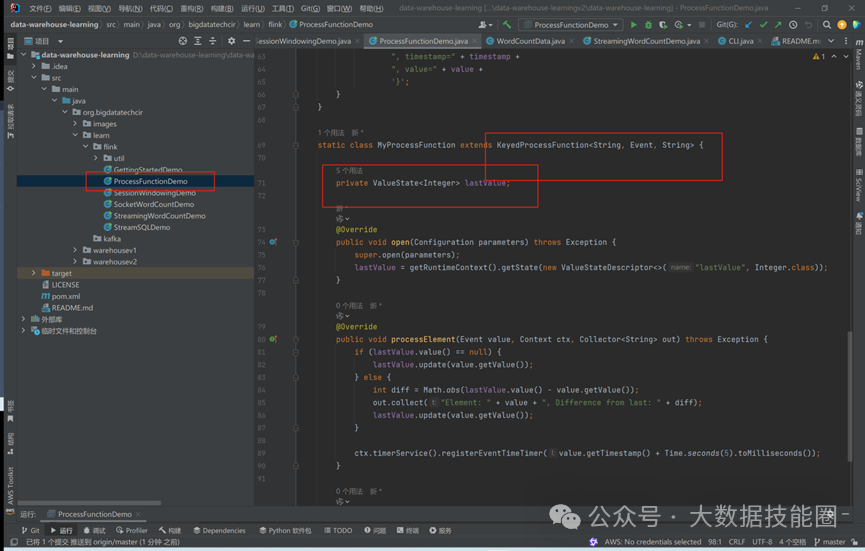
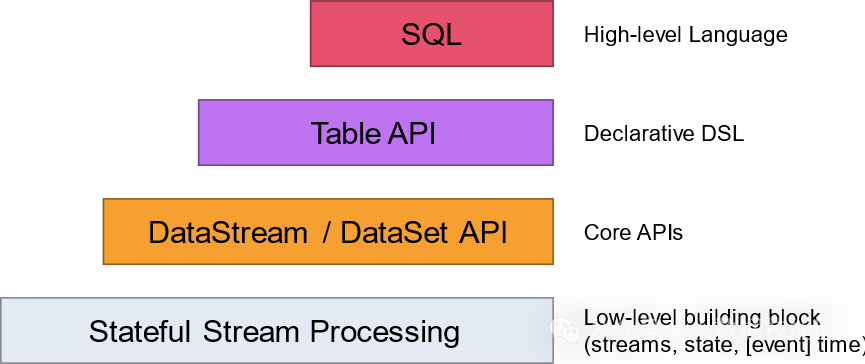
Flink 为流式/批式处理应用程序的开发提供了不同级别的抽象。
 01
SQL
01
SQL
Flink API 最顶层抽象是 SQL。这层抽象在语义和程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式。SQL 抽象与 Table API 抽象之间的关联是非常紧密的,并且 SQL 查询语句可以在 Table API 中定义的表上执行。
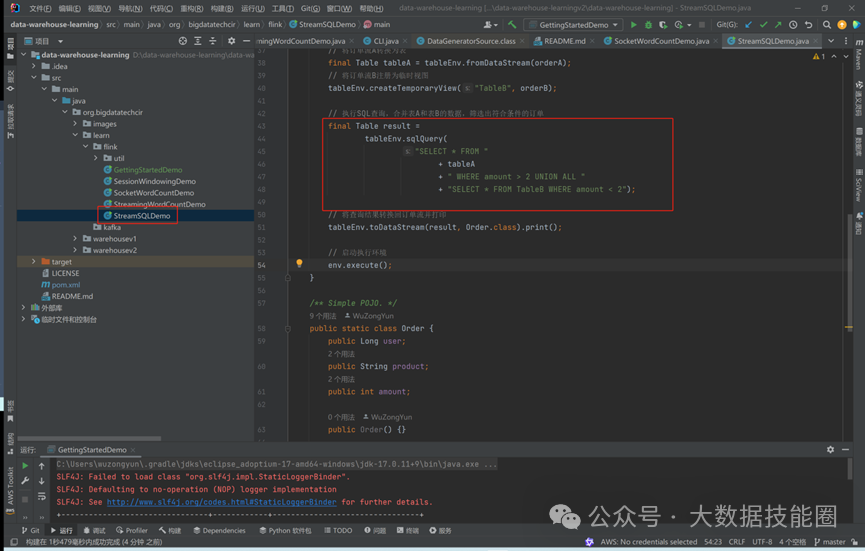
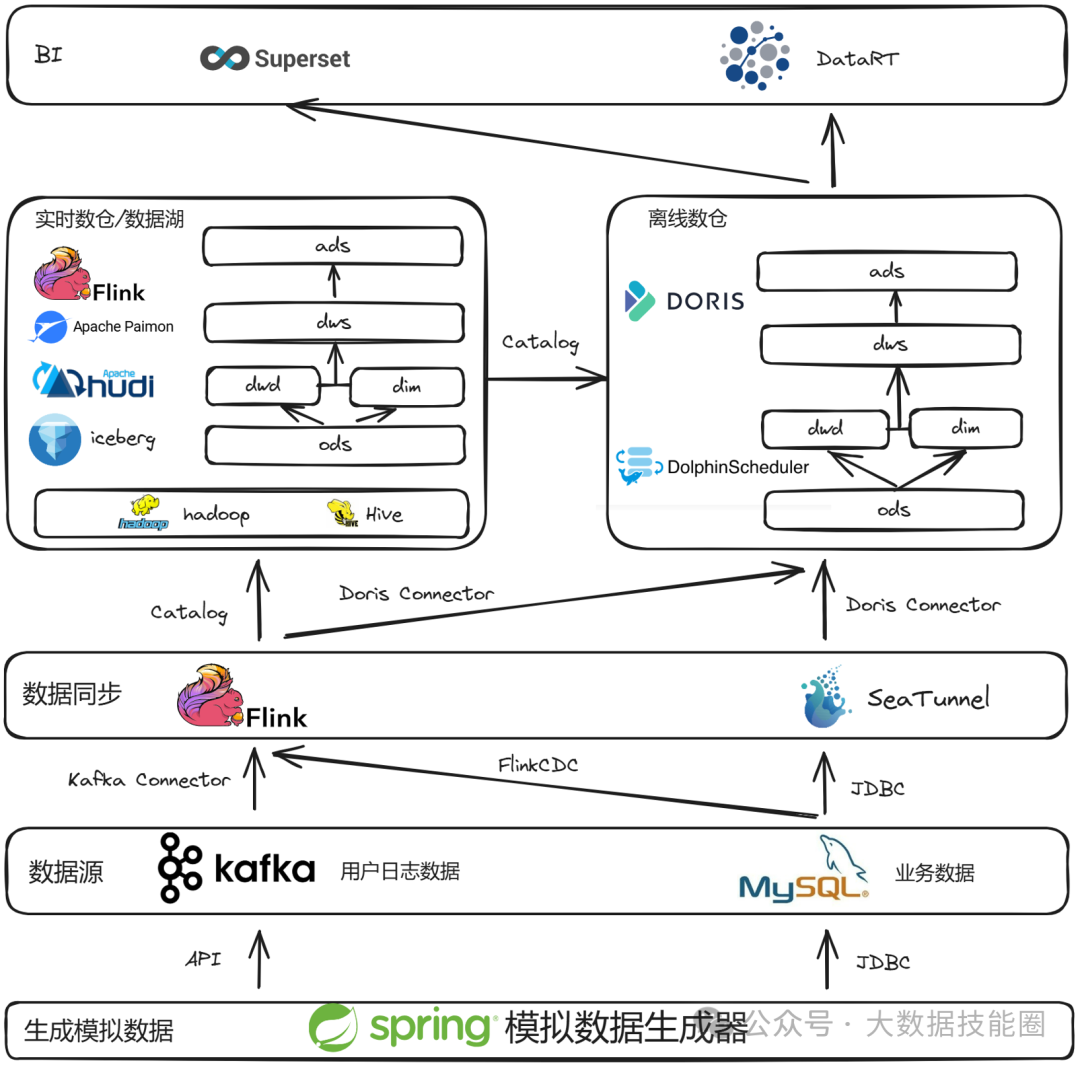
这或许是一个对你有用的开源项目 ,data-warehouse-learning 项目是一套基于 MySQL + Kafka + Hadoop + Hive + Dolphinscheduler + Doris + Seatunnel + Paimon + Hudi + Iceberg + Flink + Dinky + DataRT + SuperSet 实现的实时离线数仓(数据湖)系统,以大家最熟悉的电商业务为切入点,详细讲述并实现了数据产生、同步、数据建模、数仓(数据湖)建设、数据服务、BI报表展示等数据全链路处理流程。
https://gitee.com/wzylzjtn/data-warehouse-learning
https://github.com/Mrkuhuo/data-warehouse-learning
https://bigdatacircle.top/
项目演示:
02 Table API
Flink API 第三层抽象是 Table API。Table API 是以表(Table)为中心的声明式编程(DSL)API,例如在流式数据场景下,它可以表示一张正在动态改变的表。Table API 遵循(扩展)关系模型:即表拥有 schema(类似于关系型数据库中的 schema),并且 Table API 也提供了类似于关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以声明的方式定义应执行的逻辑操作,而不是确切地指定程序应该执行的代码。尽管 Table API 使用起来很简洁并且可以由各种类型的用户自定义函数扩展功能,但还是比 Core API 的表达能力差。此外,Table API 程序在执行之前还会使用优化器中的优化规则对用户编写的表达式进行优化。
表(Table)和 DataStream/DataSet 可以进行无缝切换,Flink 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用。
 03
Core APIs
03
Core APIs
Flink API 第二层抽象是 Core APIs。实际上,许多应用程序不需要使用到上述最底层抽象的 API,而是可以使用 Core APIs 进行编程:其中包含 DataStream API(应用于有界/无界数据流场景)。Core APIs 提供的流式 API(Fluent API)为数据处理提供了通用的模块组件,例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等。此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
Process Function 这类底层抽象和 DataStream API 的相互集成使得用户可以选择使用更底层的抽象 API 来实现自己的需求。DataSet API 还额外提供了一些原语,比如循环/迭代(loop/iteration)操作。  04
有状态实时流处理API
04
有状态实时流处理API
Flink API 最底层的抽象为有状态实时流处理。其抽象实现是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中来为我们使用。它允许用户在应用程序中自由地处理来自单流或多流的事件(数据),并提供具有全局一致性和容错保障的状态。此外,用户可以在此层抽象中注册事件时间(event time)和处理时间(processing time)回调方法,从而允许程序可以实现复杂计算。