一、监控平台介绍
1.监控平台简述
普罗米修斯四件套,分别为Prometheus、Grafana、Alertmanager、Webhook-DingTalk。
Prometheus一套开源的监控&报警&时间序列数据库的组合,由SoundCloud公司开发,广泛用于云原生环境和容器化应用的监控和性能分析。其提供了通用的数据模型和快捷数据采集、存储和查询接口。它的核心组件Prometheus-server会定期从静态配置的监控目标或者基于服务发现自动配置的自标中进行拉取数据,当新拉取到的数据大于配置的内存缓存区时,数据就会持久化到存储设备当中。
Grafana是一款用Go语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。它主要是用于可视化展示Prometheus存储的数据。
AlertManager是一个开源的告警管理工具,主要用于处理来自于监控系统Prometheus的告警,能够集中管理告警的路由、去重、分组和通知等操作。
Webhook-DingTalk主要支持通过Webhook接口将监控警报信息发送到钉钉群聊中,以便团队成员及时接收和处理警报。它还支持通过设置签名密钥来验证Webhook请求的来源,保障数据安全,同时也提供了自定义模板,可根据不同场景定制警报内容,适应多样化的业务需求。
2.项目功能
整个系统分为三部分:Prometheus指标数据采集存储端、Grafana可视化展示端、Alertmanager+Webhook-DingTalk告警通知端。实现对服务器、数据库、应用服务等资源的指标监控、使用图表可视化展示、使用指标告警等功能,同时通过钉钉机器人告警,把信息实时推送到钉钉群中。
3.项目开源地址
https://prometheus.io
二、平台搭建环境
1. 平台搭建环境
本次实测搭建了两种环境的平台。
A.基于联通云的centos7.6,使用docker-compose搭建,具体搭建内容为Prometheus+Grafana+Alertmanager+Webhook-dingtalk组成监控预警系统,配合组件node_export/nginx_export/mysql_export/redis_export/cadvisor监控业务系统。
B.基于国产云的arm64的KylinOS,使用源码部署并且配置成系统服务管理,具体搭建内容为Prometheus+Grafana+Alertmanager+Webhook-dingtalk/邮件组成监控预警系统,配合组件node_export/nginx_export/dameng_export/redis_export/BES_export监控业务系统。
2. 监控平台实施准备
A方案使用docker下载镜像,创建好平台组件以及需要挂载的路径,通过docker-compose启动容器,启动容器后查看容器启动状态,查看容器的运行日志是否正常。(dingtalk镜像没下载下来,直接安装包启动了)
B方案到prometheus.io下载好对应的普罗米修斯相关组件;达梦使用开源的dmdb_exporter-0.1-alpha,并且基于arm64环境编译好了启动包;宝蓝德内嵌jvm读取宝蓝德这边特有的jar包进行数据采集;全部组件均写入系统服务管理。
三、平台实施过程
A方案.
联通云上的centos7.6配合docker-compose搭建Prometheus+Grafana+Alertmanager+Webhook-dingtalk,监控组件node_export/nginx_export/mysql_export/redis_export/cadvisor
1.创建Prometheus的data和config
mkdir -p ./Prometheus/data ./Prometheus/config
2.创建Prometheus的配置文件
vim ./Prometheus/config/prometheus.yml
global:
# 指定Prometheus抓取应用程序数据的间隔为15秒。
scrape_interval: 15s # By default, scrape targets every 15 seconds.
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'line-monitor'
# 普罗米修斯 规则文件
rule_files:
- "./rules/*.yml"
# prometheus自身的Alert功能是根据我们配置的 规则文件 进行触发的,但是它并没有告警发邮件的功能,发送邮件的这件事儿是由 Alertmanager来做的
alerting:
alertmanagers:
- static_configs:
* - targets:
* - "192.168.1.41:9093"
* scrape_configs:
* # 普罗米修斯节点
* - job_name: 'prometheus'
* static_configs:
* - targets: ['192.168.1.41:9090']
* # tomcat的服务器检测节点
* - job_name: 'node-monitor-142jar'
* static_configs:
* - targets: ['192.168.1.41:9100'] #如部署在生产环境,此ip应为部署node-monitor的服务器ip
* # mysql的服务器检测节点
* - job_name: 'node-monitor-80sql'
* static_configs:
* - targets: ['192.168.1.91:9100'] #如部署在生产环境,此ip应为部署node-monitor的服务器ip
* # mysql的服务器检测节点监控mysql
* - job_name: 'mysql-monitor'
* static_configs:
* - targets: ['192.168.1.91:9104'] #如部署在生产环境,此ip应为部署node-monitor的服务器ip
* # tomcat的服务器检测节点监控redis
* - job_name: 'node-monitor-142redis'
* static_configs:
* - targets: ['192.168.1.41:9121'] #如部署在生产环境,此ip应为部署node-monitor的服务器ip
* # tomcat的服务器检测节点监控nginx
* - job_name: 'node-monitor-142nginx'
* static_configs:
* - targets: ['192.168.1.41:9113'] #如部署在生产环境,此ip应为部署node-monitor的服务器ip
* # tomcat的服务器检测节点监控tomcat
* - job_name: 'node-monitor-142tomcat'
* static_configs:
* - targets: ['192.168.1.41:30018'] #如部署在生产环境,此ip应为部署node-monitor的服务器ip
* - job_name: docker #增加对目标主机的监控
* scrape_interval: 5s
* static_configs:
* - targets: ['192.168.1.41:9200'] #目标主机的地址和端口
* labels:
* instance: docker
* - job_name: 'alertmanager' #增加对预警组件的监控
* scrape_interval: 15s
* static_configs:
* - targets: ['192.168.1.41:9093']
* -----------------------------------------------------------------------------------------------------------------------
* 参数说明:
* global:
* # 指定Prometheus抓取应用程序数据的间隔为15秒。
* scrape_interval: 15s
* external_labels:
* monitor: 'line-monitor'
* # 普罗米修斯,预警在alertmanagers的规则文件
* rule_files:
* - "./rules/*.yml"
* # prometheus本身是没有预警功能的,触发的Alert是根据我们配置文件的,发送邮件、钉钉、企业微信是由alertmanagers
* alerting:
* alertmanagers:
* - static_configs:
* - targets:
* - "192.168.1.41:9093"
* scrape_configs:
* # 普罗米修斯节点
* - job_name: 'prometheus' #显示在普罗米修斯里面的节点名称
* static_configs:
* - targets: ['192.168.1.41:9090'] #这里配置的ip加端口就是让普罗米修斯能够按照ip和端口读到对应的采集数据的插件
* 3.创建Alertmanager的配置文件
* vim ./Prometheus/config/alertmanager.yml
* -----------------------------------------------------------------------------------------------------------------------
* # 全局配置项
* global:
* resolve_timeout: 5m #恢复时候通知时间
* # smtp_smarthost: 'smtphz.qiye.163.com:25' # smtp地址
* smtp_smarthost: 'smtp.qq.com:587'
* smtp_from: '123456@qq.com' # 谁发邮件
* smtp_auth_username: '123456@qq.com' # 邮箱用户
* smtp_auth_password: '123456' # 邮箱客户端授权密码
* smtp_require_tls: false # 进行tls验证
* templates:
* - "/config/email.tmpl" # 定义email预警的模板
* # 定义路由树信息
* route:
* group_by: ['alertname'] # 报警分组依据
* group_wait: 5s # 最初即第一次等待多久时间发送一组警报的通知
* group_interval: 10s # 在发送新警报前的等待时间
* repeat_interval: 1m # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
* receiver: email #默认使用邮件
* routes:
* - receiver: 'email' #邮件优先
* continue: true # 是否继续
* - receiver: 'dingding' #钉钉也需要通知
* receivers: # 接收器列表,定义各种通知渠道如 email、webhook等
* - name: 'email' # 邮件
* email_configs:
* - to: '123456@qq.com' # 接收警报的email配置
* send_resolved: true # 是否发送恢复的消息
* html: '{{ template "email.to.html" . }}' #使用email的预警模板
* - name: 'dingding' #钉钉
* webhook_configs:
* - url: 'http://192.168.1.41:8060/dingtalk/webhook1/send' #这里需要部署钉钉的插件,把ip、端口、webhook1定义的名字改成对应的真实的参数
* send_resolved: true # 是否发送恢复的消息
* inhibit_rules: # inhibit_rules 用于配置告警抑制规则。它可以避免发送无意义的重复告警通知
* - source_match:
* severity: 'critical'
* target_match:
* severity: 'warning'
* equal: ['alertname', 'dev', 'instance']
* -----------------------------------------------------------------------------------------------------------------------
* 4.创建Alertmanager的邮箱预警模板
* vim ./Prometheus/config/email.tmpl
* -----------------------------------------------------------------------------------------------------------------------
* {{ define "email.from" }}xxx.com{{ end }}
* {{ define "email.to" }}xxx.com{{ end }}
* {{ define "email.to.html" }}
* {{- if gt (len .Alerts.Firing) 0 -}}
* {{ range .Alerts }}
* ========= 监控报警 =========<br>
* 告警级别: {{ .Labels.severity }} <br>
* 告警类型: {{ .Labels.alertname }} <br>
* 告警主机: {{ .Labels.instance }} <br>
* 告警主题: {{ .Annotations.summary }} <br>
* 告警详情: {{ .Annotations.description }} <br>
* 触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
* ========= = end = =========<br>
* {{ end }}{{ end -}}
* {{- if gt (len .Alerts.Resolved) 0 -}}
* {{ range .Alerts }}
* ========= 告警恢复 =========<br>
* 告警级别: {{ .Labels.severity }} <br>
* 告警类型: {{ .Labels.alertname }} <br>
* 告警主机: {{ .Labels.instance }} <br>
* 告警主题: {{ .Annotations.summary }} <br>
* 告警详情: {{ .Annotations.description }} <br>
* 触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
* 恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
* ========= = end = =========<br>
* {{ end }}{{ end -}}
* {{- end }
* -----------------------------------------------------------------------------------------------------------------------
* 5.创建Prometheus的预警规则文件
* vim ./Prometheus/config/rules/rules.yml
* -----------------------------------------------------------------------------------------------------------------------
* groups:
* - name: 服务器资源监控
* rules:
* - alert: 密码过期
* expr: user_expire_days_root < 3
* for: 5s
* labels:
* severity: 严重告警
* annotations:
* summary: "{{ $labels.instance }} 密码即将过期, 请尽快处理!"
* description: "{{ $labels.instance }} 密码即将过期,距离过期还有{{ $value }}天"
* - alert: 内存使用率过高
* expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 80
* for: 3m
* labels:
* severity: 严重告警
* annotations:
* summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"
* description: "{{ $labels.instance }}内存使用率超过80%,当前使用率{{ $value }}%."
* - alert: 服务器宕机
* expr: up == 0
* for: 1s
* labels:
* severity: 严重告警
* annotations:
* summary: "{{$labels.instance}} 服务器宕机, 请尽快处理!"
* description: "{{$labels.instance}} 服务器延时超过3分钟,当前状态{{ $value }}. "
* - alert: CPU高负荷
* expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
* for: 1m
* labels:
* severity: 严重告警
* annotations:
* summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"
* description: "{{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%. "
* - alert: 磁盘IO性能
* expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90
* for: 1m
* labels:
* severity: 严重告警
* annotations:
* summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
* description: "{{$labels.instance}} 流入磁盘IO大于90%,当前使用率{{ $value }}%."
* - alert: 网络流入
* expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
* for: 5m
* labels:
* severity: 严重告警
* annotations:
* summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"
* description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."
* - alert: 网络流出
* expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
* for: 5m
* labels:
* severity: 严重告警
* annotations:
* summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"
* description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."
* - alert: TCP连接数
* expr: node_netstat_Tcp_CurrEstab > 10000
* for: 2m
* labels:
* severity: 严重告警
* annotations:
* summary: " TCP_ESTABLISHED过高!"
* description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."
* - alert: 磁盘容量
* expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90
* for: 1m
* labels:
* severity: 严重告警
* annotations:
* summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"
* description: "{{$labels.instance}} 磁盘分区使用大于90%,当前使用率{{ $value }}%."
* -----------------------------------------------------------------------------------------------------------------------
* 6.创建Grafana的data和config
* mkdir -p ./grafana/data ./grafana/config
* 7.创建Grafana的配置文件
* vim ./grafana/config/grafana.ini
* -----------------------------------------------------------------------------------------------------------------------
* [server]
* # Protocol (http, https, h2, socket)
* protocol = https
* #cert_file = /etc/grafana/baidu.cn_bundle.crt
* #cert_key = /etc/grafana/baidu.key
* ;
* ;# This is the minimum TLS version allowed. By default, this value is empty. Accepted values are: TLS1.2, TLS1.3. If nothing is set TLS1.2 would be taken
* ;;min_tls_version = ""
* ;
* ;# The ip address to bind to, empty will bind to all interfaces
* ;;http_addr =
* ;
* ;# The http port to use
* http_port = 3000
* ;
* ;# The public facing domain name used to access grafana from a browser
* domain = www.baidu.com
* ;
* ;# Redirect to correct domain if host header does not match domain
* ;# Prevents DNS rebinding attacks
* ;;enforce_domain = false
* ;
* ;# The full public facing url you use in browser, used for redirects and emails
* ;# If you use reverse proxy and sub path specify full url (with sub path)
* root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana/
* ;
* ;# Serve Grafana from subpath specified in `root_url` setting. By default it is set to `false` for compatibility reasons.
* serve_from_sub_path = true
* ;
* ;# Log web requests
* ;;router_logging = false
* ;
* ;# the path relative working path
* ;;static_root_path = public
* ;
* ;
* [auth.proxy]
* enabled = true
* header_name = X-WEBAUTH-USER
* header_property = username
* auto_sign_up = true
* ;sync_ttl = 60
* whitelist =
* ;headers = Email:X-User-Email, Name:X-User-Name
* # Non-ASCII strings in header values are encoded using quoted-printable encoding
* ;headers_encoded = false
* # Read the auth proxy docs for details on what the setting below enables
* enable_login_token = false
* [smtp]
* enabled = true
* host = smtp.qq.com:587
* user = 123456@qq.com
* password = 123456
* cert_file =
* key_file =
* skip_verify = false
* from_address = 123456@qq.com
* from_name = Grafana
* ehlo_identity =
* startTLS_policy =
* [emails]
* welcome_email_on_sign_up = true
* templates_pattern = emails/*.html, emails/*.txt
* content_types = text/html
* -----------------------------------------------------------------------------------------------------------------------
* 8.因为nginx_export、redis_export、node_export、cadvisor没有什么特殊的设置需要,我就没有挂载出来了,下面提供docker-compose文件内容。使用这个配置文件,请把对应的挂载路径改成自己的路径
* -----------------------------------------------------------------------------------------------------------------------
* services:
* prometheus:
* image: prom/prometheus:latest
* container_name: prometheus
* hostname: prometheus
* restart: always
* ports:
* - 9090:9090
* volumes:
* - /data/prometheus/config:/config
* - /data/prometheus/data/prometheus:/prometheus/data
* - /etc/localtime:/etc/localtime:ro
* - /etc/timezone:/etc/timezone
* command:
* - --config.file=/config/prometheus.yml
* - --web.enable-lifecycle
* alertmanager:
* image: prom/alertmanager:latest
* container_name: altermanager
* hostname: altermanager
* restart: always
* ports:
* - 9093:9093
* volumes:
* - /data/prometheus/config:/config
* - /data/prometheus/data/alertmanager:/alertmanager/data
* - /etc/timezone:/etc/timezone
* - /etc/localtime:/etc/localtime:ro
* command:
* - --config.file=/config/alertmanager.yml
* grafana:
* image: grafana/grafana:latest
* container_name: grafana
* hostname: grafana
* restart: always
* ports:
* - 3000:3000
* volumes:
* - /data/grafana/config:/etc/grafana
* - /data/grafana/data:/var/lib/grafana
* - /etc/localtime:/etc/localtime:ro
* - /etc/timezone:/etc/timezone
* node-exporter:
* image: quay.io/prometheus/node-exporter
* container_name: node-exporter
* hostname: node-exporter
* restart: always
* ports:
* - 9100:9100
* redis_exproter:
* image: oliver006/redis_exporter
* container_name: redis_exporter
* restart: always
* ports:
* - 9121:9121
* environment:
* - REDIS_ADDR=redis://redis:6379
* nginx_exproter:
* image: nginx/nginx-prometheus-exporter
* container_name: nginx_exporter
* hostname: nginx_exporter
* command:
* - -nginx.scrape-uri=https://www.baidu.com/stub_status
* restart: always
* ports:
* - 9113:9113
* cadvisor:
* image: google/cadvisor
* container_name: cadvisor
* ports:
* - 9200:8080
* volumes:
* - /dev/disk/:/dev/disk:ro
* - /data/docker/:/var/lib/docker:ro
* - /sys:/sys:ro
* - /var/run:/var/run:ro
* - /:/rootfs:ro
* - /etc/timezone:/etc/timezone
* -----------------------------------------------------------------------------------------------------------------------
* 9.启动docker-compose
* docker compose up -d
* 启动后会自行下载镜像,下载失败的请使用加速器,如果有下载不了的可以自行翻qiang后去下载。
* ps:如果实在下载不了的,可以在评论区写下邮箱,我把全部的镜像和源码包发过去。
* 10.docker下载完后,可以查看对应的镜像是否下载成功并运行
* docker compose ps
* NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
* altermanager prom/alertmanager:latest "/bin/alertmanager -..." alertmanager 4 days ago Up 4 days 0.0.0.0:9093->9093/tcp, :::9093->9093/tcp
* cadvisor google/cadvisor "/usr/bin/cadvisor -..." cadvisor 4 days ago Up 3 days 0.0.0.0:9200->8080/tcp, :::9200->8080/tcp
* grafana grafana/grafana:latest "/run.sh" grafana 4 days ago Up 4 days 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp
* nginx_exporter nginx/nginx-prometheus-exporter "/usr/bin/nginx-prom..." nginx_exproter 4 days ago Up 4 days 0.0.0.0:9113->9113/tcp, :::9113->9113/tcp
* prometheus prom/prometheus:latest "/bin/prometheus --c..." prometheus 4 days ago Up 4 days 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp
* redis_exporter oliver006/redis_exporter "/redis_exporter" redis_exproter 4 days ago Up 4 days 0.0.0.0:9121->9121/tcp, :::9121->9121/tcp
* mysql-exporter prom/mysqld-exporter "/bin/mysqld_exporter" mysql-exporter 2 months ago Up 2 months 0.0.0.0:9104->9104/tcp, :::9104->9104/tcp
* node-exporter quay.io/prometheus/node-exporter "/bin/node_exporter" node-exporter 2 months ago Up 2 months 0.0.0.0:9100->9100/tcp, :::9100->9100/tcp
* 11.安装钉钉插件
* 先把插件解压到对应目录,然后把webhook做成系统服务去管理
* vim /usr/lib/systemd/system/webhook.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=webhook
* After=network.target
* [Service]
* Type=notify
* ExecStart=/opt/ssjc/webhook/prometheus-webhook-dingtalk --config.file=/opt/ssjc/webhook/config.yml
* Restart=on-failure
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 12.配置钉钉插件
* vim ./config.yml
* -----------------------------------------------------------------------------------------------------------------------
* ## Request timeout
* # timeout: 5s
* ## Uncomment following line in order to write template from scratch (be careful!)
* #no_builtin_template: true
* ## Customizable templates path
* templates:
* - /data/webhook/template.tmpl
* ## You can also override default template using `default_message`
* ## The following example to use the 'legacy' template from v0.3.0
* #default_message:
* # title: '{{ template "legacy.title" . }}'
* # text: '{{ template "legacy.content" . }}'
* ## Targets, previously was known as "profiles"
* targets:
* webhook1:
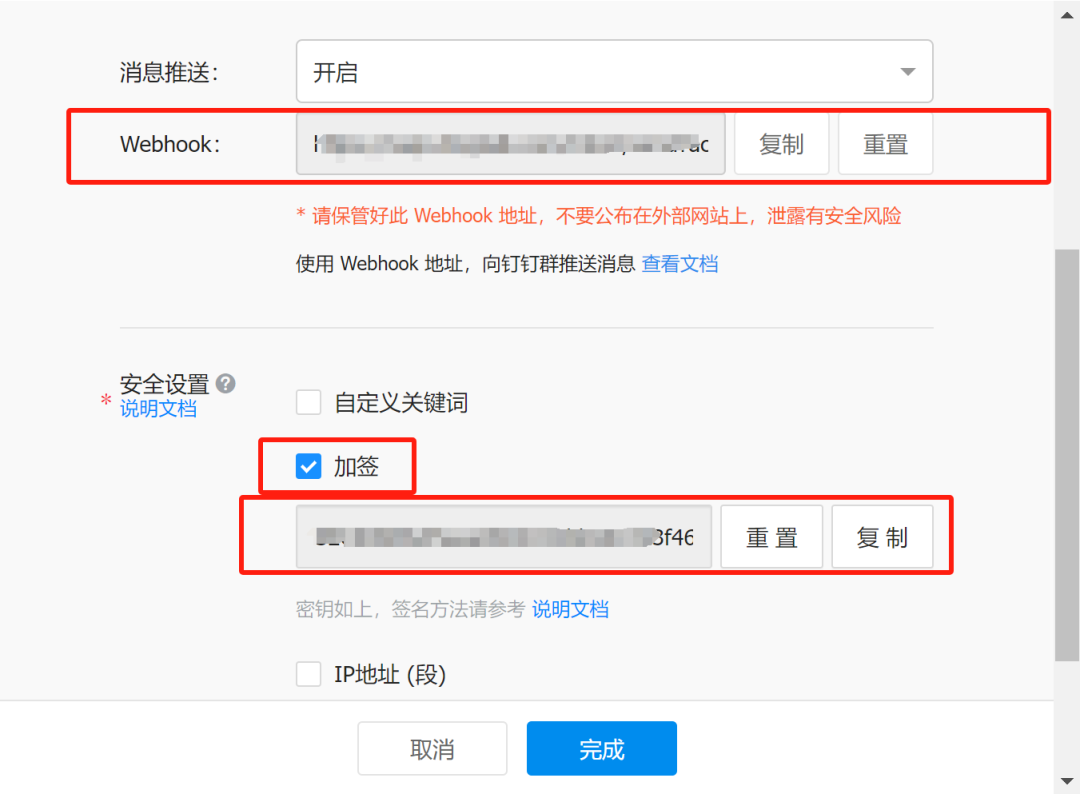
* url: https://oapi.dingtalk.com/robot/send?access_token=123123123 #去钉钉群,开启自定义机器人,勾选"加签",点击完成会生成token地址和secret
* # secret for signature
* secret: 123123123
* -----------------------------------------------------------------------------------------------------------------------
* 13.配置钉钉预警模板
* vim ./template.tmpl
* -----------------------------------------------------------------------------------------------------------------------
* {{ define "__subject" }}
* [{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
* {{ end }}
* {{ define "__alert_list" }}{{ range . }}
* ---
* {{ if .Labels.owner }}@{{ .Labels.owner }}{{ end }}
* **告警主题**: {{ .Annotations.summary }}
* **告警类型**: {{ .Labels.alertname }}
* **告警级别**: {{ .Labels.severity }}
* **告警主机**: {{ .Labels.instance }}
* **告警信息**: {{ index .Annotations "description" }}
* **告警时间**: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
* {{ end }}{{ end }}
* {{ define "__resolved_list" }}{{ range . }}
* ---
* {{ if .Labels.owner }}@{{ .Labels.owner }}{{ end }}
* **告警主题**: {{ .Annotations.summary }}
* **告警类型**: {{ .Labels.alertname }}
* **告警级别**: {{ .Labels.severity }}
* **告警主机**: {{ .Labels.instance }}
* **告警信息**: {{ index .Annotations "description" }}
* **告警时间**: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
* **恢复时间**: {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
* {{ end }}{{ end }}
* {{ define "default.title" }}
* {{ template "__subject" . }}
* {{ end }}
* {{ define "default.content" }}
* {{ if gt (len .Alerts.Firing) 0 }}
* **====侦测到{{ .Alerts.Firing | len }}个故障====**
* {{ template "__alert_list" .Alerts.Firing }}
* ---
* {{ end }}
* {{ if gt (len .Alerts.Resolved) 0 }}
* **====恢复{{ .Alerts.Resolved | len }}个故障====**
* {{ template "__resolved_list" .Alerts.Resolved }}
* {{ end }}
* {{ end }}
* {{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
* {{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}
* {{ template "default.title" . }}
* {{ template "default.content" . }}
* -----------------------------------------------------------------------------------------------------------------------
* 14.配置完成后启动webhook并且查看状态
* systemctl start webhook && systemctl status webhook
* [root@2 prometheus-compose]# systemctl status webhook
* ● webhook.service - Prometheus-Server
* Loaded: loaded (/usr/lib/systemd/system/webhook.service; enabled; vendor preset: disabled)
* Active: active (running) since Tue 2024-07-16 08:42:16 CST; 1 weeks 0 days ago
* Main PID: 24585 (prometheus-webh)
* Tasks: 13
* Memory: 11.5M
* CGroup: /system.slice/webhook.service
* └─24585 /pd_data1/procedure/webhook/prometheus-webhook-dingtalk --config.file=/pd_data1/procedure/webhook/config.yml
* Jul 18 17:12:18 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:12:18.301Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:13:28 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:13:28.267Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:14:38 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:14:38.295Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:15:48 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:15:48.256Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:16:58 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:16:58.209Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:17:18 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:17:18.261Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:44:18 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:44:18.291Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 18 17:45:18 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-18T09:45:18.292Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 19 16:36:18 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-19T08:36:18.114Z caller=entry.go:26 level=info component=web http_scheme=http h...Jul 19 16:38:18 2.novalocal prometheus-webhook-dingtalk[24585]: ts=2024-07-19T08:38:18.265Z caller=entry.go:26 level=info component=web http_scheme=http h...Hint: Some lines were ellipsized, use -l to show in full.
* 15.node节点增加密码过期监控预警设置步骤
* a.先到node监控节点下,创建一个获取用户过期天数的脚本
* cd /opt/ssjc/node_exporter-1.7.0.linux-arm64 && vim user_expire.sh
* -----------------------------------------------------------------------------------------------------------------------
* #!/bin/bash
* # 定义一个用户列表,用空格分隔
* user_list="root"
* # 定义一个输出文件的路径
* output_file="/pd_data1/procedure/node_exporter-1.8.2.linuxamd64/user_expire.prom"
* # 清空输出文件的内容
* echo "" > $output_file
* today=$(date +%s)
* # 遍历用户列表
* for user in $user_list; do
* # 获取账户名为 user 的过期时间
* user_expire_date=$(chage -l $user | grep "Password expires" | cut -d: -f2)
* # 如果账户永不过期,返回 -99999
* if [ "$user_expire_date" = " never" ]; then
* user_expire_day=99999
* else
* # 否则,将过期日期转换为秒
* user_expire_day=$(date -d "$user_expire_date" +%s)
* # 返回过期天数
* expiration=$(date -d "$user_expire_date" +%s)
* user_expire_days=$[(expiration-today)/86400]
* fi
* # 将结果追加到输出文件中,指标名为 user_expire_seconds_user
* echo "user_expire_day_$user $user_expire_day" >> $output_file
* echo "user_expire_days_$user $user_expire_days" >> $output_file
* done
* -----------------------------------------------------------------------------------------------------------------------
* b.给执行权限
* chmod +x ./user_expire.sh
* c.增加定时任务,到最底下加一行
* 输入crontab -e
* * * * * * /opt/ssjc/node_exporter-1.7.0.linux-arm64/user_expire.sh
* d.重启node节点
* cd /opt/ssjc/node_exporter-1.7.0.linux-arm64 && nohup ./node_exporter --collector.textfile.directory=/data/node_exporter-1.8.2.linux-amd64/ > nohup.out 2>&1 &
* 看到以下数据即可
* user_expire_day_root 1.7214048e+09
* # HELP user_expire_days_root Metric read from /opt/ssjc/node_exporter-
* 1.7.0.linux-arm64/user_expire.prom
* # TYPE user_expire_days_root untyped
* user_expire_days_root 1
* e.由于在dockercompose上我是没有把node挂载出来,为了方便我直接把node节点down掉,然后重新使用源码包开了一个新的node节点然后使用系统服务去控制它
*
* 16.至此A方案上使用的docker-compose搭建Prometheus+Grafana+Alertmanager+Webhook-dingtalk,监控组件node_export/nginx_export/mysql_export/redis_export/cadvisor已经全部部署完成。
B方案.
* 1.启动Prometheus,修改对应的配置文件(prometheus.yml),配置内容跟上面A方案的基本一致,此处不再重写。
* [root@master prometheus]# ll
* total 232912
* drwxr-xr-x 5 1001 docker 181 Jul 23 15:16 .
* drwxrwxrwx 8 root root 145 Jul 19 18:00 ..
* -rw------- 1 root root 1137 Jul 22 15:45 backup.rules
* drwxr-xr-x 2 1001 docker 38 Nov 16 2023 console_libraries
* drwxr-xr-x 2 1001 docker 173 Nov 16 2023 consoles
* drwx------ 28 root root 4096 Jul 23 15:00 data
* -rw-r--r-- 1 1001 docker 11357 Nov 16 2023 LICENSE
* -rw------- 1 root root 20965 Feb 21 15:00 nohup.out
* -rw-r--r-- 1 1001 docker 3773 Nov 16 2023 NOTICE
* -rwxr-xr-x 1 1001 docker 122087953 Nov 16 2023 prometheus
* -rw-r--r-- 1 1001 docker 6711 Jul 22 17:24 prometheus.yml
* -rwxr-xr-x 1 1001 docker 116351173 Nov 16 2023 promtool
* 加入系统服务管理
* vim /usr/lib/systemd/system/prometheus.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=Prometheus Monitoring System
* Documentation=Prometheus Monitoring System
* [Service]
* ExecStart=/opt/ssjc/prometheus/prometheus --config.file=/opt/ssjc/prometheus/prometheus.yml --web.listen-address=:8088 --storage.tsdb.path=/opt/ssjc/prometheus/data
* Restart=on-failure
* ExecReload=/bin/kill -HUP $MAINPID
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对prometheus进行管理
* systemctl start/restart/status prometheus
* 2.启动Alertmanager,修改对应的配置文件(alertmanager.yml、email.tmpl、rules.yml),配置内容跟上面A方案的基本一致,此处不再重写。
* [root@master alertmanager]# ll
* total 64032
* drwxr-xr-x 3 1001 1002 140 Jul 23 10:05 .
* drwxrwxrwx 8 root root 145 Jul 19 18:00 ..
* -rwxr-xr-x 1 1001 1002 36231984 Feb 28 19:48 alertmanager
* -rw-r--r-- 1 1001 1002 1501 Jul 22 15:11 alertmanager.yml
* -rwxr-xr-x 1 1001 1002 29302849 Feb 28 19:49 amtool
* drwx------ 2 root root 35 Jul 23 15:26 data
* -rw------- 1 root root 1163 Jul 16 11:25 email.tmpl
* -rw-r--r-- 1 1001 1002 11357 Feb 28 19:55 LICENSE
* -rw-r--r-- 1 1001 1002 457 Feb 28 19:55 NOTICE
* -rw------- 1 root root 3639 Jul 19 22:49 rules.yml
* 加入系统服务管理
* vim /usr/lib/systemd/system/alertmanager.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=alertmanager server daemon
* After=network.target
* [Service]
* ExecStart=/opt/ssjc/alertmanager/alertmanager --config.file=/opt/ssjc/alertmanager/alertmanager.yml --storage.path=/opt/ssjc/alertmanager/data
* User=root
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对alertmanager进行管理
* systemctl start/restart/status alertmanager
* 3.启动grafana
* [root@master system]# ll /opt/ssjc/grafana/
* total 72
* drwx------ 11 root root 227 Feb 21 09:59 .
* drwxrwxrwx 8 root root 145 Jul 19 18:00 ..
* drwxr-xr-x 2 root root 62 Nov 20 2023 bin
* drwxr-xr-x 3 root root 107 Feb 21 09:51 conf
* drwx------ 7 root root 88 Jul 23 15:26 data
* -rw-r--r-- 1 root root 5436 Nov 20 2023 Dockerfile
* drwx------ 3 root root 21 Feb 21 09:43 docs
* -rw-r--r-- 1 root root 34523 Nov 20 2023 LICENSE
* -rw-r--r-- 1 root root 105 Nov 20 2023 NOTICE.md
* drwxr-xr-x 2 root root 254 Nov 20 2023 npm-artifacts
* drwx------ 6 root root 58 Feb 21 09:43 packaging
* drwxr-xr-x 3 root root 78 Nov 20 2023 plugins-bundled
* drwxr-xr-x 16 root root 286 Nov 20 2023 public
* -rw-r--r-- 1 root root 3157 Nov 20 2023 README.md
* drwxr-xr-x 7 root root 12288 Nov 20 2023 storybook
* -rw-r--r-- 1 root root 8 Nov 20 2023 VERSION
* 加入系统服务管理
* vim /usr/lib/systemd/system/grafana-server.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=Grafana
* After=network.target
* [Service]
* Type=notify
* ExecStart=/opt/ssjc/grafana/bin/grafana-server -homepath /opt/ssjc/grafana
* Restart=on-failure
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对alertmanager进行管理
* systemctl start/restart/status grafana-server
* 4.启动webhook,修改对应的配置文件(config.yml、template.tmpl),配置内容跟上面A方案的基本一致,此处不再重写。
* [root@master system]# ll /opt/ssjc/webhook/
* total 18208
* drwxr-xr-x 3 3434 3434 136 Jul 16 13:37 .
* drwxrwxrwx 8 root root 145 Jul 19 18:00 ..
* -rw-r--r-- 1 3434 3434 1299 Apr 21 2022 config.example.yml
* -rwxr-xr-x 1 root root 1517 Jul 16 13:37 config.yml
* drwxr-xr-x 4 3434 3434 34 Apr 21 2022 contrib
* -rw-r--r-- 1 3434 3434 11358 Apr 21 2022 LICENSE
* -rwxr-xr-x 1 3434 3434 18618130 Apr 21 2022 prometheus-webhook-dingtalk
* -rwxr-xr-x 1 root root 1740 Jul 16 10:39 template.tmpl
* 加入系统服务管理
* vim /usr/lib/systemd/system/webhook.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=webhook
* After=network.target
* [Service]
* Type=notify
* ExecStart=/opt/ssjc/webhook/prometheus-webhook-dingtalk --config.file=/opt/ssjc/webhook/config.yml
* Restart=on-failure
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对webhook进行管理
* systemctl start/restart/status webhook
* 5.启动node_export
* [root@master system]# ll /opt/ssjc/node_exporter-1.7.0.linux-arm64/
* total 27452
* drwxr-xr-x 2 1001 1002 119 Jul 18 18:12 .
* drwxrwxrwx 8 root root 145 Jul 19 18:00 ..
* -rw-r--r-- 1 1001 1002 11357 Nov 13 2023 LICENSE
* -rwxr-xr-x 1 1001 1002 19101790 Nov 13 2023 node_exporter
* -rw------- 1 root root 8950860 Jul 23 15:38 nohup.out
* -rw-r--r-- 1 1001 1002 463 Nov 13 2023 NOTICE
* -rwx------ 1 root root 51 Jul 23 15:39 user_expire.prom
* -rwx------ 1 root root 987 Jul 18 17:50 user_expire.sh
* 加入系统服务管理
* vim /usr/lib/systemd/system/node_exporter.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=node_exporter
* After=network.target
* [Service]
* Type=notify
* ExecStart=/opt/ssjc/node_exporter-1.7.0.linux-arm64/node_exporter --collector.textfile.directory=/opt/ssjc/node_exporter-1.7.0.linux-arm64/
* Restart=on-failure
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对node_exporter进行管理
* systemctl start/restart/status node_exporter
* 6.启动node_export
* [root@master system]# ll /opt/ssjc/node_exporter-1.7.0.linux-arm64/
* total 27452
* drwxr-xr-x 2 1001 1002 119 Jul 18 18:12 .
* drwxrwxrwx 8 root root 145 Jul 19 18:00 ..
* -rw-r--r-- 1 1001 1002 11357 Nov 13 2023 LICENSE
* -rwxr-xr-x 1 1001 1002 19101790 Nov 13 2023 node_exporter
* -rw------- 1 root root 8950860 Jul 23 15:38 nohup.out
* -rw-r--r-- 1 1001 1002 463 Nov 13 2023 NOTICE
* -rwx------ 1 root root 51 Jul 23 15:39 user_expire.prom
* -rwx------ 1 root root 987 Jul 18 17:50 user_expire.sh
* 加入系统服务管理
* vim /usr/lib/systemd/system/node_exporter.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=node_exporter
* After=network.target
* [Service]
* Type=notify
* ExecStart=/opt/ssjc/node_exporter-1.7.0.linux-arm64/node_exporter --collector.textfile.directory=/opt/ssjc/node_exporter-1.7.0.linux-arm64/
* Restart=on-failure
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对node_exporter进行管理
* systemctl start/restart/status node_exporter
* 7.启动redis_export
* [root@host-192-168-2-92 redis_exporter]# ll
* total 8356
* drwxr-xr-x 2 root root 60 Jul 19 18:04 .
* drwxrwxrwx 5 root root 4096 Jul 19 18:01 ..
* -rw-r--r-- 1 root root 1063 Oct 20 2021 LICENSE
* -rw-r--r-- 1 root root 25031 Oct 20 2021 README.md
* -rwxr-xr-x 1 root root 8519680 Oct 20 2021 redis_exporter
* 加入系统服务管理
* vim /usr/lib/systemd/system/redis_exporter.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=redis_exporter
* After=network.target
* [Service]
* Type=notify
* ExecStart=/opt/ssjc/redis_exporter/redis_exporter -redis.addr 192.168.2.92:6379 -redis.password 111111
* Restart=on-failure
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对redis_exporter进行管理
* systemctl start/restart/status redis_exporter
* 8.启动dmdb_exporter
* [root@host-192-168-2-92 dmdb_exporter-0.1-alpha]# ll
* total 23372
* drwxrwxr-x 4 root root 251 Jul 17 01:13 .
* drwxrwxrwx 5 root root 4096 Jul 19 18:01 ..
* -rw-rw-r-- 1 root root 1180 Sep 16 2020 default-metrics.toml
* drwxrwxr-x 6 root root 4096 Sep 16 2020 dm
* -rwx------ 1 root root 23825411 Jul 17 01:13 dmdb_exporter
* -rw-rw-r-- 1 root root 520 Sep 16 2020 Dockerfile
* -rw-rw-r-- 1 root root 319 Sep 16 2020 .gitignore
* -rw-rw-r-- 1 root root 291 Sep 16 2020 go.mod
* -rw-rw-r-- 1 root root 41346 Sep 16 2020 go.sum
* drwxrwxr-x 2 root root 99 Sep 16 2020 .idea
* -rw-rw-r-- 1 root root 13721 Sep 16 2020 main.go
* -rw-rw-r-- 1 root root 338 Sep 16 2020 metric-dual-example.toml
* -rw-rw-r-- 1 root root 497 Sep 16 2020 multi-metric-dual-example-labels.toml
* -rw-rw-r-- 1 root root 8327 Sep 16 2020 README.md
* 配置文件default-metrics.toml,写了需要查询的表空间,其他需要加的话自己写sql
* -----------------------------------------------------------------------------------------------------------------------
* [[metric]]
* context = "tablespace"
* labels = [ "tablespace_name" ]
* metricsdesc = { free_space = "Generic counter metric of tablespaces free space MB in DmService.", total_space = "Generic counter metric of tablespaces total space MB in DmService.", free_percent = "Generic counter metric of tablespaces free percent in DmService." }
* request = '''
* select
* t.name tablespace_name,
* sum(d.free_size*SF_GET_PAGE_SIZE()/1024/1024) free_space,
* sum(d.total_size*SF_GET_PAGE_SIZE()/1024/1024) total_space,
* sum(d.free_size*100)/sum(d.total_size) free_percent
* from
* v$tablespace t,
* v$datafile d
* where
* t.id=d.group_id
* group by t.name;
* '''
* -----------------------------------------------------------------------------------------------------------------------
* 加入系统服务管理
* vim /usr/lib/systemd/system/dmdb_exporter.service
* -----------------------------------------------------------------------------------------------------------------------
* [Unit]
* Description=dmdb_exporter
* After=network.target
* [Service]
* # 配置环境变量
* Environment=DATA_SOURCE_NAME=dm://sysdba:123456@localhost:5236?autoCommit=true
* # 启动脚本
* ExecStart=/opt/dmdb_exporter-0.1-alpha/dmdb_exporter --log.level=info --default.metrics=/opt/dmdb_exporter-0.1-alpha/default-metrics.toml --web.listen-address=:9161
* Restart=always
* RestartSec=5
* StartLimitInterval=0
* StartLimitBurst=10
* [Install]
* WantedBy=multi-user.target
* -----------------------------------------------------------------------------------------------------------------------
* 对dmdb_exporter进行管理
* systemctl start/restart/status dmdb_exporter
* ps:达梦的这个开源插件需要使用go环境编译
* # 进入dmdb_exporter目录
* go build -o dmdb_exporter
*
* 9.至此B方案上基于国产云的arm64的KylinOS,使用源码部署并且配置成系统服务管理,具体搭建内容为Prometheus+Grafana+Alertmanager+Webhook-dingtalk/邮件组成监控预警系统,配合组件node_export/nginx_export/dameng_export/redis_export/BES_export监控业务系统。已经全部部署完成。
四、平台使用
* 1.Prometheus
* 使用ip加9090访问
*
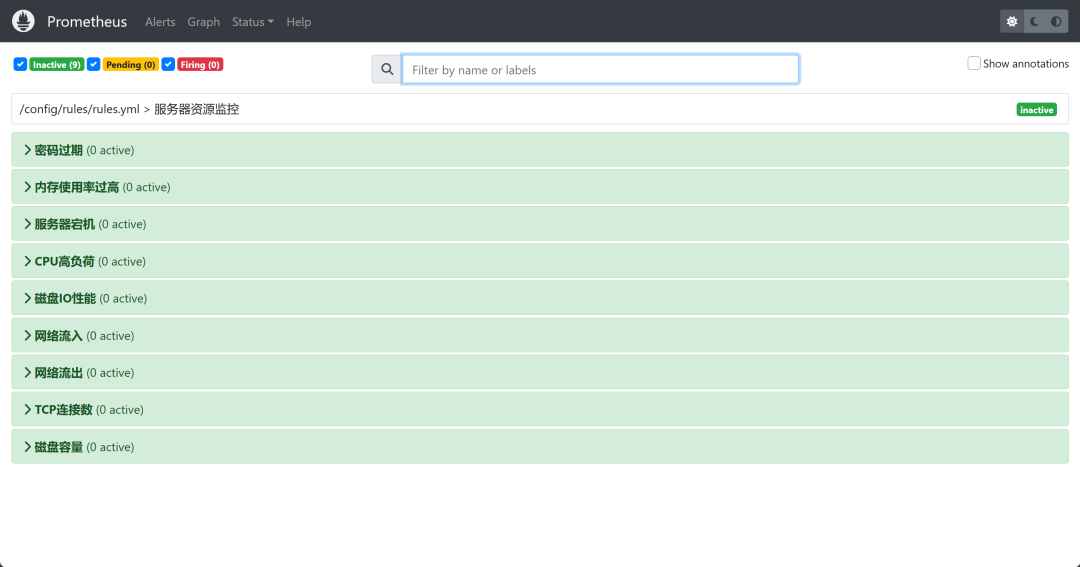
* a.点击Alerts,显示的是/config/rules/rules.yml > 服务器资源监控,显示的是你预警的规则
* 如:
* name: 密码过期
* expr: user_expire_days_root < 3
* for: 5s
* labels:
* severity: 严重告警
* annotations:
* description: {{ $labels.instance }} 密码即将过期,距离过期还有{{ $value }}天
* summary: {{ $labels.instance }} 密码即将过期, 请尽快处理!
*
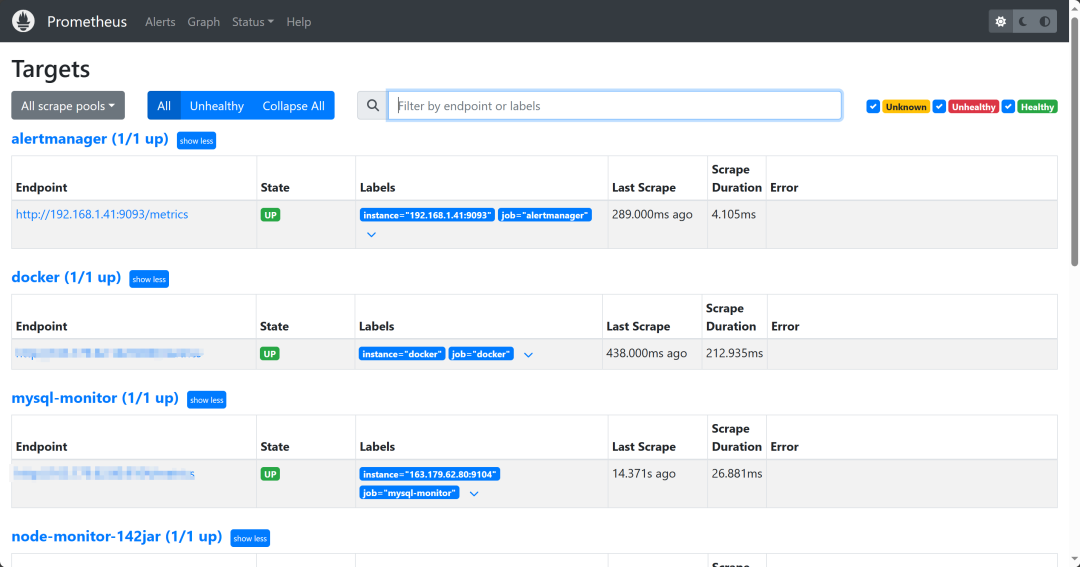
* b.点击status下的targets,会显示当前普罗米修斯配置文件内监控的节点
* 如:
* alertmanager (0/1 up)
* alertmanager (1/1 up)
*
* c.点击graph,可以自定义查询key-value,并且可以显示这个值的趋势图表
* 如:
* mysql_global_variables_sql_quote_show_create{instance="192.168.1.23:9104", job="mysql-monitor"}
*
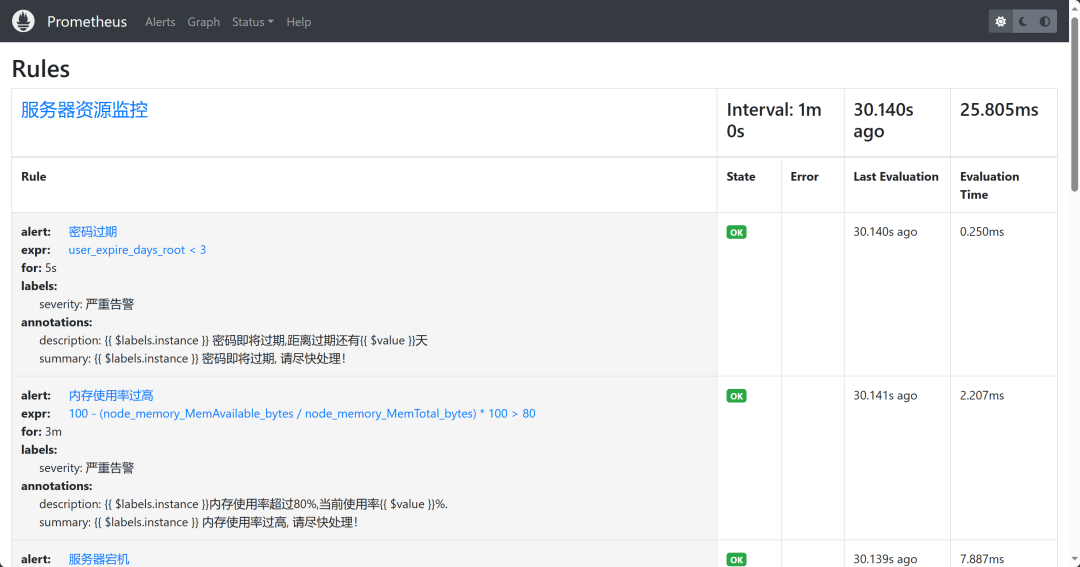
* d.点击status下的rules,会显示当前预警规则的配置文件内容
* 如:
* alert:CPU高负荷
* expr:100 - (avg by (instance, job) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
* for: 1m
* labels:
* severity: 严重告警
* annotations:
* description: {{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%.
* summary: {{$labels.instance}} CPU使用率过高,请尽快处理!
*
* 2.Grafana
* 使用ip加3000访问
*
* 先到datasource里面去连接prometheus\redis等,然后常用的grafana的模板如下:
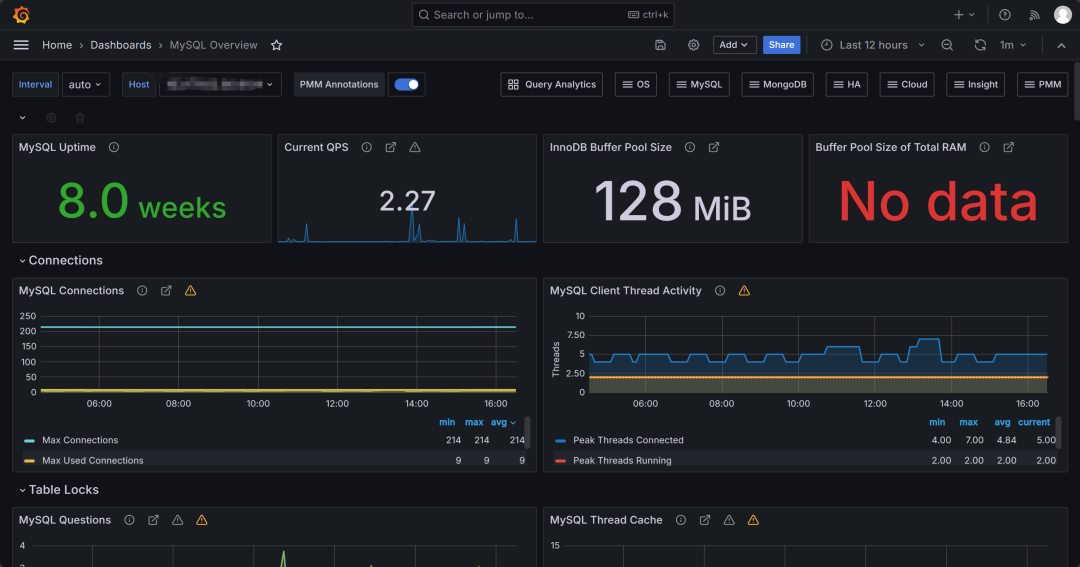
* mysql使用7236、11323;
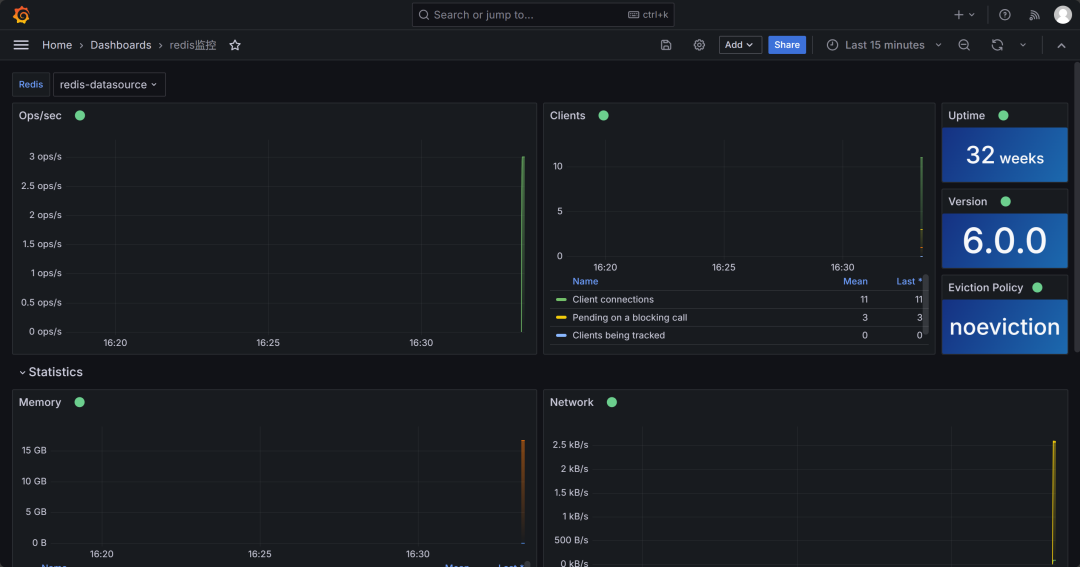
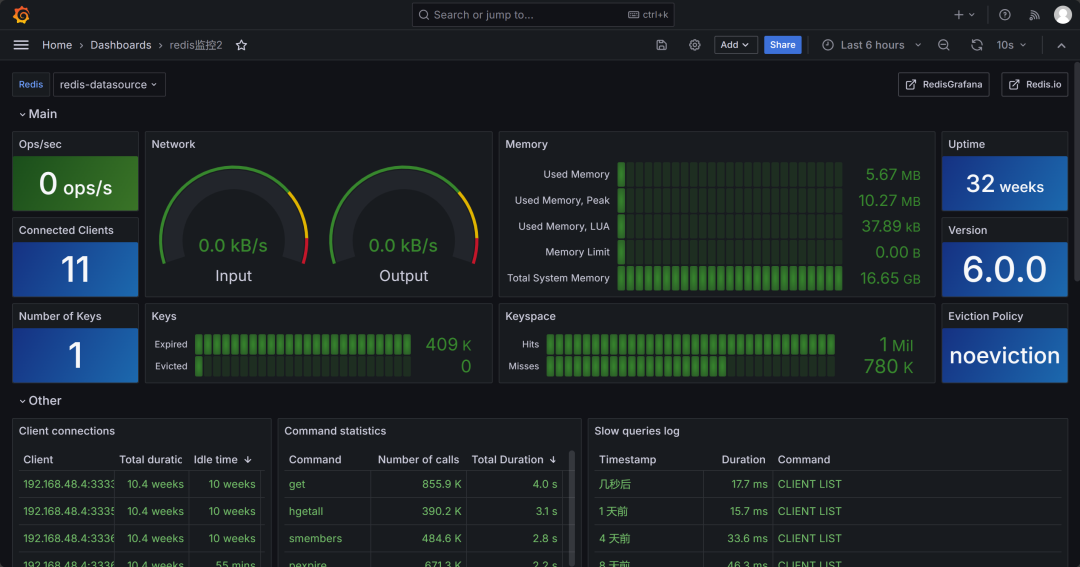
* redis连接后使用自带的模板;
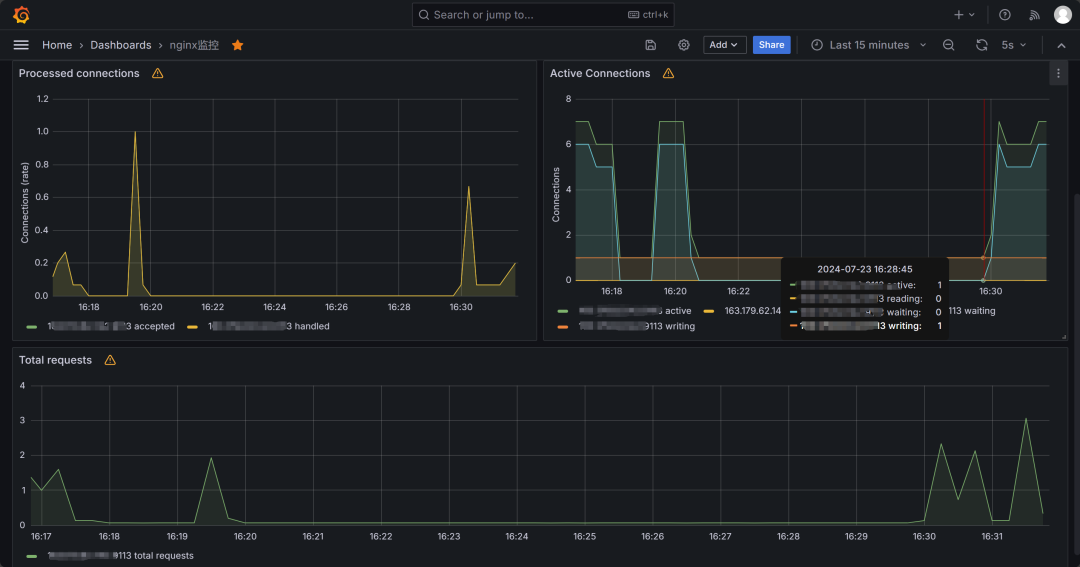
* nginx使用12708;
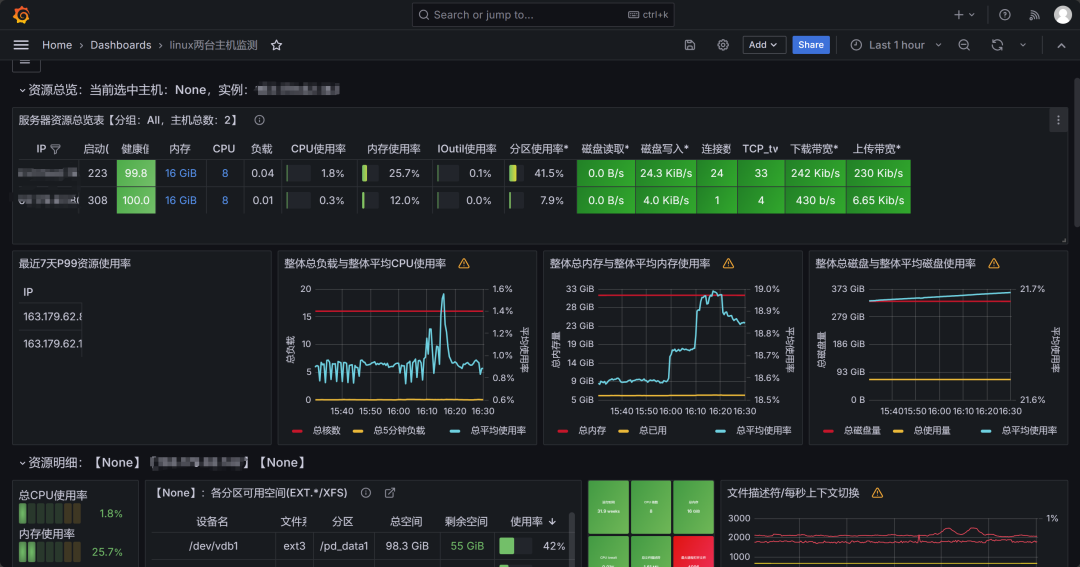
* linux使用8919;
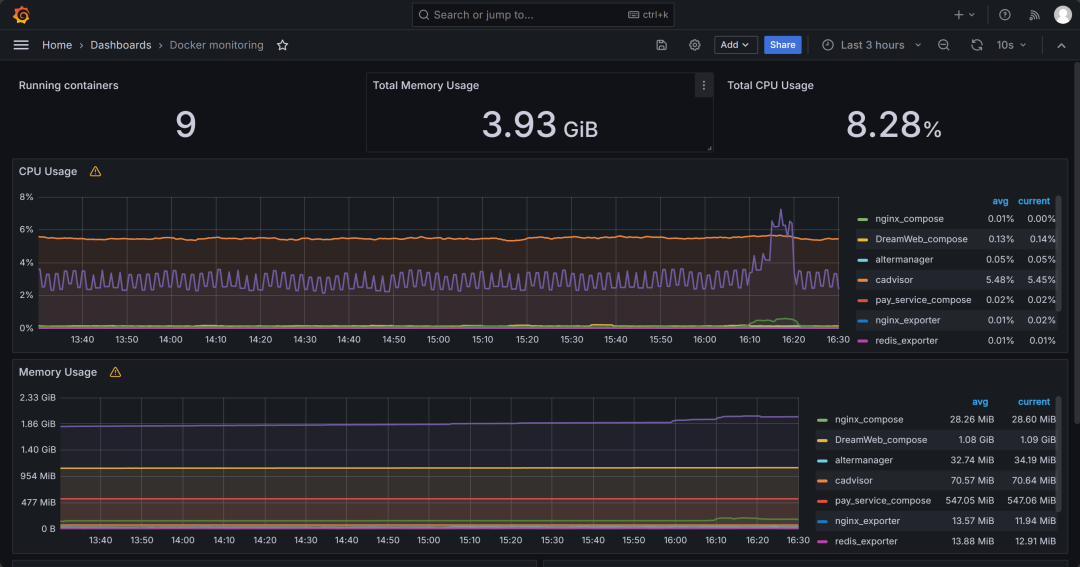
* docker监控使用193;
* 达梦使用19109;
*
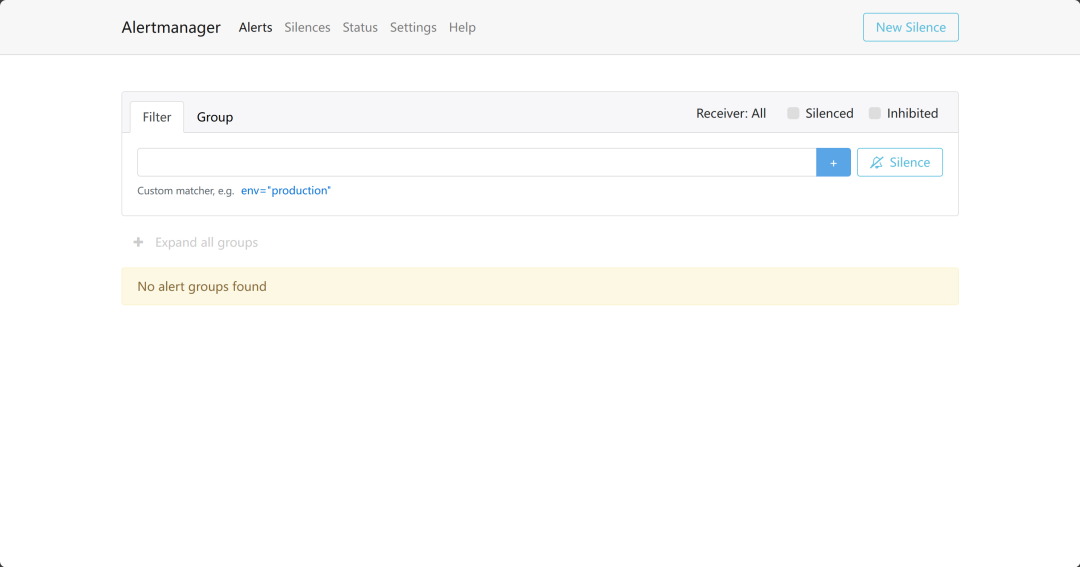
* 3.Alertmanager
* 使用ip加9093访问
*
* 首页显示的Alerts界面,如果有预警的内容,可以看到具体是哪个服务器发出的预警
*
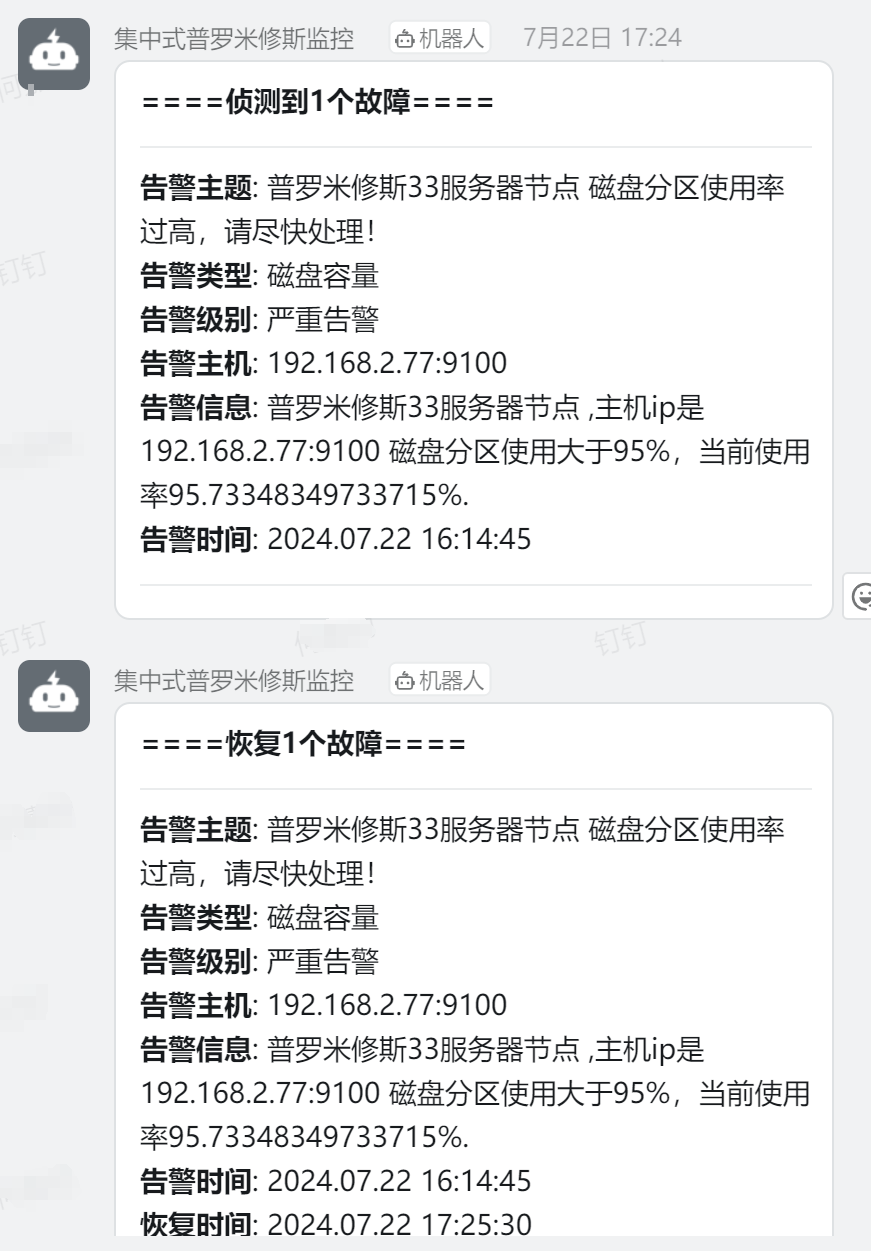
* 4.dingtalk和邮件
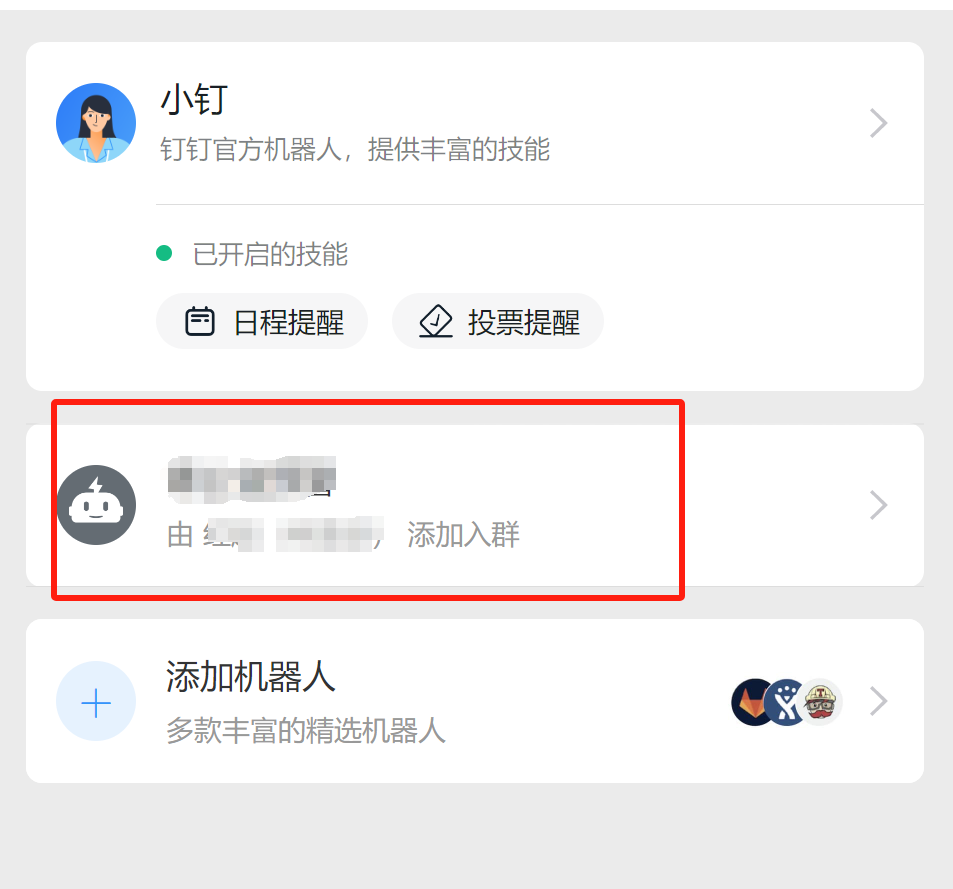
* 在钉钉群的机器人,添加自定义机器人,通过webhook接入自定义服务。
* 邮件需要先开启运维邮件smtp以及相关授权码
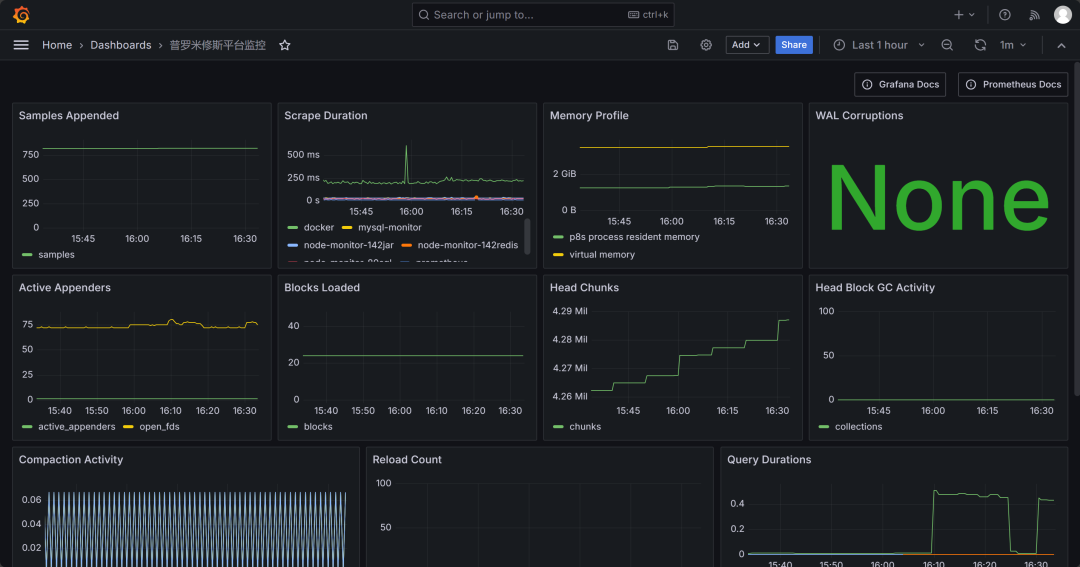
五、监控平台模拟图