编写脚本可登录邮箱并获取最新的10封邮件,并根据指定关键字获取信息列表(截取以关键字为中心,前10个字符,后10个字符的内容),将上述涉及数字的参数形成配置文件读取
脚本编写
-
首先要打开邮件的设置,保证开启IMAP/SMTP服务,且可以得到
-
编写脚本
-
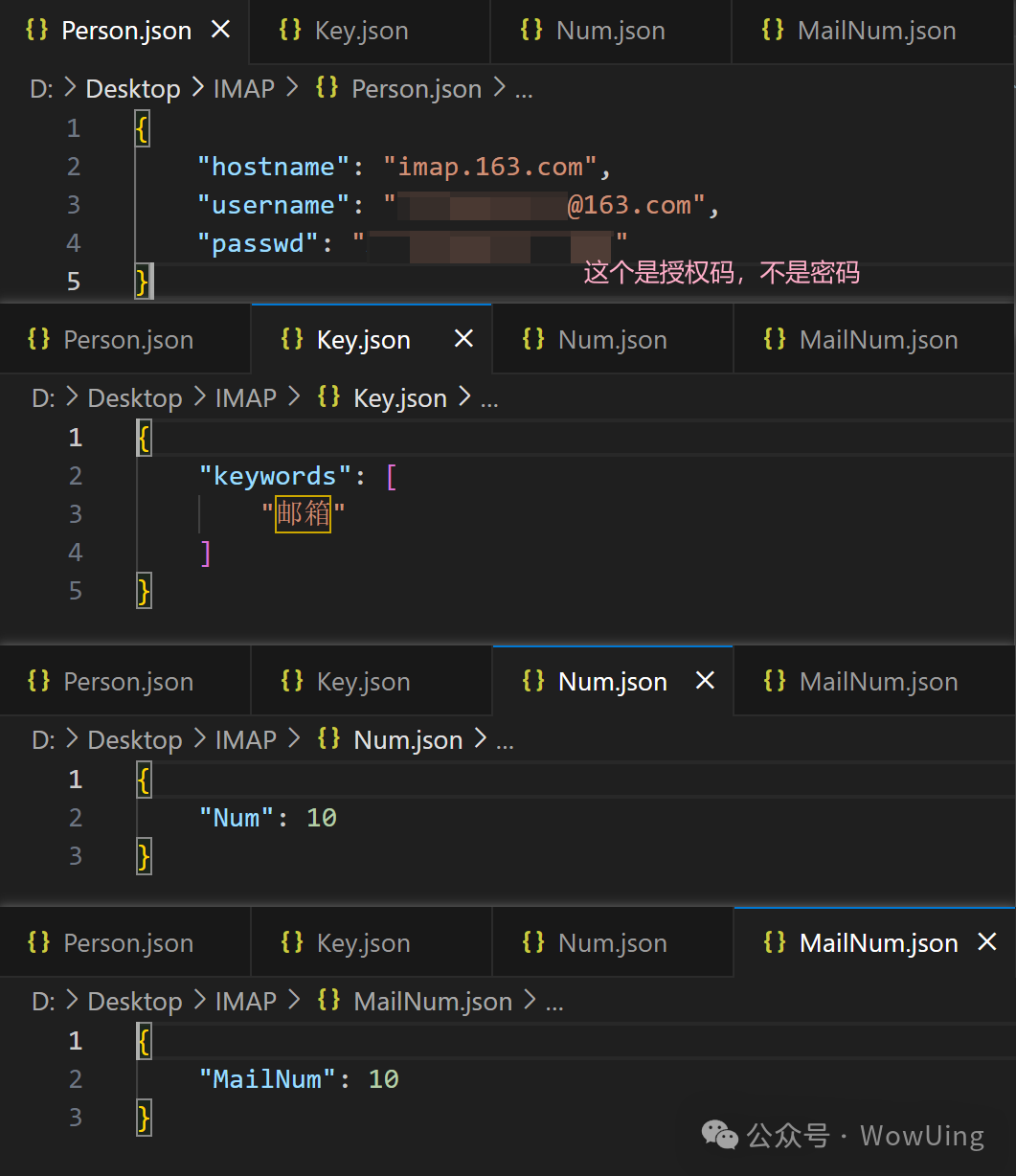
从JSON文件读取URL、邮箱号、授权码、关键词、字符数、邮件
[要修改参数时修改配置文件即可,同时也保证了关键信息的安全性]
-
连接服务,登录账户
-
获取收件箱的邮件内容
-
解析邮件内容并保存到本地文件
-
import email, sys from imapclient import IMAPClient from bs4 import BeautifulSoup import json import re with open("D:\Desktop\IMAP\Person.json", "r", encoding="utf-8") as f: Person = json.load(f) hostname = Person["hostname"] username = Person["username"] passwd = Person["passwd"] with open("D:\Desktop\IMAP\Key.json", "r", encoding="utf-8") as f: Key = json.load(f) KeyList = Key['keywords'] with open(r"D:\Desktop\IMAP\Num.json", "r", encoding="utf-8") as f: Num = json.load(f) N = Num['Num'] with open(r"D:\Desktop\IMAP\MailNum.json", "r", encoding="utf-8") as f: MailNum = json.load(f) # 读取的邮件数 mail_num = MailNum['MailNum'] # 建立连接(创建一个IMAPClient对象,传入ssl=True表示ssl加密,且默认端口为993 server = IMAPClient(hostname, ssl=True) try: # 登录,参数传入账号密码 server.login(username, passwd) # 上传客户端身份信息 server.id_({"name": "IMAPClient", "version": "2.1.0"}) # 找到导航目录的列表 dictList = server.list_folders() # 选择收件箱'INBOX',对收件箱只读 # (在服务器上设置当前文件夹,将来对 search 和 fetch 等方法的调用将作用于所选文件夹 server.select_folder('INBOX') except server.Error: # 处理异常 print('Could not login') sys.exit(1) # result = server.search('UNSEEN') # 用于接收未读的邮件 result = server.search()[-mail_num:] # 接收最新的mail_num封 # 获取内容 for uid in result: massageList = server.fetch(uid, ['BODY[]']) # 根据uid获取全部内容, mailBody = massageList[uid][b'BODY[]'] # 从提取出的全部内容中提取正文部分 try: # 邮件内容解析最里面那层是按字节来解析邮件主题内容,这个过程生成Message类型 # 将字符串解析为电子邮箱对象 email_content = email.message_from_string(mailBody) except TypeError: # 不是字符串就转化为字符串后再解析 email_content = email.message_from_string(str(email.message_from_bytes(mailBody))) subject = email.header.make_header(email.header.decode_header(email_content['SUBJECT'])) # 获取标题 mail_from = email.header.make_header(email.header.decode_header(email_content['From'])) # 获取发件人 envlope = (server.fetch(uid, ['ENVELOPE']))[uid][b'ENVELOPE'] # 获取邮件信息 dates = envlope.date # 收件日期 maintype = email_content.get_content_maintype() # 获取内容的type编码方式 if maintype == 'multipart': # 多个部分的类型 for part in email_content.get_payload(): # 遍历每一个部分 if part.get_content_maintype() == 'text': mail_content = part.get_payload(decode=True).decode('utf-8', 'ignore').strip() # 解码后存储 elif maintype == 'text': # 文本类型 mail_content = email_content.get_payload(decode=True).decode('utf-8', 'ignore').strip() # 保存为文件 f = open(f'D:\Desktop\IMAP\{uid}.txt', 'w+', encoding="utf-8") f.write(f'发件人:{mail_from}' + '\n' + f'主题:{subject}' + '\n' + f'日期:{dates}' + '\n' + '正文内容:' + '\n') # f.write(mail_content.replace('\n\n', '') + '\n') # BeautifulSoup从 HTML 格式的邮件正文中提取文本 f.write((BeautifulSoup(mail_content, 'html.parser').get_text().strip()).replace('\n\n', '') + '\n') mail_content = re.sub(r'<[^>]+>', '', mail_content) # 去除标签 # 列出关键词信息列表 found_keyword = False # 是否有关键词(用来控制仅一次提示词 for key in KeyList: # 遍历关键词 matches = re.finditer(key, mail_content) # 找到所有满足的后返回一个迭代器,生成match对象,包含了位置信息 match_list = [match for match in matches] # 列表推导式 if match_list and not found_keyword: # 第一次找到-->输出提示词 f.write(f"\n根据指定关键字获取信息列表:\n") found_any_keyword = True for match in match_list: start = max(0, match.start() - N) # 确保截取的起始位置不会小于 0 end = min(len(mail_content), match.end() + N) # 确保截取的结束位置不会超出邮件正文的实际长度 snippet = mail_content[start:end].strip().replace('\n\n', '') f.write(f"【{snippet}】\n") f.close() # 退出登陆 server.logout()
-
配置文件:
运行结果: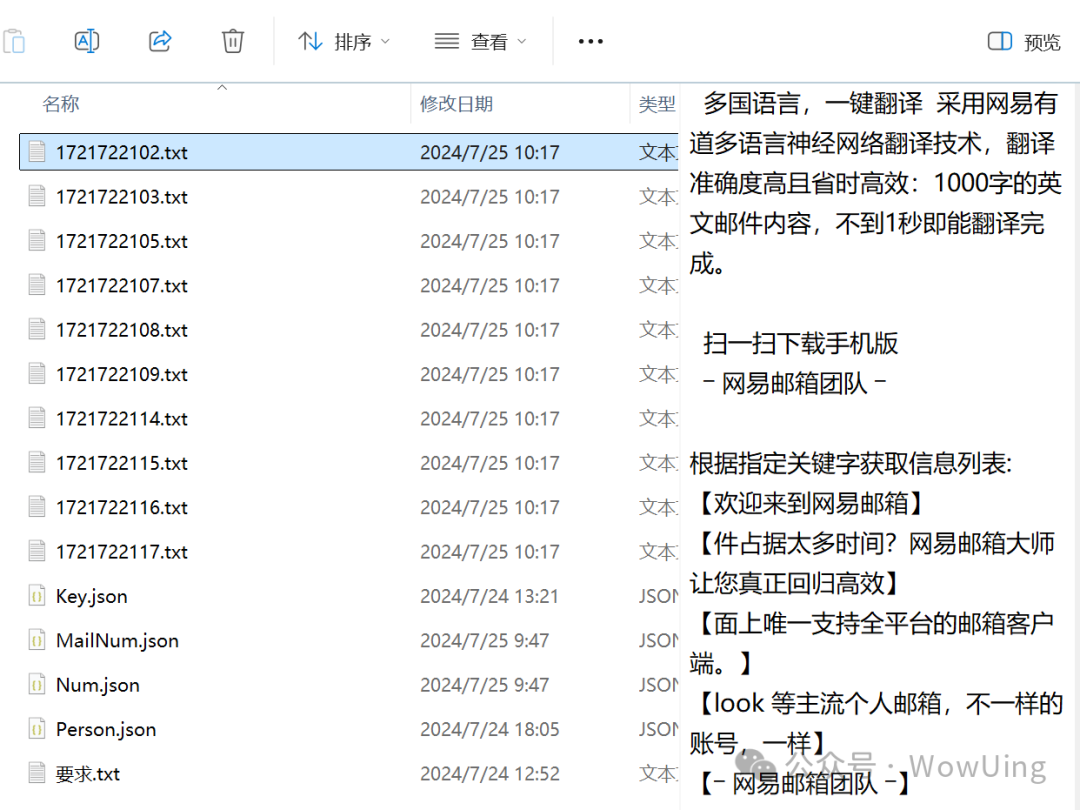
参考文章
-
如何在 Python 中阅读电子邮件:
https://thepythoncode.com/article/reading-emails-in-python
-
IMAPClient 类:
https://imapclient.readthedocs.io/en/3.0.1/api.html
-
Python 用IMAP接收邮件:
https://www.cnblogs.com/zixuan-zhang/p/3402825.html
-
Python 正则表达式:
https://blog.csdn.net/TH_NUM/article/details/105907562
-
【Python】推导式(列表推导式)https://blog.csdn.net/qq_32727095/article/details/118959610
-
Beautiful Soup 中文文档:
https://beautifulsoup.cn/