本文属于工作技术实践经验分享。
一、先说下需求背景
目前TTS语音合成技术非常成熟,再配合一些静态图片,就能轻松合成一个MP4视频。
但有个问题,字幕。
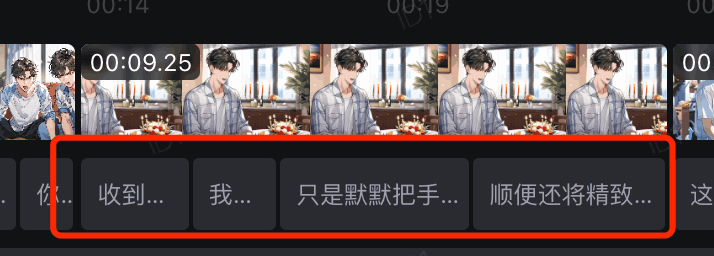
为了节约成本,一个TTS语音包含的文字往往会有上百字,不可能全部一股脑作为字幕显示,需要进行分词,有一种简单的分词方法就是在逗号等标点位置进行分割。
如下图所示:
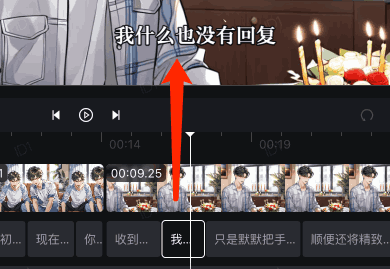
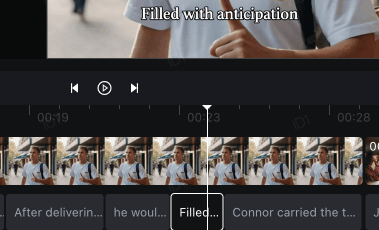
然后播放到对应时间,显示对应的字幕,就像下面这样:
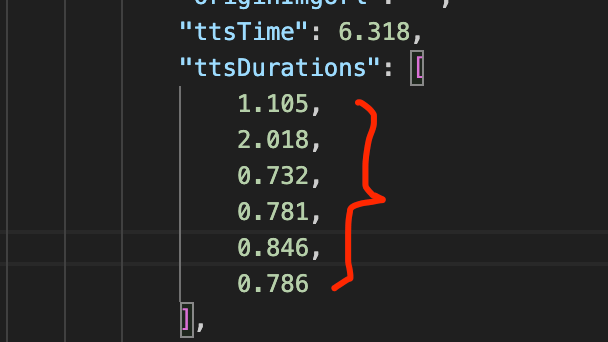
有的TTS语音供应商会返回每个分词的播放时间(见下图字段截图示意),例如字节的,这个就很方便,可以让我们精准控制语音和字幕的匹配时机。
但有的TTS语音合成供应商只有一个总时长,没有分词时间,例如微软,这个就需要我们额外处理。
如果是中文还好,可以按照字数来处理,因为每个中文都会发音,最终的结果大差不差,用户通常无感知。
但是最近公司的海外平台也需要接入视频生成,用来投放引流,之前的算法就遇到了问题。
因为英文和中文不同,很多字母是不会发音的,或者连续几个字母只发一个音,此时,再根据字符数机械地处理,很容易会遇到视频发音和字幕不同步的问题。
所以,就需要额外的更精准的算法,在业界,称为"音素算法"。
二、音素算法与音频时长预估
开门见山,直接上JS代码:
// s 参数指英文单词
function getPhonemeCount(s) {
let totalSyllables = 0;
`// qu to tq
s = s.replace(/qu/g, 'qw');
// replace endings
s = s.replace(/(es$)|(que$)|(gue$)/g, '');
s = s.replace(/^re/, 'ren');
s = s.replace(/^gua/, 'ga');
s = s.replace(/([aeiou])(l+e$)/g, '$1');
let syllables = (s.match(/([bcdfghjklmnpqrstvwxyz])(l+e$)/g) || []).length;
totalSyllables += syllables;
s = s.replace(/([bcdfghjklmnpqrstvwxyz])(l+e$)/g, '$1');
s = s.replace(/([aeiou])(ed$)/g, '$1');
syllables = (s.match(/([bcdfghjklmnpqrstvwxyz])(ed$)/g) || []).length;
totalSyllables += syllables;
s = s.replace(/([bcdfghjklmnpqrstvwxyz])(ed$)/g, '$1');
const endsp = /(ly$)|(ful$)|(ness$)|(ing$)|(est$)|(er$)|(ent$)|(ence$)/g;
syllables = (s.match(endsp) || []).length;
totalSyllables += syllables;
s = s.replace(endsp, '');
syllables = (s.match(endsp) || []).length;
totalSyllables += syllables;
s = s.replace(endsp, '');
s = s.replace(/(^y)([aeiou][aeiou]*)/, '$2');
s = s.replace(/([aeiou])(y)/g, '$1t');
s = s.replace(/aa+/g, 'a');
s = s.replace(/ee+/g, 'e');
s = s.replace(/ii+/g, 'i');
s = s.replace(/oo+/g, 'o');
s = s.replace(/uu+/g, 'u');
// Dipthongs
const dipthongs = /(eau)|(iou)|(are)|(ai)|(au)|(ea)|(ei)|(eu)|(ie)|(io)|(oa)|(oe)|(oi)|(ou)|(ue)|(ui)/g;
syllables = (s.match(dipthongs) || []).length;
totalSyllables += syllables;
s = s.replace(dipthongs, '');
// Remove silent 'e' if length is greater than 3
if (s.length > 3) {
s = s.replace(/([bcdfghjklmnpqrstvwxyz])(e$)/g, '$1');
}
// Count vowels
syllables = (s.match(/[aeiouy]/g) || []).length;
totalSyllables += syllables;
return totalSyllables;
`
}
这段代码参考后端同事那里的Python算法代码,我改成了JavaScript版本,所以,原出处是哪里,我也不清楚哈。
如何使用?
使用的时候非常简单,假设音频时长是ttsTime,文本内容是textContent,则下面的代码可以返回所有单词的音素总数:
function splitSentenceIntoWords(sentence) {
return sentence.match(/\b\w+\b/g) || [];
}
// 计算音素数量
let allPhonemeCount = 0;
const words = splitSentenceIntoWords(textContent);
// 累加count
for (const word of words) {
allPhonemeCount += getPhonemeCount(word);
}
// allPhonemeCount 就是音素总数
此时,每个单词占据的播放时长,就可以根据音素数量的比例进行精准分配了。
有对应的演示页面,您可以狠狠地点击这里:英文语音基于音素估算字幕时间demo
点击音频播放按钮,可以感受下声音和最下面的字幕是否同步。

完整交互代码可以参见demo页面的源代码。
三、结语和其他些说明
上面的音素算法只能说比单纯基于字符数量预估分词时长更精准些,但也不是那种完美的精准。
最好的办法其实还是找一家可以返回每个单词朗读占据时长的供应商。
其他就没什么值得说的了吧。
希望本文的内容可以帮助到遇到此需求的小伙伴吧。
虽然场景小众,但是网上相关资料并不多。
从这一点看,本文的内容还是比较优质的。
所以,请举起你的小手,点击分享。
????
(本篇完)
相关文章
- HTML5语音合成Speech Synthesis API简介 (0.545)
- 借助ffmpeg.wasm纯前端实现多音频和视频的合成 (0.252)
- 不改变音调情况下Audio音频的倍速合成JS实现 (0.237)
- 玩转HTML5 Video视频WebVTT字幕使用样式与制作 (0.218)
- 从天猫某活动视频不必要的3次请求说起 (0.218)
- JS audio加图片序列或canvas转webM/MP4的实现 (0.128)
- 纯JS实现多个音频的拼接或者合并 (0.128)
- 分享一个即插即用的私藏缓动动画JS小算法 (0.109)
- 开源移动端元素拖拽惯性弹动以及下拉加载两个JS (0.109)
- JS检测PNG图片是否有透明背景、抠图等相关处理 (0.109)
- 利用HTML5 Web Audio API给网页JS交互增加声音 (RANDOM - 0.034)