JVM架构图 {#jvm架构图}
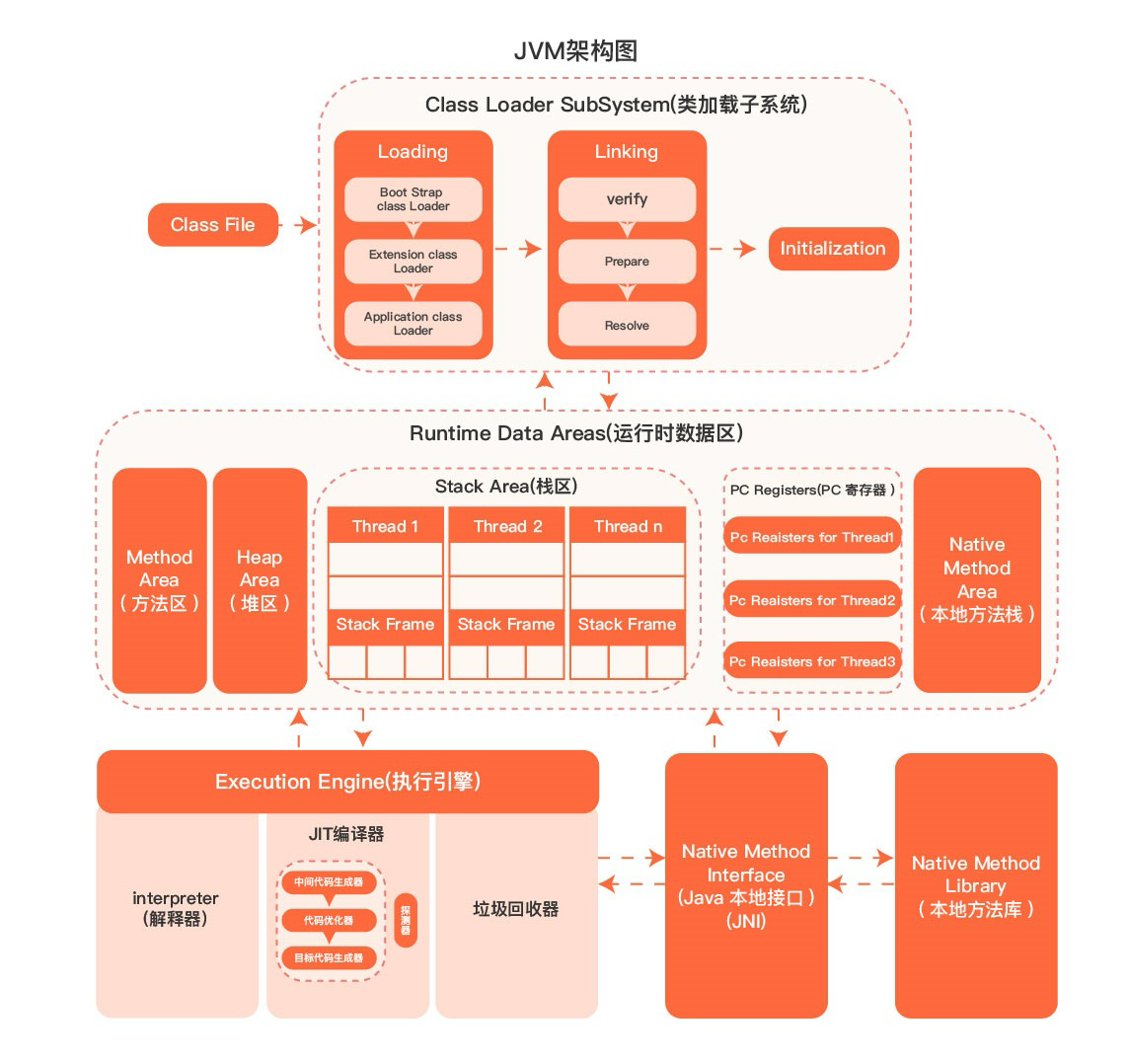
运行时数据区 {#运行时数据区}
- 程序计数器
- 本地方法栈
- 虚拟机栈
- 堆
- 方法区
- 运行时常量池
- 字符串常量池
- 直接内存
类加载时机 {#类加载时机}
- 创建类的实例
- 访问类的静态变量
- 访问类的静态方法
- 反射,Class.forName
- 初始化子类(会首先初始化一个子类的父类)
- 定义了main方法的那个类
类加载流程 {#类加载流程}
加载 -> 验证 -> 准备 -> 解析 -> 初始化 -> 使用 -> 卸载
有哪些类加载器 {#有哪些类加载器}
- 启动类加载器(Bootstrap ClassLoader):负责加载 JAVA_HOME\lib 目录中的,或通过-Xbootclasspath参数指定路径中的,且被虚拟 机认可(按文件名识别,如rt.jar)的类
- 扩展类加载器(Extension ClassLoader):负责加载 JAVA_HOME\lib\ext 目录中的,或通过java.ext.dirs系统变量指定路径中的类库
- 应用程序类加载器(Application ClassLoader):负责加载用户路径classpath上的类库
- 自定义类加载器(User ClassLoader)
什么是双亲委派 {#什么是双亲委派}
当一个类加载器收到类加载任务,会先交给其父类加载器去完成。因此,最终加载任务都会传递到 顶层的启动类加载器,只有当父类加载器无法完成加载任务时,子类才会尝试执行加载任务
为什么要双亲委派 {#为什么要双亲委派}
考虑到安全因素,双亲委派可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子 ClassLoader再加载一次。
一个非常明显的目的就是保证java官方的类库<JAVA_HOME>\lib和扩展类库<JAVA_HOME>\lib\ext的加载安全性,不会被开发者覆盖。
例如类java.lang.Object,它存放在rt.jar之中,无论哪个类加载器要加载这个类,最终都是委派给启动类加载器加载,因此Object类在程序的各种类加载器环境中都是同一个类。
对象创建流程 {#对象创建流程}
1、类加载检查
检查类是否有被创建、加载过,如果没有,则先执行类加载流程
2、分配内存
根据对象所需要的内存大小分配内存,对象所需内存大小在类创建后便可确定。
分配方式有「指针碰撞」和「空闲列表」两种。
内存分配时并发问题解决:「CAS+失败重试」和「TLAB」。
3、初始化零值
4、设置对象头
设置对象的类、哈希码、GC分代年龄等信息。
5、执行 init 方法
从虚拟机的视角来看,一个新的对象已经产生了,但从 Java 程序的视角来看,对象创建才刚开始,<init> 方法还没有执行,所有的字段都还为零。
对象内存布局 {#对象内存布局}
- 对象头
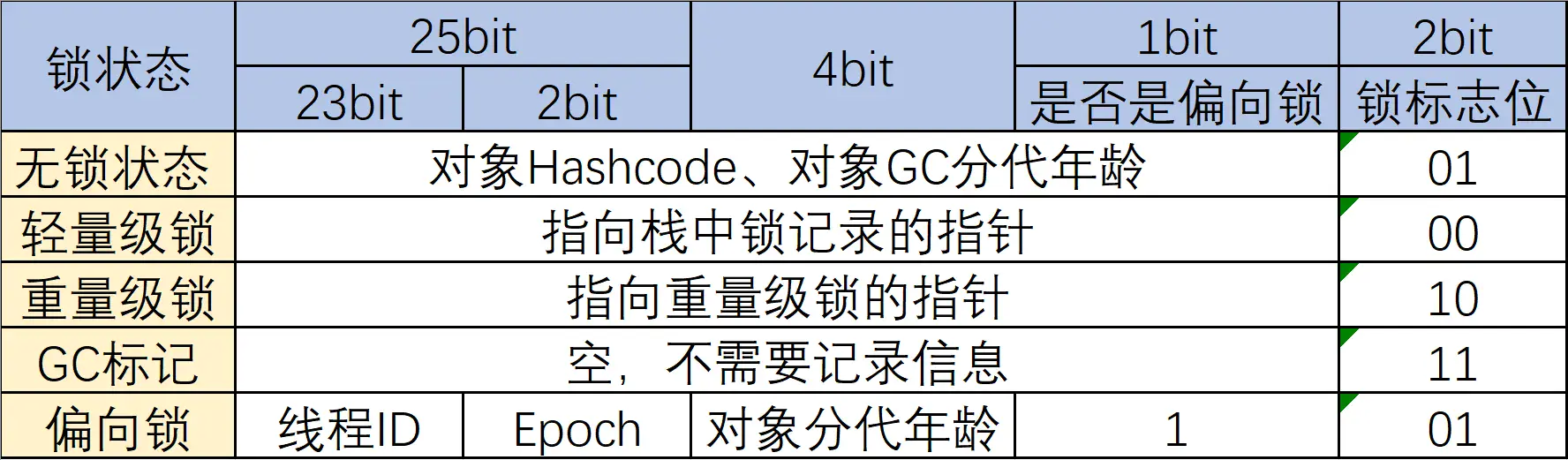
- 标记字段:存储哈希码、GC 分代年龄、锁状态标志等。
- 类型指针:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例,开启指针压缩存储空间4byte,不开启8byte。
- 数组长度:如果对象是数组,则记录数组长度,占4个byte,如果对象不是数组则不存在。
- 对齐填充:保证数组的大小永远是8byte的整数倍。
- 实例数据:生成对象的时候,对象的非静态成员变量也会存入堆空间。
- 对齐填充:JVM内对象都采用8byte对齐,不够8byte的会自动补齐。
引用类型 {#引用类型}
1、强引用
垃圾回收器就绝不会回收强引用对象。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2、软引用
如果内存空间足够,垃圾回收器就不会回收,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
3、弱引用
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
4、虚引用
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
垃圾收集算法 {#垃圾收集算法}
- 标记-清除算法
- 复制算法
- 标记-整理算法
- 分代收集算法
垃圾收集器 {#垃圾收集器}
- Serial 收集器:串行单线程
- ParNew 收集器:串行多线程
- Parallel Scavenge 收集器:串行多线程,关注吞吐量,jdk8默认收集器
- Serial Old 收集器:Serial的老年代版本,串行单线程
- Parallel Old 收集器:Parallel Scavenge的老年代版本,串行多线程
- CMS 收集器:并行,多线程,目标是降低停顿时间,分四个步骤:
- 初始标记:暂停所有的其他线程,并记录下直接与 root 相连的对象,速度很快 ;
- 并发标记:同时开启 GC 和用户线程;
- 重新标记:重新标记阶段就是为了修正并发标记期间因为用户程序继续运行而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段的时间稍长,远远比并发标记阶段时间短;
- 并发清除:开启用户线程,同时 GC 线程开始对未标记的区域做清扫
- G1收集器:G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值最大的 Region(这也就是它的名字 Garbage-First 的由来) 。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证了 G1 收集器在有限时间内可以尽可能高的收集效率(把内存化整为零)。从 JDK9 开始,G1 垃圾收集器成为了默认的垃圾收集器
- ZGC收集器:与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。ZGC 可以将暂停时间控制在几毫秒以内,且暂停时间不受堆内存大小的影响,出现 Stop The World 的情况会更少,但代价是牺牲了一些吞吐量。ZGC 最大支持 16TB 的堆内存。ZGC 在 Java15 已经可以正式使用了。