AI 图像和视频生成领域又加入了一个颇有实力的玩家。
还记得今年 3 月底,从 AI 初创公司 Stability AI 离职的研究科学家 Robin Rombach 吗?作为开发出文生图模型 Stable Diffusion 的两位主要作者之一,他于 2022 年加入 Stability AI。

如今,在从 Stability AI 离职近五个月后,Robin Rombach 发推宣布了自己创业的好消息!
他成立了「Black Forest Labs」,旨在推进用于图像和视频的 SOTA 高质量生成式深度学习模型,并开放给尽可能多的人使用。

团队成员由杰出的 AI 研究者和工程师组成,他们之前的代表性工作包括 VQGAN 和 Latent Diffusion、图像和视频生成领域的 Stable Diffusion 模型(包括 Stable Diffusion XL、Stable Video Diffusion 和 Rectified Flow Transformers)以及用于超快实时图像合成的 Adversarial Diffusion Distillation。
值得注意的是,除了 Robin Rombach 之外,Stable Diffusion 还有三位作者成为了创始团队成员,包括 Andreas Blattmann、 Dominik Lorenz 和 Patrick Esser。他们都在今年早些时候离开了 Stability AI,有人猜测他们当初离开就是为了自己创业。

目前,该 Labs 已经完成 3100 万美元的种子轮融资,由 Andreessen Horowitz 领投。其他投资者包括了天使投资人 Brendan Iribe、Michael Ovitz、Garry Tan、Timo Aila、Vladlen Koltun 以及一些知名 AI 研究和创业专家。此外还获得了来自 General Catalyst 和 MätchVC 的后续投资。
该 Labs 还成立了顾问委员会,成员包括在内容创作行业具有广泛经验的科技大佬 Michael Ovitz 和神经风格迁移先驱、欧洲开放 AI 研究的顶级专家 Matthias Bethge 教授。
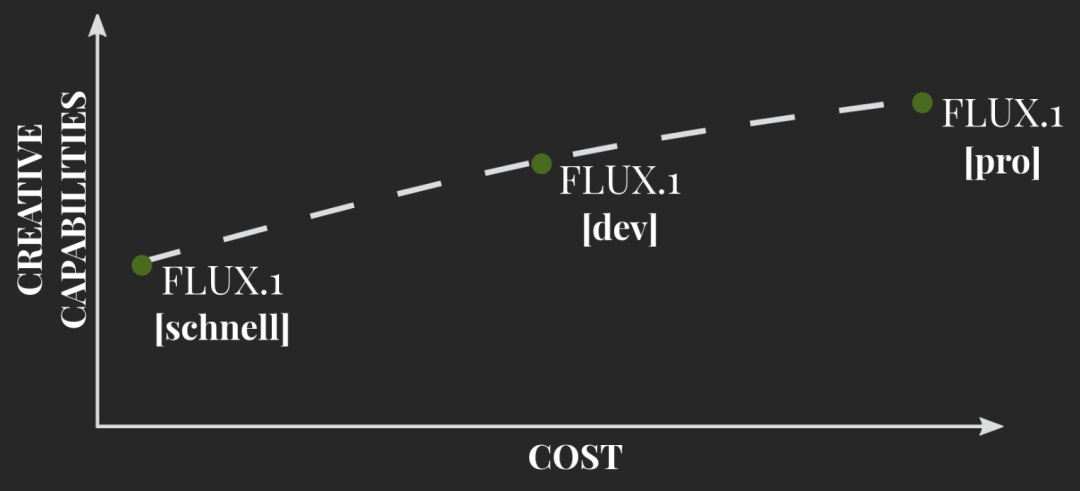
当然,Black Forest Labs 推出了首个模型系列「FLUX.1」,包含了以下三个变体模型。

第一个变体是 FLUX.1 [pro],它是全新的 SOTA 文生图模型,具有极其丰富的图像细节、极强的 prompt 遵循能力和多样化风格。目前可以通过 API 使用。
- API 地址:https://docs.bfl.ml/

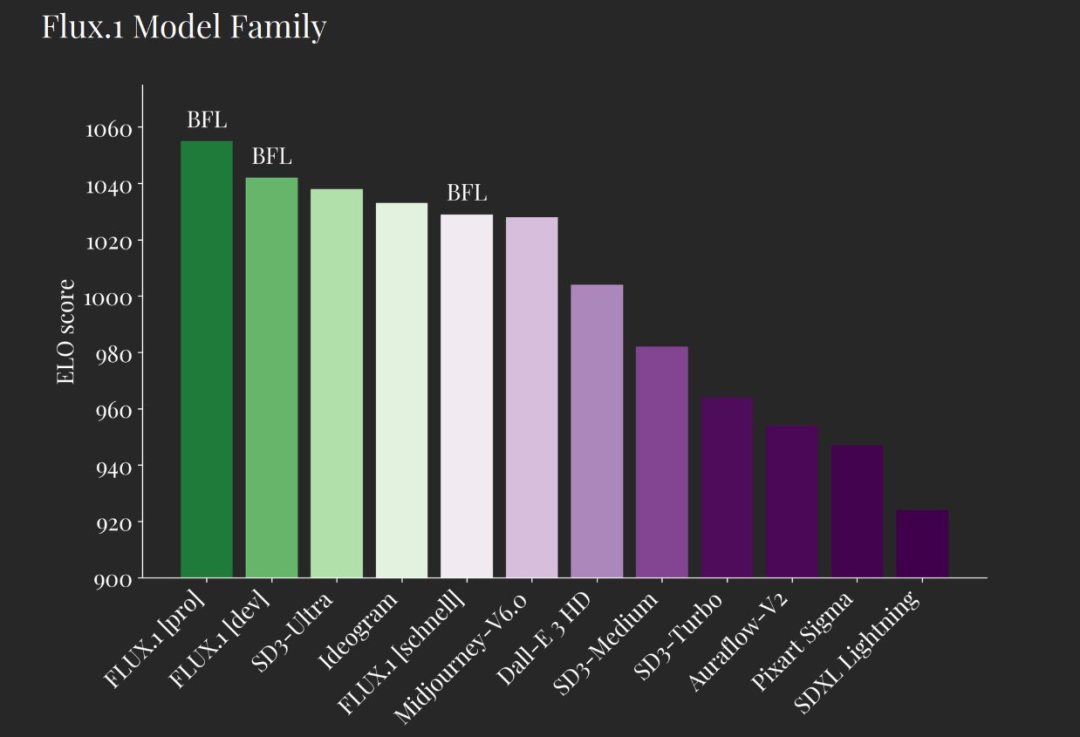
第二个是 FLUX.1 [dev],它是 FLUX.1 [pro] 的开放权重、非商用变体,并直接基于后者蒸馏而成。该模型的表现优于 Midjourney 和 Stable Diffusion 3 等其他图像模型。推理代码和权重已经放在了 GitHub 上。下图是与竞品图像模型的比较。
- GitHub 地址:https://github.com/black-forest-labs/flux
第三个是开源的 FLUX.1 [schnell],它是超高效的 4-step 模型,遵循了 Apache 2.0 协议。该模型在性能上与 [dev]、[pro] 非常接近,可以在 Hugging Face 上使用。
- Hugging Face 地址:https://huggingface.co/black-forest-labs/FLUX.1-schnell

与此同时,Black Forest Labs 也开始宣传自己了。

下一步的目标是推出所有人可用的 SOTA 文生视频模型,大家可以期待一波了!


一出手即王炸:文生图模型系列「FLUX.1」来袭
这次 Black Forest Labs 推出的三款模型,均采用了多模态和并行扩散 Transformer 的混合架构。不同于其他家将一系列模型按参数量分为「中杯」、「大杯」、「超大杯」,FLUX.1 家族的成员统一扩展为 120 亿参数的庞大规模。
研究团队采用了流匹配(Flow Matching)框架对之前 SOTA 扩散模型进行了升级。从官方博客的注释中可以推测,研究团队沿用了还在 Stability AI 任职时(今年 3 月)提出的 Rectified flow+Transformer 方法。

- 论文链接:https://arxiv.org/pdf/2403.03206.pdf
他们还引入了旋转位置嵌入和并行注意力层。这些方法有效提高了模型生成图片的性能,在硬件设备上生成图片的速度也变得更快了。
这次 Black Forest Labs 并未公开模型的详细技术,不过更详细的技术报告将很快公布。
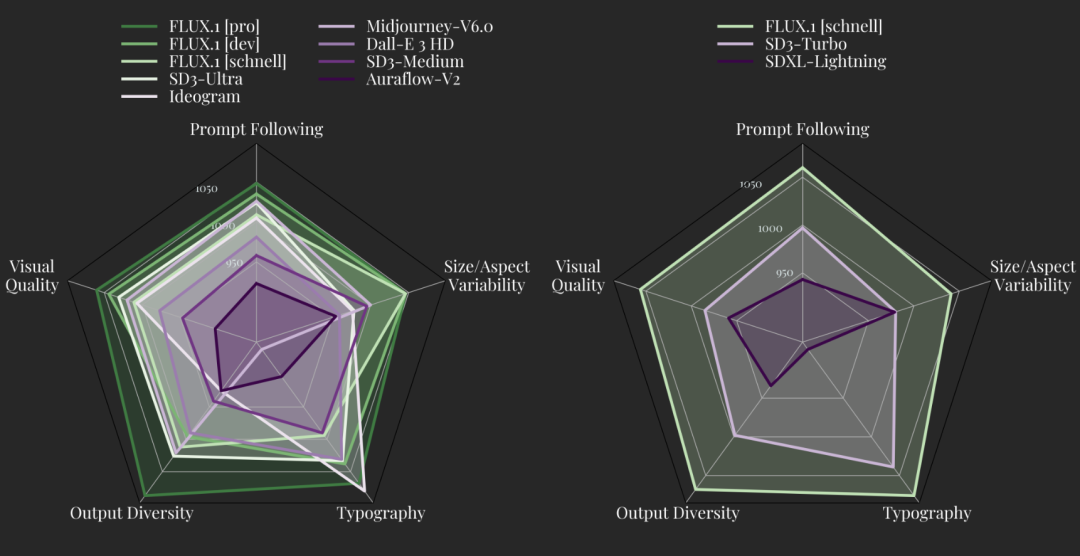
这三款模型在各自的领域都确立了新标准。无论是生成图像的美观度、图像与文本提示词的附和度、尺寸 / 宽高比可变性、还是输出格式的多样性, FLUX.1 [pro] 和 FLUX.1 [dev] 都超越了一系列当红图片生成模型,如 Midjourney v6.0、DALL・E 3 (HD) 以及老东家 SD3-Ultra。
FLUX.1 [schnell] 是迄今为止最先进的少步骤模型(few-step model),不仅超越了同类竞争对手,还超越了像 Midjourney v6.0 和 DALL・E 3 (HD) 这样的强大非蒸馏模型。
模型经过专门微调,以保留预训练阶段的全部输出多样性。与当前最先进的技术相比,FLUX.1 系列模型还保留了充分的进步空间。
所有 FLUX.1 系列的模型都支持多种纵横比和分辨率,从 0.1 到 2 百万像素,都能拿下。

已经有动作快的网友抢先体验上了,看来 Black Forest Labs 反复强调的「最强」,并不只是自卖自夸。
简单的提示词,就可以打造出这样的效果,仔细看羊驼身上垫子的花纹,也没有出现扭曲和变形。
 提示词:An emerald Emu riding on top of a white llama.
提示词:An emerald Emu riding on top of a white llama.
如果不说这是 AI 生成的图片,也挺难分辨这是不是摄影师拍下的照片。
 提示词:A horse is playing with two aligators at the river.
提示词:A horse is playing with two aligators at the river.
含有文字的图像,也能轻松拿捏,景深也处理得很符合真实的镜头感。

三款模型中,性能稍弱的 FLUX.1 [schnell],用起来也是又快又强,有网友晒出在 Mac 上运行的体验,不得不感慨,真是立等可取。
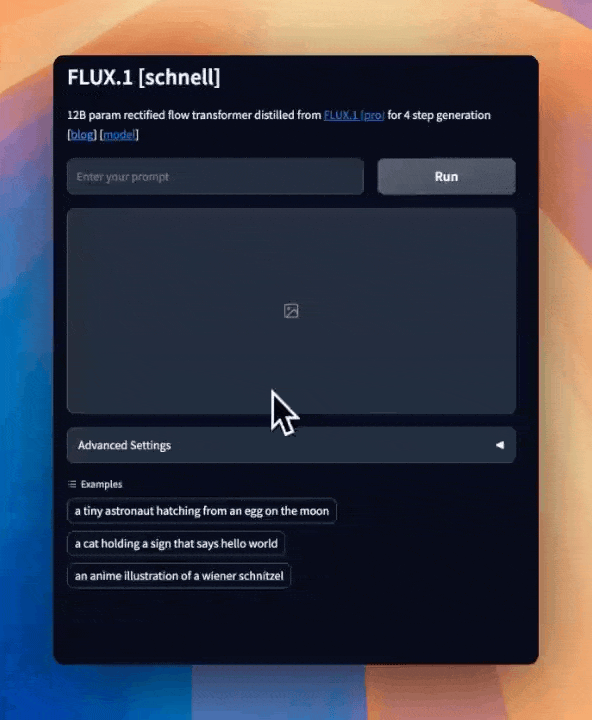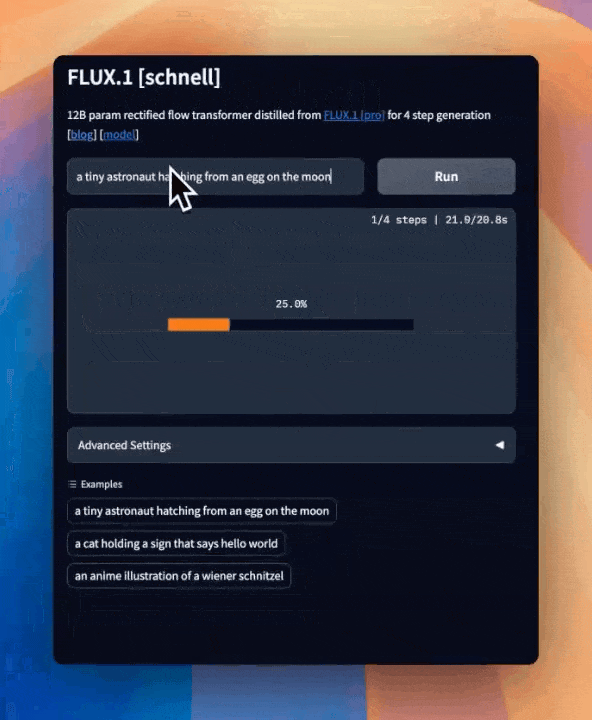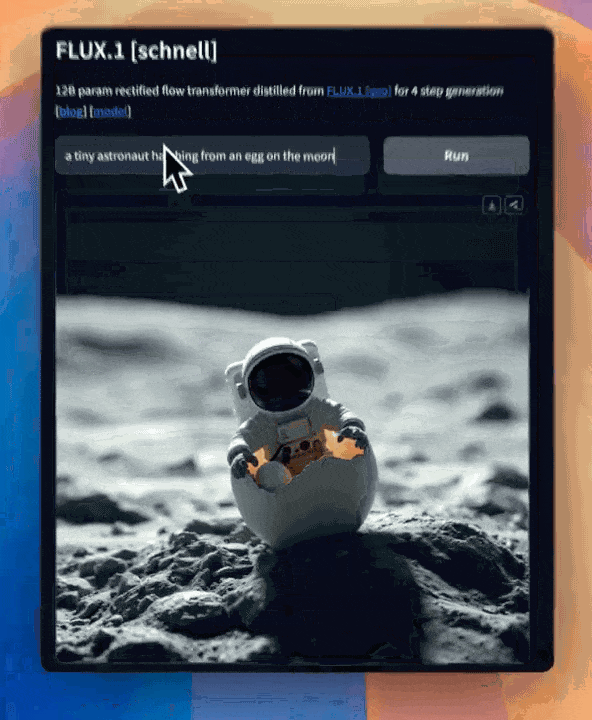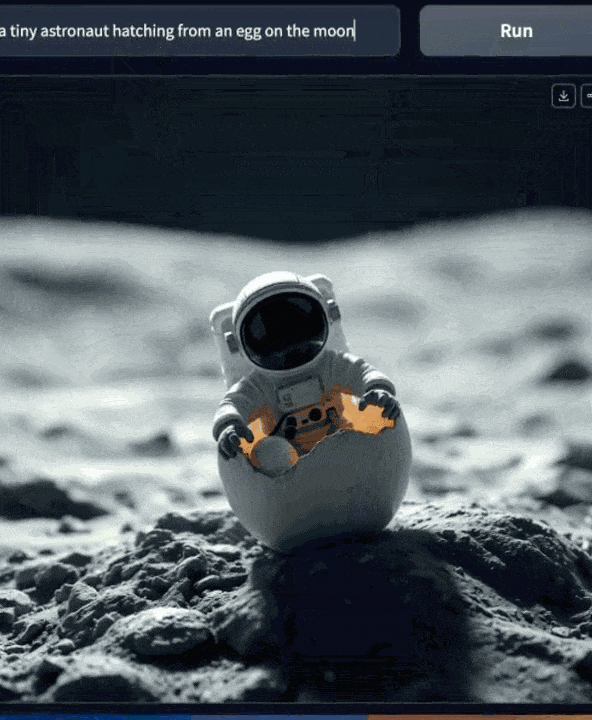
不太了解 Stable Diffusion 的作者们和 Stability AI 之间「恩怨情仇」的网友感叹道:不知道从哪里冒出来了个文生图模型,简直强到可怕。
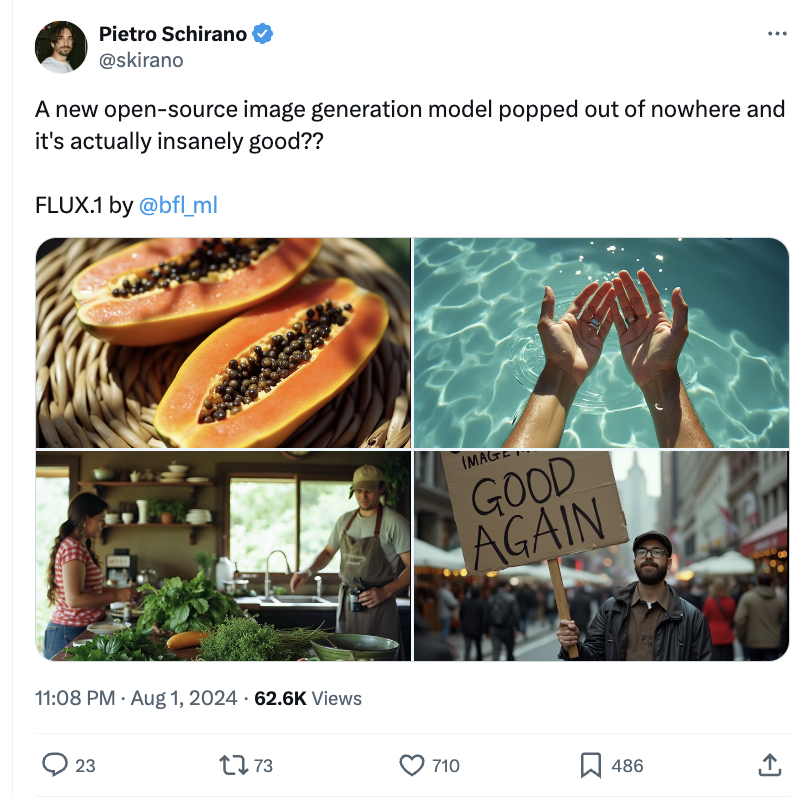
关于 Stable Diffusion 作者和前司 Stability AI 的故事,可以看看机器之心之前的报道:价值1亿美金时,Stable Diffusion背后的团队开始互撕,谁才是真官方?
除了三款最强的文生图模型,Black Forest Labs 还憋着「大招」呢。有了如此强大的图片生成模型的能力,Black Forest Labs 为视频生成模型打下了坚实的基础,正如他们所预告的,这些计算机视觉的顶级科学家们正朝着为所有人提供的最先进文生视频技术的目标前进。