一、 引言
随着人工智能技术的飞速发展,视频生成领域迎来了新的突破。8 月 6 日消息智谱 AI 宣布开源了其与"清影"同源的视频生成模型------CogVideoX 。这一举措不仅为开发者和企业提供了强大的工具,也为整个行业带来了新的发展机遇。本文将深入探讨 CogVideoX 模型的技术细节、应用潜力以及开源对行业的深远影响。
二、 CogVideoX 模型概览
- 模型简介
CogVideoX 是智谱 AI 推出的一款开源视频生成模型,具备生成高质量视频内容的能力。模型支持基于文本提示词的视频生成,能够将用户的文字描述转化为生动的视频画面。
 2. 技术特点
2. 技术特点
-
多尺寸模型支持 :CogVideoX 包含多个不同尺寸的模型,满足不同场景的需求。
-
高效显存利用 :CogVideoX-2B 版本在 FP-16 精度下推理仅需 18GB 显存,微调需要 40GB,使得单张高端显卡即可完成复杂任务。
-
视频生成能力 :模型能够生成长达 6 秒、每秒 8 帧、分辨率为 720x480 的视频,提示词上限为 226 个 token。
三、 CogVideoX 技术详解
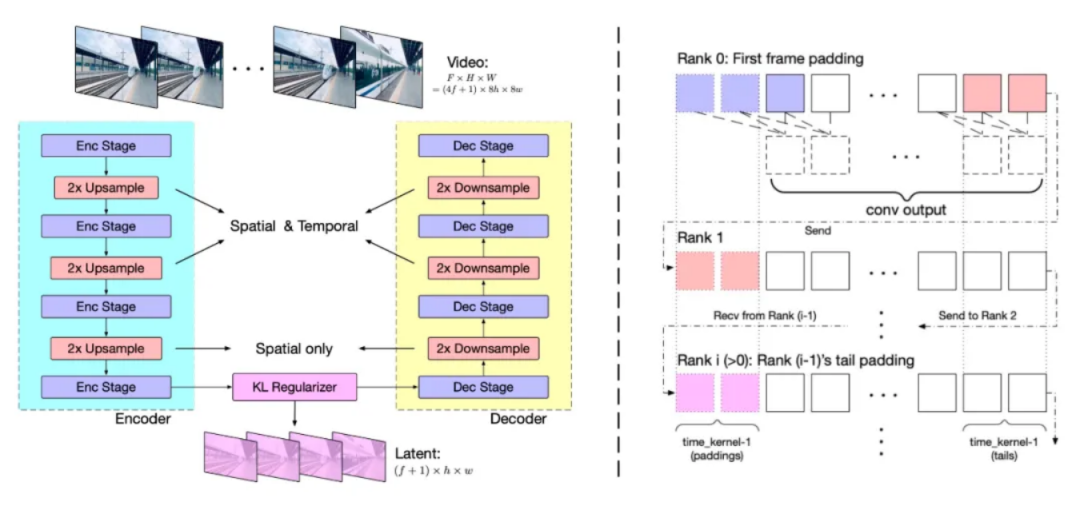
1. 3D Causal VAE 视频压缩技术
CogVideoX 采用了基于 3D 变分自编码器(3D VAE)的视频压缩技术。这种技术通过三维卷积同时压缩视频的空间和时间维度,实现了更高的压缩率和更好的重建质量。3D VAE 的编码器、解码器和潜在空间正则化器共同工作,通过四个阶段的下采样和上采样实现压缩,同时保持了信息的因果性,减少了通信开销。
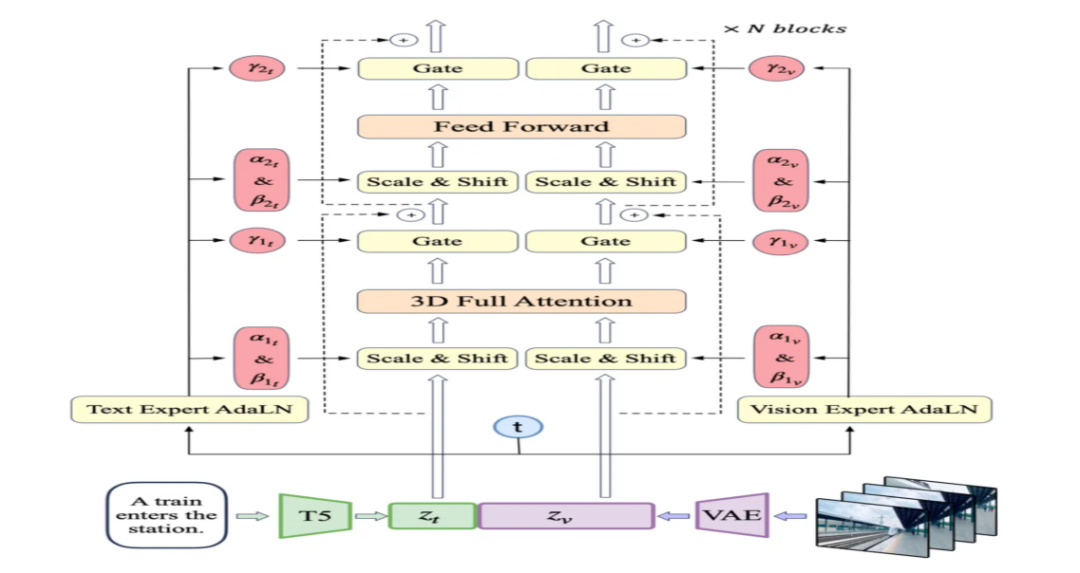
2. 专家 Transformer 架构
CogVideoX 采用了专家 Transformer 架构,这是一种特殊的 Transformer,通过多个专家处理不同的任务。这种架构优化了信息处理流程,提高了视频生成的质量和效率。专家 Transformer 能够更好地处理空间和时间信息,控制信息流动,从而生成更加连贯和逼真的视频内容。
3. 高质量视频数据筛选
为了训练出高质量的视频生成模型,智谱 AI 开发了负面标签来识别和排除低质量视频。通过 video-llama 训练的过滤器,智谱 AI 标注并筛选了大量视频数据点,确保了训练数据的高质量。同时,计算光流和美学分数,动态调整阈值,以确保生成视频的质量。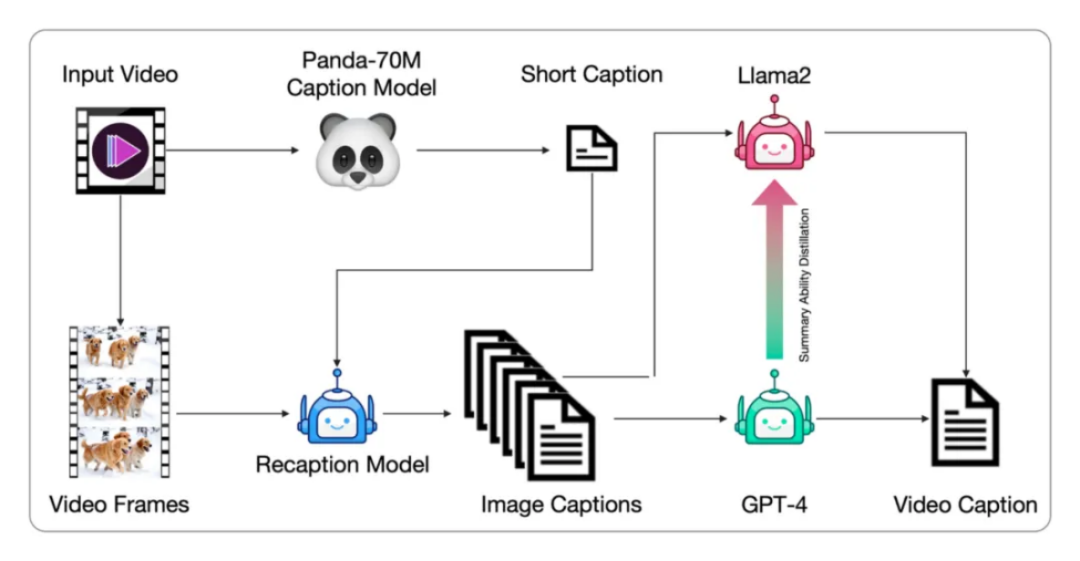
四、 CogVideoX 的应用前景
开源的 CogVideoX 模型为视频内容创作、广告制作、影视后期等领域带来了革命性的变化。它降低了技术门槛,使得更多的创作者和企业能够利用 AI 技术生成专业级别的视频内容。
- 创作者的新工具
创作者可以利用 CogVideoX 生成独特的视频内容,拓展创意边界,实现更加丰富和个性化的表达。无论是个人艺术家还是小型工作室,都能够通过 CogVideoX 实现之前难以想象的创作效果。
- 企业的新机遇
企业可以利用 CogVideoX 提高视频生产效率,降低成本,快速响应市场变化,提升竞争力。在广告、营销、产品展示等领域,CogVideoX 都能够提供强大的支持,帮助企业创造更具吸引力的视频内容。
- 教育和研究的新平台
教育机构和研究人员也可以通过 CogVideoX 探索视频生成技术的新领域。学生和研究人员可以在实践中学习和掌握 AI 视频生成技术,推动学术界和教育界的发展。
五、CogVideoX DMO样例
A detailed wooden toy ship with intricately carved masts and sails is seen gliding smoothly over a plush, blue carpet that mimics the waves of the sea. The ship's hull is painted a rich brown, with tiny windows. The carpet, soft and textured, provides a perfect backdrop, resembling an oceanic expanse. Surrounding the ship are various other toys and children's items, hinting at a playful environment. The scene captures the innocence and imagination of childhood, with the toy ship's journey symbolizing endless adventures in a whimsical, indoor setting. The camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope, dust kicks up from it's tires, the sunlight shines on the SUV as it speeds along the dirt road, casting a warm glow over the scene. The dirt road curves gently into the distance, with no other cars or vehicles in sight. The trees on either side of the road are redwoods, with patches of greenery scattered throughout. The car is seen from the rear following the curve with ease, making it seem as if it is on a rugged drive through the rugged terrain. The dirt road itself is surrounded by steep hills and mountains, with a clear blue sky above with wispy clouds.
六、CogVideoX 部署推理
1.安装依赖
pip install --upgrade opencv-python transformerspip install git+https://github.com/huggingface/diffusers.git@878f609aa5ce4a78fea0f048726889debde1d7e8#egg=diffusers # Still in PR
2.模型推理* * * * * * * * * * * * * * * * * * * * * * * *
import torchfrom diffusers import CogVideoXPipelinefrom diffusers.utils import export_to_videofrom modelscope import snapshot_downloadprompt = "A panda, dressed in a small, red jacket and a tiny hat, sits on a wooden stool in a serene bamboo forest. The panda's fluffy paws strum a miniature acoustic guitar, producing soft, melodic tunes. Nearby, a few other pandas gather, watching curiously and some clapping in rhythm. Sunlight filters through the tall bamboo, casting a gentle glow on the scene. The panda's face is expressive, showing concentration and joy as it plays. The background includes a small, flowing stream and vibrant green foliage, enhancing the peaceful and magical atmosphere of this unique musical performance."model_dir = snapshot_download("ZhipuAI/CogVideoX-2b")pipe = CogVideoXPipeline.from_pretrained(model_dir,torch_dtype=torch.float16).to("cuda")prompt_embeds, _ = pipe.encode_prompt(prompt=prompt,do_classifier_free_guidance=True,num_videos_per_prompt=1,max_sequence_length=226,device="cuda",dtype=torch.float16,)video = pipe(num_inference_steps=50,guidance_scale=6,prompt_embeds=prompt_embeds,).frames[0]export_to_video(video, "output.mp4", fps=8)
七、 结语
智谱 AI 的 CogVideoX 模型开源,不仅是技术层面的一次飞跃,更是对整个视频生成行业生态的一次重要贡献。它为开发者、创作者和企业提供了前所未有的机会,预示着视频生成技术将更加普及和成熟。随着性能更强、参数更大的模型即将推出,我们有理由相信,视频生成技术将开启一个全新的创意时代。
相关资料 代码仓库:https://github.com/THUDM/CogVideo
模型下载:https://modelscope.cn/models/ZhipuAI/CogVideoX-2b
技术报告:https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf






