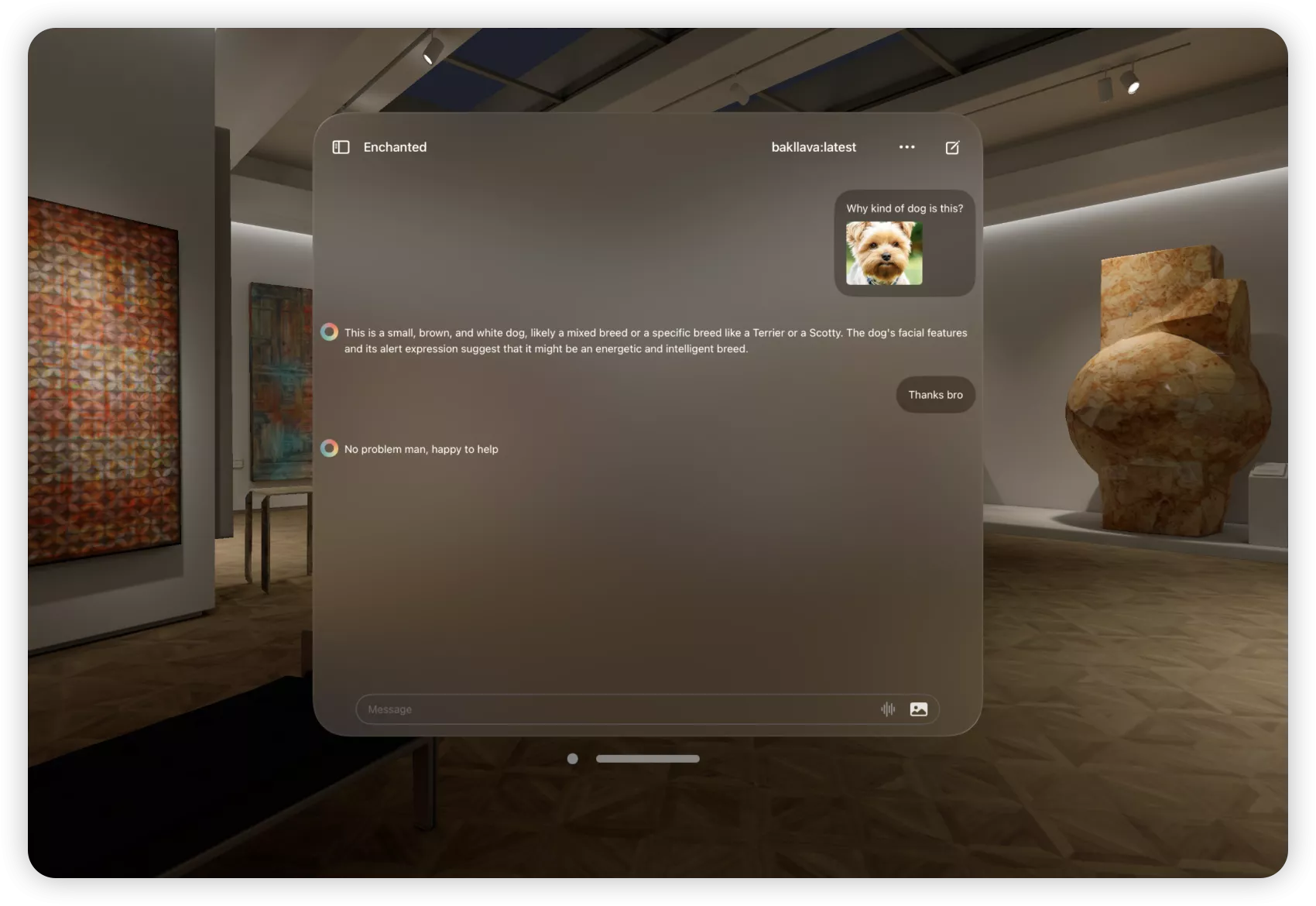
- 使用与演示 {#5--使用与演示}
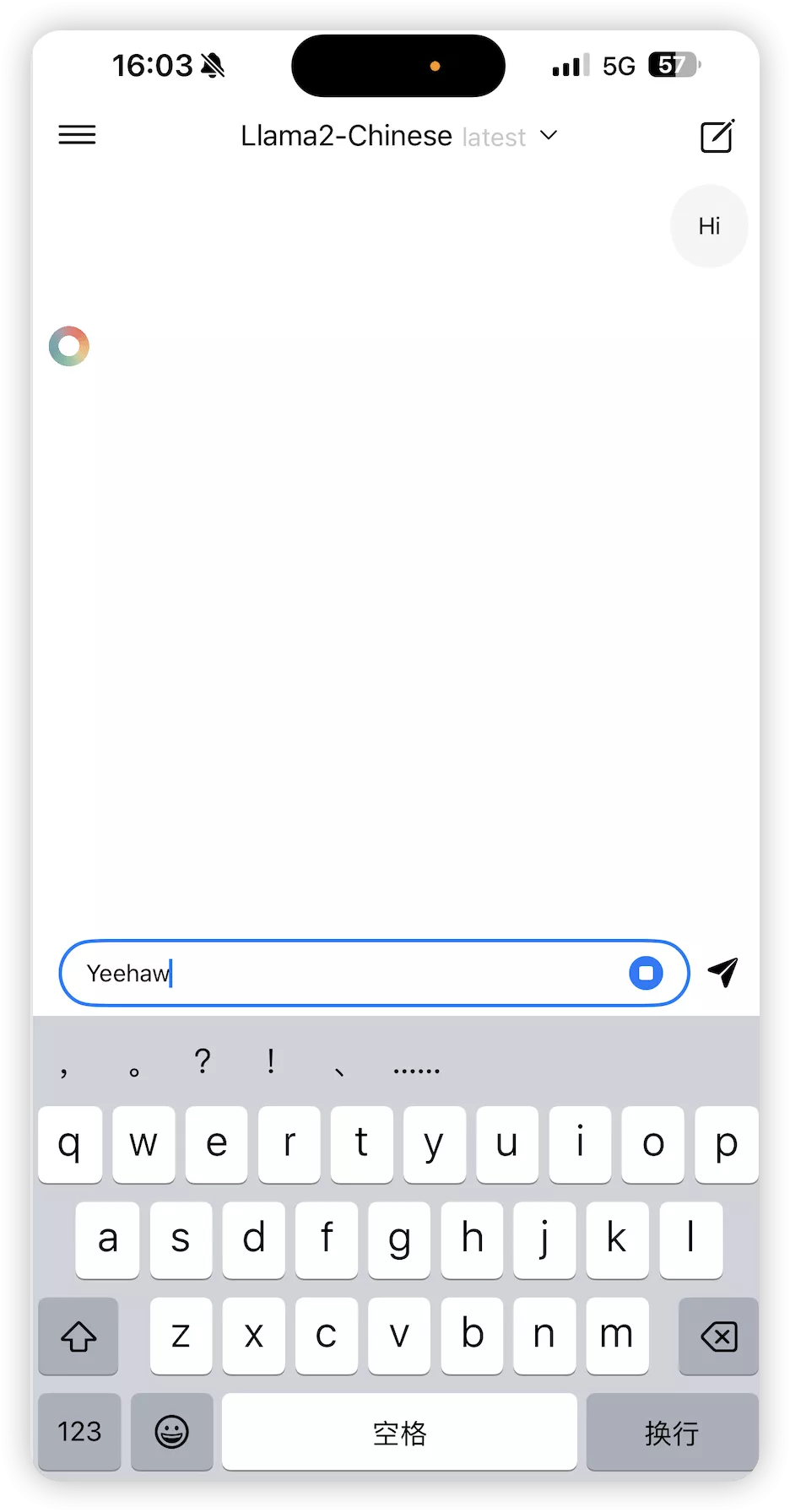
语音输入暂时只支持英文貌似。
我说你好,识别成了Yeehaw
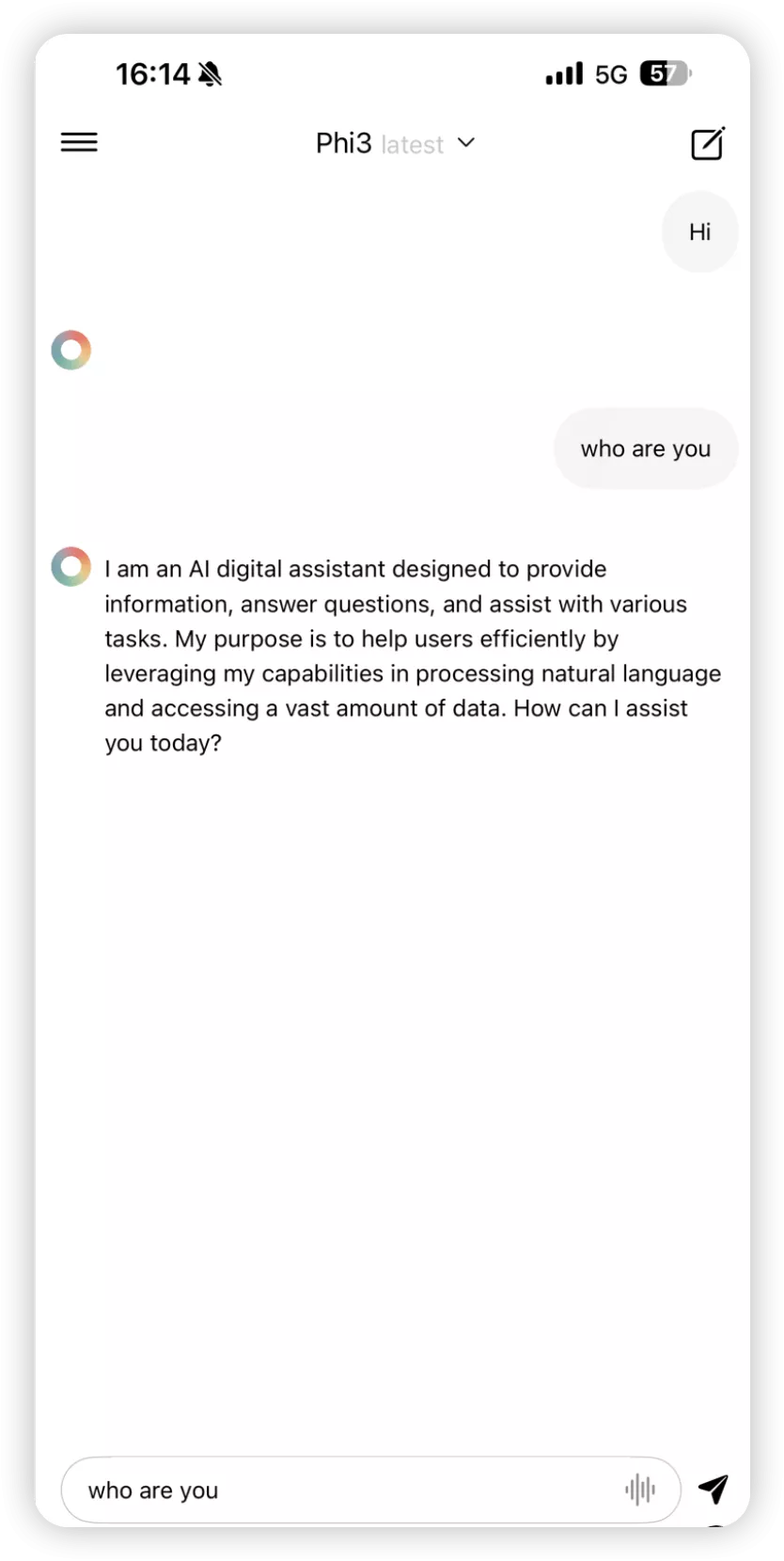
支持文本转语音(同样不支持中文):
赶紧玩起来吧!