2024.07.23 Meta released Llama3.1
本文介绍下最新的Llama3.1,在正式发布前,该模型已经在HF上泄漏,经过X上一天热闹的讨论后,终于正式发布。
-
Blog: https://huggingface.co/blog/llama31
-
https://ai.meta.com/blog/meta-llama-3-1/
-
Paper: https://scontent-sjc3-1.xx.fbcdn.net/v/t39.2365-6/452256780_3788187148167392_9020150332553839453_n.pdf?_nc_cat=103&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=XG3_BvYG0wwQ7kNvgGBgyGR&_nc_ht=scontent-sjc3-1.xx&oh=00_AYDGOU8907donbx_n2EYOzFU-h4VJxtA_EjJbiFVm7qnaA&oe=66A5A0DC
TL;DR
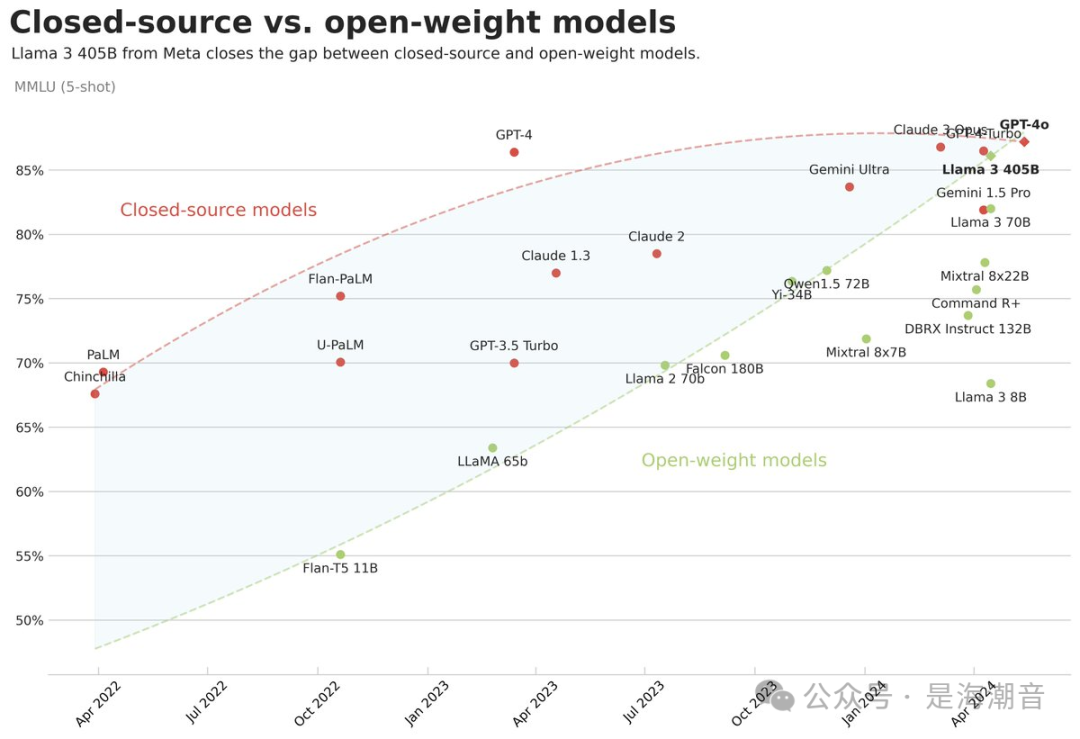
- ? Llama 3.1 405B 打平或者超过 the OpenAI GPT-4o in some text benchmarks
-
? 三种尺寸8个模型:8B, 70B & 405B versions as Instruct and Base
-
8B for efficient deployment and development on consumer-size GPU
-
70B for large-scale AI native applications,
-
405B for synthetic data, LLM as a Judge or distillation.
-
除了上面三种的base and instruction-tuned variants,还发布了两个新模型:Llama Guard 3和Prompt Guard。
-
Prompt Guard是一个基于279M参数BERT的小型分类器,可以检测prompt injections and jailbreaks。它在大量攻击语料库上进行了训练,建议使用application-specific数据进一步微调。
-
Llama Guard 3是一个安全模型,为生产用例构建的,fine-tuned on Llama 3.1 8B,可以对LLM输入(提示)和响应进行分类,以检测在风险分类中被认为不安全的内容。
-
-
support a context length of 128K tokens ,相较于原来的8K,上下文长度提升较大;
- 继续使用分组查询注意(GQA ),这是一种有效的表示,应该有助于更长的上下文。
-
? 多语种支持8种语言,Multilingual, supports 8 languages, including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
-
? Trained on 15.6T Tokens & fine-tuned on 25M human and synthetic samples
-
⚖️ 支持量化版本Quantized versions in FP8, AWQ, and GPTQ for efficient inference.
-
??? 8B & 70B improved Coding and instruction, following up to 12%
-
⚒️ Supports Tool use and Function Calling
-
? Llama 3.1 405B available on Hugging Face Inference API and in HuggingChat
-
Fine-tuning Llama 3.1 8B on a single GPU with ? TRL
Model Architecture
-
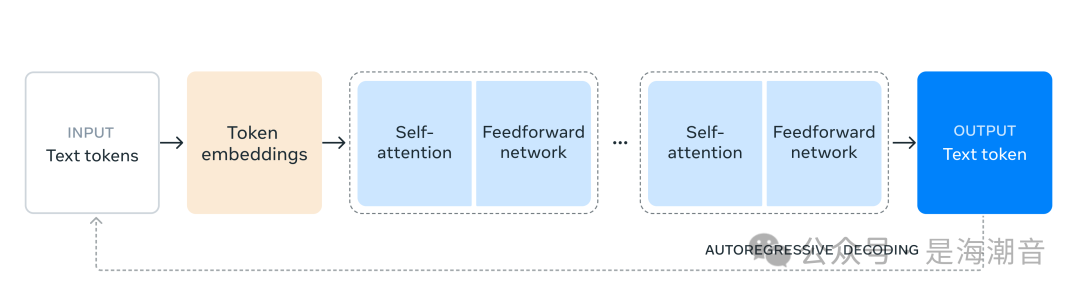
我们选择了标准的 decoder-only transformer model architecture with minor adaptations rather than a mixture-of-experts model 以最大限度地提高训练稳定性。
-
采用了迭代后训练过程,其中每一轮都使用监督微调和直接偏好优化。这使我们能够为每一轮创建最高质量的合成数据并提高每种能力的性能。
-
与以前版本的Llama相比,我们改进了用于训练前和训练后的数据的数量和质量。这些改进包括为预训练数据开发更仔细的预处理和管理管道,开发更严格的质保,以及为后训练数据过滤方法。
-
根据语言模型的缩放定律,我们的新旗舰模型优于使用相同过程训练的较小模型。我们还使用405B参数模型来提高较小模型的训练后质量。
-
为了支持405B规模的模型的大规模生产推理,我们将模型从16位(BF16)量化为8位(FP8)数值,有效降低了所需的计算要求,并允许模型在单个服务器节点中运行。
What's new with Llama 3.1?
-
Llama 3.1405B是第一个公开可用的模型,在一般知识、可操纵性、数学、工具使用和多语言翻译方面具有最先进的能力,可与顶级人工智能模型相媲美。
-
与Llama 3相比,Llama 3.1的新功能是指令模型在tool calling for agentic use cases进行了微调。
-
有两个内置工具(search, mathematical reasoning with Wolfram Alpha)可以使用自定义JSON函数进行扩展。
-
Llama 3.1模型在一个定制的GPU集群上接受了超过15T tokens的训练,总共39.3MGPU小时(1.46M8B,7.0M70B,30.84M405B)。
-
我们不知道训练集组合的确切细节,我们只能猜测它对多语言有更多样化的管理。
-
Llama 3.1 Instruct已经针对指令遵循进行了优化,并在公开可用的指令数据集上进行了训练,以及超过25M个具有监督微调(SFT)和人工反馈强化学习(RLHF)的综合生成示例。
-
Meta开发了基于LLM的分类器,用于在创建数据组合期间过滤和管理高质量的提示和响应。
-
Llama 3.1附带了一个非常相似的许可证,但有一个关键区别:它允许使用可用于改进其他LLM的模型输出(it enables using model outputs that can be used to improve other LLMs)。这意味着您可以使用Llama 3.1模型生成合成数据集,并使用它们来微调更小、更专业的模型。
How much memory does Llama 3.1 need
Inference Memory Requirements
 上面的数字表示加载模型checkpoint所需的GPU VRAM。
上面的数字表示加载模型checkpoint所需的GPU VRAM。
an H100 node (of 8x H100) has ~640GB of VRAM, 所以 405B model 推荐的做法是需要在multi-node上运行推理服务,或者运行低精度(e.g. FP8)
除了模型权重之外,还需要将KV Cache保存在内存中。它包含模型上下文中所有标记的K和V,因此在生成新token时不需要重新计算它们。尤其是在利用长可用上下文长度时,它成为一个重要因素。在FP16中,KV缓存内存要求是: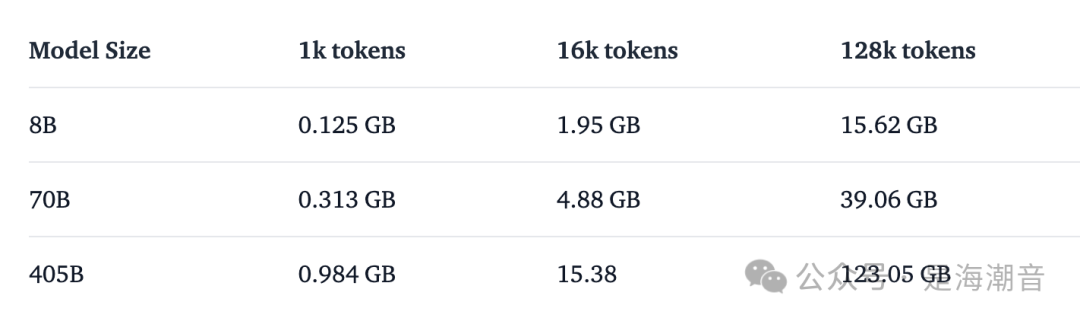
- 特别是对于小型模型,当接近上下文长度最大值时,缓存使用的内存与权重一样多。
Training Memory Requirements
使用不同技术训练Llama 3.1模型的大致内存要求:
Llama 3.1 evaluation
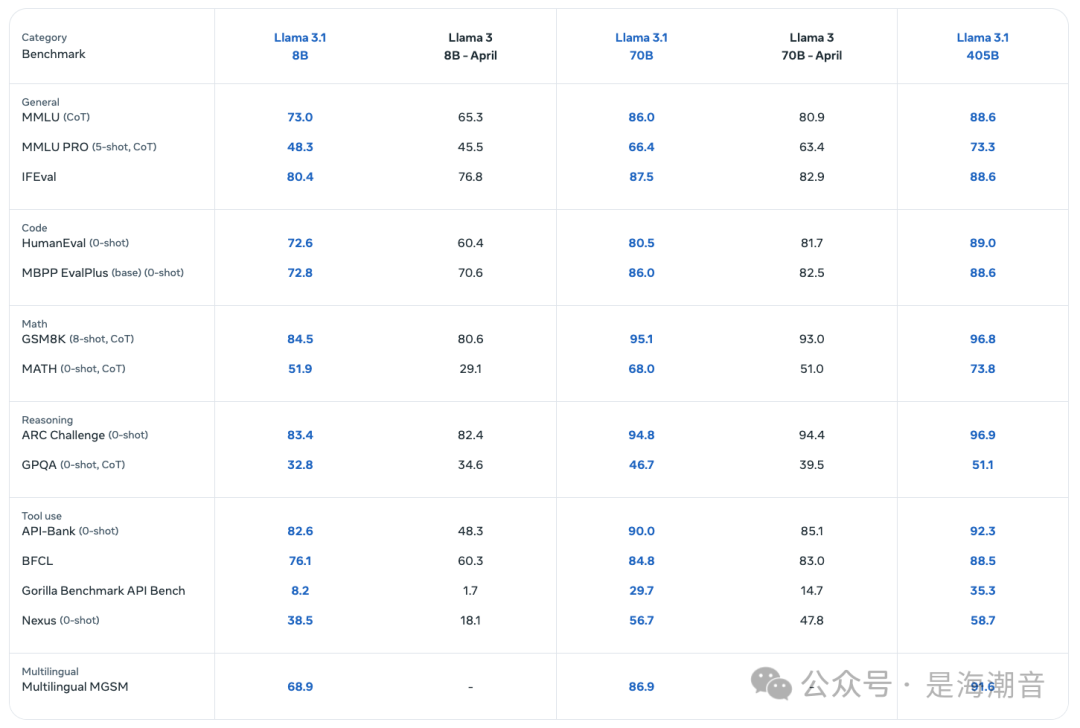
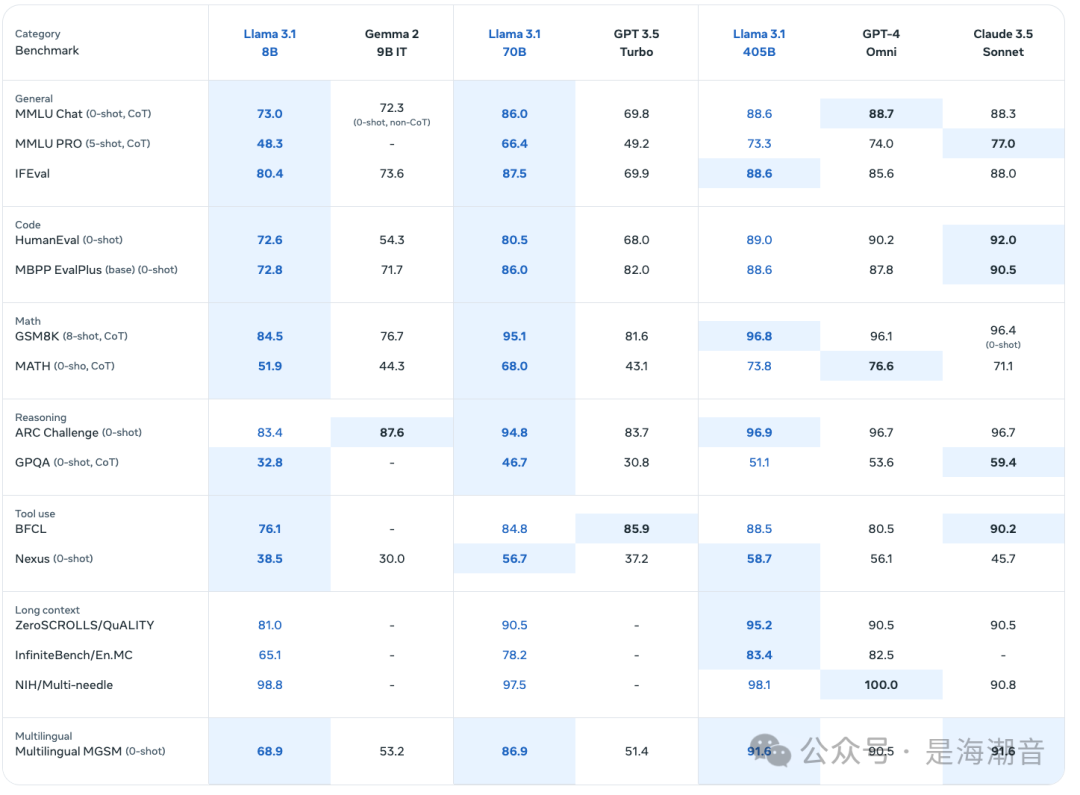
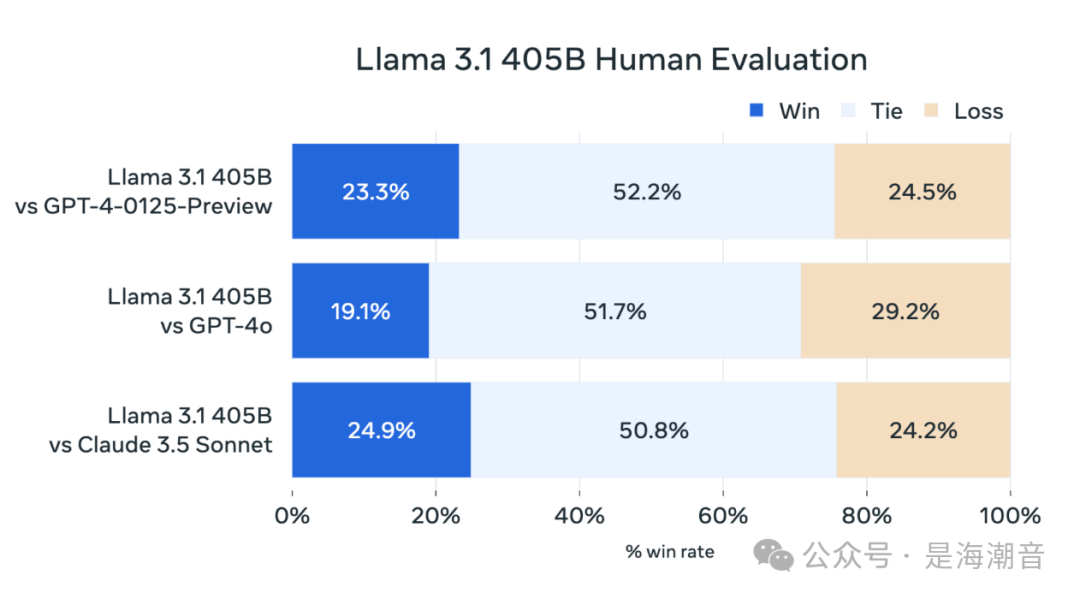
Using Hugging Face Transformers
pip install "transformers>=4.43" --upgrade
from transformers import pipeline
import torch
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "user", "content": "Who are you? Please, answer in pirate-speak."},
]
outputs = pipe(
messages,
max_new_tokens=256,
do_sample=False,
)
assistant_response = outputs[0]["generated_text"][-1]["content"]
print(assistant_response)
# Arrrr, me hearty! Yer lookin' fer a bit o' information about meself, eh? Alright then, matey! I be a language-generatin' swashbuckler, a digital buccaneer with a penchant fer spinnin' words into gold doubloons o' knowledge! Me name be... (dramatic pause)...Assistant! Aye, that be me name, and I be here to help ye navigate the seven seas o' questions and find the hidden treasure o' answers! So hoist the sails and set course fer adventure, me hearty! What be yer first question?
Run with ollama
ollama run llama3.1 # 默认8Bollama run llama3.1:70bollama run llama3.1:405b
Fine-tuning with Hugging Face TRL
-
First, install the nightly version of ? TRL and clone the repo to access the training script:
pip install "transformers>=4.43" --upgrade pip install --upgrade bitsandbytes pip install --ugprade peft pip install git+https://github.com/huggingface/trl git clone https://github.com/huggingface/trl cd trl
-
run the script
python
examples/scripts/sft.py
--model_name meta-llama/Meta-Llama-3.1-8B
--dataset_name OpenAssistant/oasst_top1_2023-08-25
--dataset_text_field="text"
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 4
--learning_rate 2e-4
--report_to "none"
--bf16
--max_seq_length 1024
--lora_r 16 --lora_alpha 32
--lora_target_modules q_proj k_proj v_proj o_proj
--load_in_4bit
--use_peft
--attn_implementation "flash_attention_2"
--logging_steps=10
--gradient_checkpointing
--output_dir llama31
2.1 如果是多卡环境可以training with DeepSpeed and ZeRO Stage 3
accelerate launch --config_file=examples/accelerate_configs/deepspeed_zero3.yaml \
examples/scripts/sft.py \
--model_name meta-llama/Meta-Llama-3.1-8B \
--dataset_name OpenAssistant/oasst_top1_2023-08-25 \
--dataset_text_field="text" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--learning_rate 2e-5 \
--report_to wandb \
--bf16 \
--max_seq_length 1024 \
--attn_implementation eager \
--logging_steps=10 \
--gradient_checkpointing \
--output_dir models/llama