Spring Data 框架集成 {#Spring-Data-框架集成}
Spring Data 框架介绍 {#Spring-Data-框架介绍}
Spring Data 是一个用于简化数据库、非关系型数据库、索引库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持 map-reduce 框架和云计算数据服务。 Spring Data 可以极大的简化 JPA(Elasticsearch......)的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了 CRUD 外,还包括如分页、排序等一些常用的功能。
Spring Data 的官网:https://spring.io/projects/spring-data
Spring Data 常用的功能模块如下:
Spring Data Elasticsearch 介绍 {#Spring-Data-Elasticsearch-介绍}
Spring Data Elasticsearch 基于 spring data API 简化 Elasticsearch 操作,将原始操作Elasticsearch 的客户端 API 进行封装 。Spring Data 为 Elasticsearch 项目提供集成搜索引擎。Spring Data Elasticsearch POJO 的关键功能区域为中心的模型与 Elastichsearch 交互文档和轻松地编写一个存储索引库数据访问层。
官方网站:https://spring.io/projects/spring-data-elasticsearch

Spring Data Elasticsearch 版本对比 {#Spring-Data-Elasticsearch-版本对比}
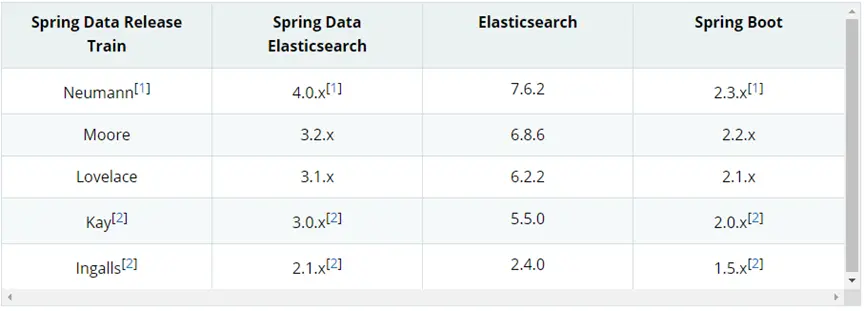
目前最新 springboot 对应 Elasticsearch7.6.2,Spring boot2.3.x 一般可以兼容 Elasticsearch7.x
框架集成 {#框架集成}
- 创建Maven项目
- 修改pom文件,增加依赖关系
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.6.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.atguigu</groupId>
<artifactId>es</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
</dependency>
</dependencies>
`</project>
`
- 增加配置文件
在resources目录中增加application.properties文件
# es服务地址
elasticsearch.host=127.0.0.1
# es服务端口
elasticsearch.port=9200
# 配置日志级别,开启debug日志
logging.level.com.atguigu.es=debug
- SpringBoot 主程序
@SpringBootApplication
public class SpringDataElasticSearchMainApplication {
public static void main(String[] args) {
SpringApplication.run(SpringDataElasticSearchMainApplication.class,args);
}
}
- 数据实体类
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
`@Data
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Document(indexName = "product", shards = 3, replicas = 1)
public class Product {
@Id
private Long id;//商品唯一标识
@Field(type = FieldType.Text)
private String title;//商品名称
@Field(type = FieldType.Keyword)
private String category;//分类名称
@Field(type = FieldType.Double)
private Double price;//商品价格
@Field(type = FieldType.Keyword, index = false)
private String images;//图片地址
}
`
- 配置类
- ElasticsearchRestTemplate 是 spring-data-elasticsearch 项目中的一个类,和其他 spring 项目中的 template类似。
- 在新版的 spring-data-elasticsearch 中,ElasticsearchRestTemplate 代替了原来的 ElasticsearchTemplate。
- 原因是 ElasticsearchTemplate 基于 TransportClient,TransportClient 即将在 8.x 以后的版本中移除。所以,我们推荐使用 ElasticsearchRestTemplate。
- ElasticsearchRestTemplate 基 于 RestHighLevelClient 客 户 端 的 。 需 要 自 定 义 配 置 类 , 继 承AbstractElasticsearchConfiguration,并实现 elasticsearchClient()抽象方法,创建 RestHighLevelClient 对象。
import lombok.Data;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
@ConfigurationProperties(prefix = "elasticsearch")
@Configuration
@Data
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
private String host ;
private Integer port ;
//重写父类方法
@Override
public RestHighLevelClient elasticsearchClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(host, port));
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);
return restHighLevelClient;
}
`}
`
- DAO 数据访问对象
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
`@Repository
public interface ProductDao extends ElasticsearchRepository<Product,Long> {
}
`
框架集成操作测试 {#框架集成操作测试}
索引操作 {#索引操作}
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESIndexTest {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
//创建索引并增加映射配置
@Test
public void createIndex(){
System.out.println("创建索引");
}
@Test
public void deleteIndex(){
//创建索引,系统初始化会自动创建索引
boolean flg = elasticsearchRestTemplate.deleteIndex(Product.class);
System.out.println("删除索引 = " + flg);
}
}
文档操作 {#文档操作}
import com.lun.dao.ProductDao;
import com.lun.model.Product;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.test.context.junit4.SpringRunner;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESProductDaoTest {
@Autowired
private ProductDao productDao;
/**
* 新增
*/
@Test
public void save(){
Product product = new Product();
product.setId(2L);
product.setTitle("华为手机");
product.setCategory("手机");
product.setPrice(2999.0);
product.setImages("http://www.atguigu/hw.jpg");
productDao.save(product);
}
//修改
@Test
public void update(){
Product product = new Product();
product.setId(2L);
product.setTitle("小米 2 手机");
product.setCategory("手机");
product.setPrice(9999.0);
product.setImages("http://www.atguigu/xm.jpg");
productDao.save(product);
}
//根据 id 查询
@Test
public void findById(){
Product product = productDao.findById(2L).get();
System.out.println(product);
}
@Test
public void findAll(){
Iterable<Product> products = productDao.findAll();
for (Product product : products) {
System.out.println(product);
}
}
//删除
@Test
public void delete(){
Product product = new Product();
product.setId(2L);
productDao.delete(product);
}
//批量新增
@Test
public void saveAll(){
List<Product> productList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Product product = new Product();
product.setId(Long.valueOf(i));
product.setTitle("["+i+"]小米手机");
product.setCategory("手机");
product.setPrice(1999.0 + i);
product.setImages("http://www.atguigu/xm.jpg");
productList.add(product);
}
productDao.saveAll(productList);
}
//分页查询
@Test
public void findByPageable(){
//设置排序(排序方式,正序还是倒序,排序的 id)
Sort sort = Sort.by(Sort.Direction.DESC,"id");
int currentPage=0;//当前页,第一页从 0 开始, 1 表示第二页
int pageSize = 5;//每页显示多少条
//设置查询分页
PageRequest pageRequest = PageRequest.of(currentPage, pageSize,sort);
//分页查询
Page<Product> productPage = productDao.findAll(pageRequest);
for (Product Product : productPage.getContent()) {
System.out.println(Product);
}
}
`}
`
文档搜索 {#文档搜索}
import com.lun.dao.ProductDao;
import com.lun.model.Product;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.PageRequest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringDataESSearchTest {
@Autowired
private ProductDao productDao;
/**
* term 查询
* search(termQueryBuilder) 调用搜索方法,参数查询构建器对象
*/
@Test
public void termQuery(){
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");
Iterable<Product> products = productDao.search(termQueryBuilder);
for (Product product : products) {
System.out.println(product);
}
}
/**
* term 查询加分页
*/
@Test
public void termQueryByPage(){
int currentPage= 0 ;
int pageSize = 5;
//设置查询分页
PageRequest pageRequest = PageRequest.of(currentPage, pageSize);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "小米");
Iterable<Product> products =
productDao.search(termQueryBuilder,pageRequest);
for (Product product : products) {
System.out.println(product);
}
}
`}
`
Spark Streaming 框架集成 {#Spark-Streaming-框架集成}
Spark Streaming 框架介绍 {#Spark-Streaming-框架介绍}
Spark Streaming 是 Spark core API 的扩展,支持实时数据流的处理,并且具有可扩展,高吞吐量,容错的特点。 数据可以从许多来源获取,如 Kafka,Flume,Kinesis 或 TCP sockets, 并且可以使用复杂的算法进行处理,这些算法使用诸如 map,reduce,join 和 window 等高 级函数表示。 最后,处理后的数据可以推送到文件系统,数据库等。 实际上,您可以将 Spark 的机器学习和图形处理算法应用于数据流。

框架集成 {#框架集成-}
- 创建Maven项目
- 修改 pom 文件,增加依赖关系
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.es</groupId>
<artifactId>es-sparkstreaming</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch的客户端 -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!-- elasticsearch依赖2.x的log4j -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>com.fasterxml.jackson.core</groupId>-->
<!-- <artifactId>jackson-databind</artifactId>-->
<!-- <version>2.11.1</version>-->
<!-- </dependency>-->
<!-- <!-- junit单元测试 -->-->
<!-- <dependency>-->
<!-- <groupId>junit</groupId>-->
<!-- <artifactId>junit</artifactId>-->
<!-- <version>4.12</version>-->
<!-- </dependency>-->
</dependencies>
`</project>
`
- 功能实现
package com.atguigu.es
import org.apache.http.HttpHost
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.elasticsearch.action.index.{IndexRequest, IndexResponse}
import org.elasticsearch.client.{RequestOptions, RestClient, RestHighLevelClient}
import org.elasticsearch.common.xcontent.XContentType
object SparkStreamingESTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("ESTest")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val ds: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
ds.foreachRDD(
rdd => {
rdd.foreach(
data => {
val client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost",9200, "http"))
)
val ss = data.split(" ")
val request = new IndexRequest()
request.index("product").id(ss(0))
val json =
s"""
| { "data" : "${ss(1)}" }
|""".stripMargin
request.source(json, XContentType.JSON)
val response: IndexResponse = client.index(request, RequestOptions.DEFAULT)
println(response.getResult)
client.close()
}
)
}
)
ssc.start()
ssc.awaitTermination()
}
`}
`
Flink 框架集成 {#Flink-框架集成}
Flink 框架介绍 {#Flink-框架介绍}
Apache Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Apache Spark 掀开了内存计算的先河,以内存作为赌注,赢得了内存计算的飞速发展。 但是在其火热的同时,开发人员发现,在 Spark 中,计算框架普遍存在的缺点和不足依然没 有完全解决,而这些问题随着 5G 时代的来临以及决策者对实时数据分析结果的迫切需要而 凸显的更加明显:
- 数据精准一次性处理(Exactly-Once)
- 乱序数据,迟到数据
- 低延迟,高吞吐,准确性
- 容错性
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。在 Spark 火热的同时,也默默地发展自己,并尝试着解决其他计算框架的问题。 慢慢地,随着这些问题的解决,Flink 慢慢被绝大数程序员所熟知并进行大力推广,阿里公 司在 2015 年改进 Flink,并创建了内部分支 Blink,目前服务于阿里集团内部搜索、推荐、 广告和蚂蚁等大量核心实时业务。
框架集成 {#框架集成--}
- 创建Maven项目
- 修改 pom 文件,增加相关依赖类库
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.es</groupId>
<artifactId>es-flink</artifactId>
<version>1.0</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.11</artifactId>
<version>1.12.0</version>
</dependency>
<!-- jackson -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.11.1</version>
</dependency>
</dependencies>
`</project>
`
- 功能实现
package com.atguigu.es;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.flink.table.descriptors.Elasticsearch;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class FlinkElasticsearchSinkTest {
public static void main(String\[\] args) throws Exception {
// 构建Flink环境对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Source : 数据的输入
DataStreamSource<String> source = env.socketTextStream("localhost", 9999);
// 使用ESBuilder构建输出
List<HttpHost> hosts = new ArrayList<>();
hosts.add(new HttpHost("127.0.0.1", 9200, "http"));
ElasticsearchSink.Builder<String> esBuilder = new ElasticsearchSink.Builder<>(hosts,
new ElasticsearchSinkFunction<String>() {
@Override
public void process(String s, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
Map<String, String> jsonMap = new HashMap<>();
jsonMap.put("data", s);
IndexRequest indexRequest = Requests.indexRequest();
indexRequest.index("flink-index");
indexRequest.id("9001");
indexRequest.source(jsonMap);
requestIndexer.add(indexRequest);
}
});
// Sink : 数据的输出
esBuilder.setBulkFlushMaxActions(1);
source.addSink(esBuilder.build());
// 执行操作
env.execute("flink-es");
}
`}
`