如果你需要写一篇文章需要即包含文字又包含图片内容,通常的做法是写完文字后去查找符合的图片,或者是AI生成对应的图片,又或者是有一个Agent帮你通过提示词和你写的文字生成图片,这些方法都Out了。
Chameleon 是由 Meta 的 FAIR 团队开发的一个基于令牌的早期融合混合模态模型。Chameleon 将文本和图像作为输入,使用统一架构输出任意文本和图像组合,进行编码和解码。它能够同时处理图像和文本,并具备理解和生成这两种类型数据的能力。 换句话说,Chameleon 可以阅读文字和图片,并且也能创作新的文字和图片。在处理过程中,Chameleon 可以无缝地在不同数据类型之间切换。这意味着它能够在生成一段文字后,接着生成一张相关的图片,或者在描述一张图片的同时生成相关的文字。
换句话说,Chameleon 可以阅读文字和图片,并且也能创作新的文字和图片。在处理过程中,Chameleon 可以无缝地在不同数据类型之间切换。这意味着它能够在生成一段文字后,接着生成一张相关的图片,或者在描述一张图片的同时生成相关的文字。  工作原理 不同于大多数基于扩散的后期融合模型,Meta Chameleon 对文本和图像进行标记化处理,使其更统一、更易设计、维护和扩展。它能为图像生成创意标题,或通过文本提示和图像混合创建全新场景,可能性无穷无尽。
工作原理 不同于大多数基于扩散的后期融合模型,Meta Chameleon 对文本和图像进行标记化处理,使其更统一、更易设计、维护和扩展。它能为图像生成创意标题,或通过文本提示和图像混合创建全新场景,可能性无穷无尽。 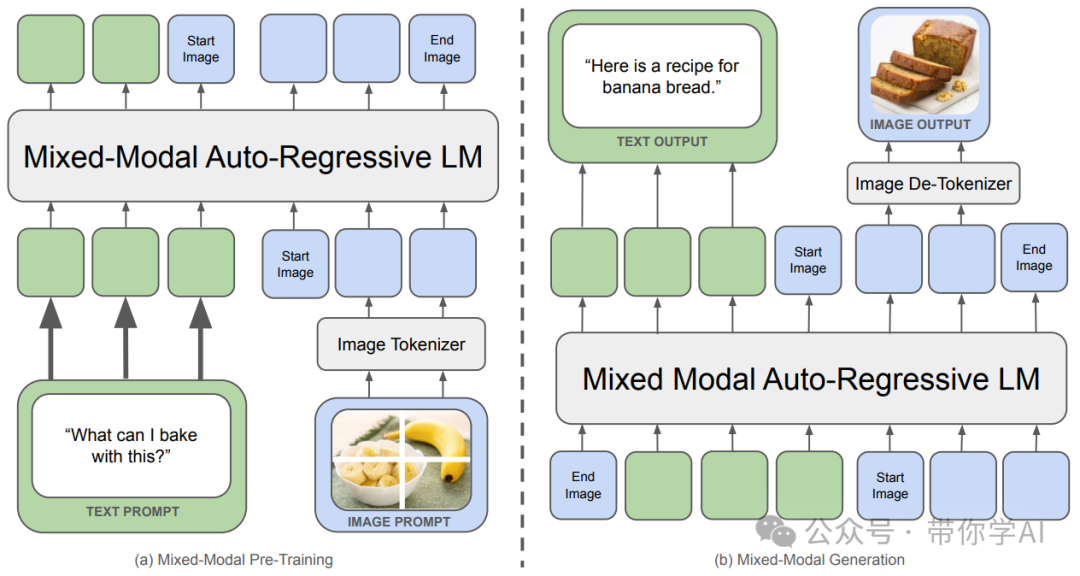 Chameleon 模型的架构与 Llama 2 基本相同,但 Meta 的研究人员对底层 transformer 架构进行了调整,以便更好地处理混合模态。这些调整包括引入查询键规范化和修改层规范的放置位置。Chameleon 使用两个分词器来处理输入数据,一个用于文本,一个用于图像,并结合这些数据形成整体输入。输出时也遵循相同的过程,确保模型能专注于输入和输出的数据。 尽管 Chameleon 的大小不到 Llama 2 的一半,但通过这些改进,研究人员能够使用五倍于训练 Llama 2 的标记数来训练这个拥有 340 亿个参数的模型。 多模态理解和生成 Chameleon 能够理解和生成包含图像和文本的复杂内容。它可以在图像、文本和代码之间无缝切换,实现多种任务的高效处理和生成。
Chameleon 模型的架构与 Llama 2 基本相同,但 Meta 的研究人员对底层 transformer 架构进行了调整,以便更好地处理混合模态。这些调整包括引入查询键规范化和修改层规范的放置位置。Chameleon 使用两个分词器来处理输入数据,一个用于文本,一个用于图像,并结合这些数据形成整体输入。输出时也遵循相同的过程,确保模型能专注于输入和输出的数据。 尽管 Chameleon 的大小不到 Llama 2 的一半,但通过这些改进,研究人员能够使用五倍于训练 Llama 2 的标记数来训练这个拥有 340 亿个参数的模型。 多模态理解和生成 Chameleon 能够理解和生成包含图像和文本的复杂内容。它可以在图像、文本和代码之间无缝切换,实现多种任务的高效处理和生成。  Chameleon 使用早期融合架构,将图像和文本数据从一开始就结合在一起进行处理,并通过统一的Token表示和 Transformer 架构处理这些Token序列。为了确保训练稳定性,Chameleon 引入了查询-键规范化和修订的层规范化与 dropout 技术,并采用自回归生成方法,先在大规模数据集上预训练,再在高质量数据集上进行微调。 模型测评 Chameleon 模型在视觉问答、图像描述、文本生成、图像生成和长格式混合模态生成等任务中表现出色,超越了 Llama-2,并与 Mixtral 8x7B、Gemini-Pro 等模型竞争,在人类评判的新长格式混合模态生成评估中表现匹配或超过了包括 Gemini Pro 和 GPT-4V 在内的更大模型。
Chameleon 使用早期融合架构,将图像和文本数据从一开始就结合在一起进行处理,并通过统一的Token表示和 Transformer 架构处理这些Token序列。为了确保训练稳定性,Chameleon 引入了查询-键规范化和修订的层规范化与 dropout 技术,并采用自回归生成方法,先在大规模数据集上预训练,再在高质量数据集上进行微调。 模型测评 Chameleon 模型在视觉问答、图像描述、文本生成、图像生成和长格式混合模态生成等任务中表现出色,超越了 Llama-2,并与 Mixtral 8x7B、Gemini-Pro 等模型竞争,在人类评判的新长格式混合模态生成评估中表现匹配或超过了包括 Gemini Pro 和 GPT-4V 在内的更大模型。
 Github: https://github.com/facebookresearch/chameleon
Github: https://github.com/facebookresearch/chameleon

感谢关注~ ,
,