● 开篇引言 在如今的数据驱动时代,Excel文件已经成为办公中不可或缺的工具之一。然而,当面对成百上千的Excel文件时,如何高效地批量提取其中的数据成为了很多人头痛的问题。今天,我们将用Python这个强大的工具,带你一步步揭开批量处理Excel数据的神秘面纱。无论你是数据分析师,还是企业管理者,这篇文章都将帮助你在工作中事半功倍。
● 理论基础 在深入代码之前,我们需要先理解几个基础概念。首先是Python中的两个重要库:pandas和openpyxl。pandas 是Python中处理数据的强大库,适用于读取和操作表格数据,而openpyxl 则是专门用于处理Excel文件的库。
-
pandas:以DataFrame为核心的数据结构,提供了便捷的数据操作方法,包括读取、筛选、合并等功能。它是处理表格数据的首选工具。
-
openpyxl:用于读取和写入Excel 2010 xlsx/xlsm/xltx/xltm文件。它允许你操作工作簿、工作表、单元格,甚至是图表。
理解了这两个库的作用后,我们就能高效地用Python实现批量提取Excel数据的功能。
接下来,我们进入实战部分。假设你有一个文件夹,里面有多个Excel文件,每个文件包含多个工作表,你需要从中提取特定工作表的数据并将它们合并到一个文件中。以下是具体的操作步骤:
安装所需库
首先,确保你已经安装了所需的库。如果没有安装,可以使用以下命令进行安装: *
pip install pandas openpyxl
导入必要的库
在Python脚本中,首先导入我们需要使用的库: * *
import osimport pandas as pd
定义文件路径和目标表名
设定要提取的文件夹路径以及目标工作表名称: * *
folder_path = '你的Excel文件夹路径'sheet_name = '你需要提取的工作表名'
批量读取并提取数据
通过循环遍历文件夹中的所有Excel文件,并提取指定工作表的数据: * * * * * * *
all_data = pd.DataFrame()
for file in os.listdir(folder_path): if file.endswith('.xlsx') or file.endswith('.xls'): file_path = os.path.join(folder_path, file) df = pd.read_excel(file_path, sheet_name=sheet_name) all_data = all_data.append(df, ignore_index=True)
保存提取的数据
最后,将提取到的数据保存到一个新的Excel文件中: * *
output_path = '合并后的Excel文件路径.xlsx'all_data.to_excel(output_path, index=False)
● 实例操作上面已经分开讲解了,这里直接上完整的代码:有什么不清楚的请留言小编,小编尽可能为你解答~~~ * * * * * * * * * * * * * * * * * * * * * * * * * * * *
import osimport pandas as pd
# 设定文件夹路径和目标工作表名称folder_path = 'your_excel_folder_path' # 请替换为你实际的文件夹路径sheet_name = 'Sheet1' # 假设需要提取所有文件中的Sheet1
# 创建一个空的DataFrame,用于存储合并后的数据all_data = pd.DataFrame()
# 遍历文件夹中的所有Excel文件for file in os.listdir(folder_path): # 检查文件扩展名 if file.endswith('.xlsx') or file.endswith('.xls'): file_path = os.path.join(folder_path, file) # 获取文件的完整路径 # 读取指定工作表的数据 df = pd.read_excel(file_path, sheet_name=sheet_name) # 将当前文件的数据追加到all_data中 all_data = all_data.append(df, ignore_index=True)
# 将合并后的数据保存到一个新的Excel文件中output_path = os.path.join(folder_path, 'merged_data.xlsx') # 合并后的Excel文件路径all_data.to_excel(output_path, index=False)
print(f"数据已成功提取并保存到 {output_path}")
代码解释:
-
os:用于处理文件和目录操作。 -
pandas:强大的数据处理库,用于读取和处理Excel文件中的数据。 -
folder_path:存放Excel文件的文件夹路径。 -
sheet_name:需要提取的工作表名称。此处假设所有文件中目标表的名称相同。 -
all_data:初始化一个空的DataFrame,用于存储所有文件中提取的数据。 -
os.listdir(folder_path):列出文件夹中的所有文件。 -
file.endswith():检查文件是否为Excel文件。 -
pd.read_excel(file_path, sheet_name=sheet_name):读取指定工作表的数据。 -
all_data.append(df, ignore_index=True):将读取的数据追加到all_data中。 -
output_path:指定合并后文件的保存路径。 -
all_data.to_excel(output_path, index=False):将合并后的数据保存到新的Excel文件中,不保存行索引。 -
输出一条消息,告知用户数据已成功处理并保存。
● 操作图例 样例数据1:
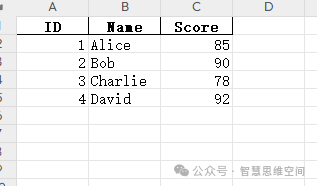
样例数据2:
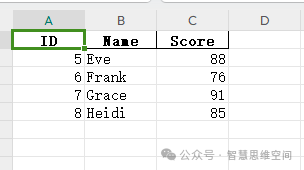
样例数据3:
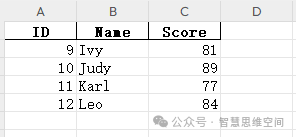
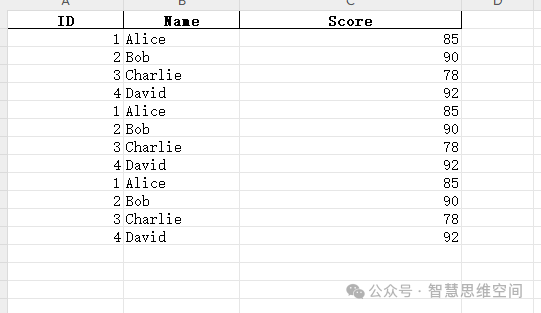
执行代码后的,提取的数据:
● 话题互动 看到这里,你是否觉得批量处理Excel文件再也不是难事了?你还有哪些Excel自动化处理的需求?或者你已经遇到了什么样的挑战?欢迎在留言区分享你的经验与疑问,让我们一起探讨Python在办公自动化中的更多可能性! ● 每日一句"掌握正确的工具和方法,你的工作效率将大大提升,而你的未来也将无限可能。"---小编
希望这篇文章能帮助读者更好地理解和应用Python批量提取Excel数据的技术。如果有任何问题或建议,请随时留言!





