unsetunset什么是半监督机器学习?unsetunset
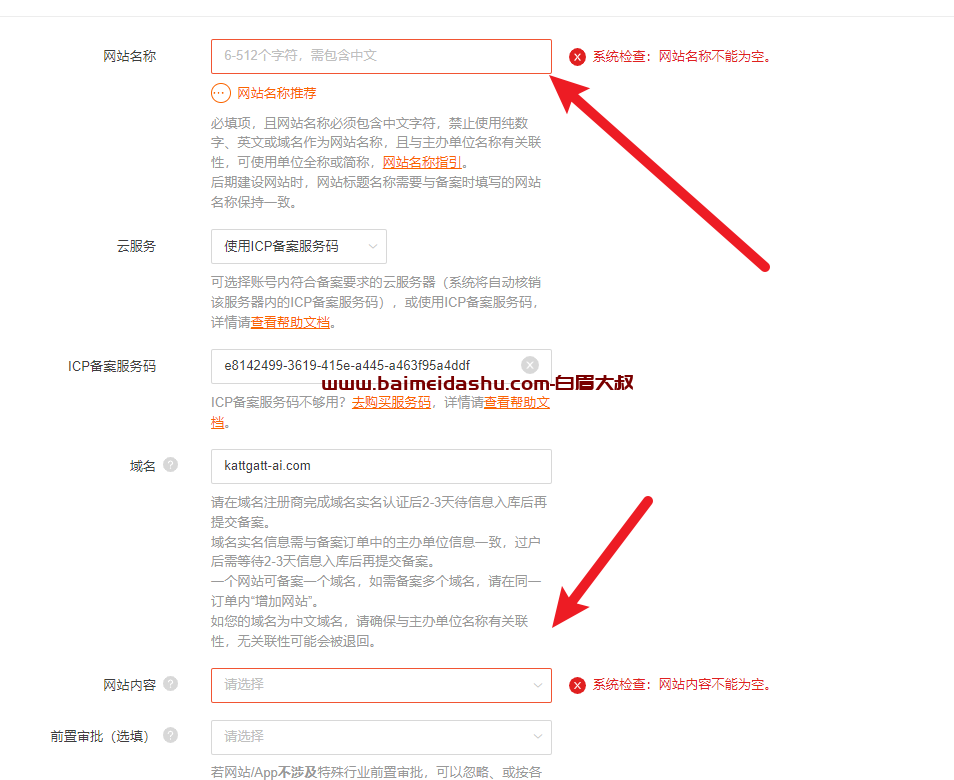
半监督学习是一种训练数据中部分样本没有标签的情况。sklearn.semi_supervised中的半监督估计器能够利用这些额外的无标签数据,更好地捕捉底层数据分布的形状,并更好地泛化到新样本。当我们只有很少的有标签点和大量无标签点时,这些算法能够表现良好。
在使用
fit方法训练模型时,重要的是为未标记的点分配一个标识符与已标记的数据一起使用。本实现使用的标识符是整数值-1。注意,对于字符串标签,y的dtype应该是对象(object),以便它可以同时包含字符串和整数。
unsetunset半监督学习的假设unsetunset
半监督学习算法需要对数据集的分布做出一些假设,以实现性能提升。为了利用无标签数据,必须存在一些与数据底层分布相关的关系。
半监督学习算法利用以下至少一个假设:
连续性/平滑性假设
相互接近的点更可能共享相同的标签。这在监督学习中通常也是假定的,并且倾向于几何上简单的决策边界。在半监督学习的情况下,平滑性假设还倾向于在低密度区域的决策边界,因此只有少量的点彼此接近但属于不同的类别。
聚类假设
数据倾向于形成离散的聚类,并且同一聚类中的点更可能共享相同的标签(尽管共享标签的数据可能分布在多个聚类中)。这是平滑性假设的一种特殊情况,并导致使用聚类算法的特征学习。
流形假设
数据大致位于比输入空间低得多维度的流形上。在这种情况下,使用有标签和无标签数据学习流形可以避免维度灾难。然后,学习可以使用在流形上定义的距离和密度进行。
当高维数据是由一些可能难以直接建模的过程生成,但只有少数自由度时,流形假设是实用的。例如,人类声音是由几片声带控制的,而各种面部表情的图像是由几块肌肉控制的。在这些情况下,最好在生成问题的自然空间中考虑距离和平滑性,而不是在所有可能的声波或图像的空间中。
unsetunset半监督方法:Self Trainingunsetunset
Self Training基于Yarowsky的算法。使用该算法,给定的监督分类器可以作为半监督分类器,使其能够从无标签数据中学习。
SelfTrainingClassifier 可以与任何实现了 predict_proba 的分类器一起使用,并作为参数 base_classifier 传递。在每次迭代中,base_classifier 会为无标签样本预测标签,并将这些标签的一个子集添加到有标签的数据集中。
-
选择这个子集的标准由选择标准决定。这个选择可以通过对预测概率设置一个
threshold阈值,或者通过根据预测概率选择k_best样本来完成。 -
最终拟合时使用的标签以及每个样本被标记的迭代次数可以作为属性获取。可选的
max_iter参数指定了最多执行循环的次数。 -
可以将
max_iter参数设置为None,使算法迭代直到所有样本都有标签或在该迭代中没有选择新的样本为止。import numpy as np from sklearn import datasets from sklearn.semi_supervised import SelfTrainingClassifier from sklearn.svm import SVC
rng = np.random.RandomState(42) iris = datasets.load_iris()
random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3 iris.target[random_unlabeled_points] = -1 svc = SVC(probability=True, gamma="auto") self_training_model = SelfTrainingClassifier(svc) self_training_model.fit(iris.data, iris.target)
unsetunset半监督方法:Label Propagationunsetunset
标签传播表示几种半监督图推断算法的变体。
-
LabelPropagationimport numpy as np from sklearn import datasets from sklearn.semi_supervised import LabelPropagation label_prop_model = LabelPropagation()
iris = datasets.load_iris() rng = np.random.RandomState(42)
random_unlabeled_points = rng.rand(len(iris.target)) < 0.3 labels = np.copy(iris.target) labels[random_unlabeled_points] = -1 label_prop_model.fit(iris.data, labels)
-
LabelSpreadingimport numpy as np from sklearn import datasets from sklearn.semi_supervised import LabelSpreading
label_prop_model = LabelSpreading() iris = datasets.load_iris()
rng = np.random.RandomState(42) random_unlabeled_points = rng.rand(len(iris.target)) < 0.3 labels = np.copy(iris.target) labels[random_unlabeled_points] = -1 label_prop_model.fit(iris.data, labels)
LabelPropagation 和 LabelSpreading 的区别在于相似性矩阵的修改和标签分布的固定效果。固定允许算法在某种程度上改变真实标签数据的权重。LabelPropagation 算法对输入标签执行硬固定,这意味着 ?=0。这个固定因子可以放松,比如 ?=0.2,这意味着我们将始终保留原始标签分布的80%,但算法可以在20%的范围内改变其对分布的信心。
LabelPropagation 使用从数据构建的原始相似性矩阵,没有修改。相比之下,LabelSpreading 最小化了具有正则化属性的损失函数,因此通常对噪声更具鲁棒性。该算法在原始图的修改版本上迭代,并通过计算归一化图拉普拉斯矩阵来归一化边权重。这个过程也在谱聚类中使用。
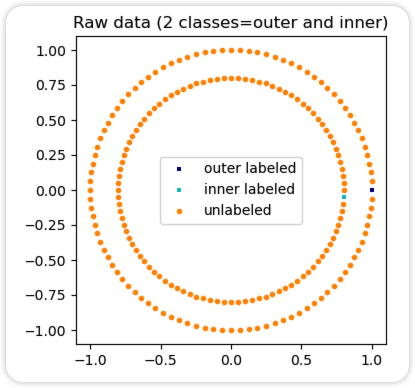
标签传播模型有两种内置的核方法。核的选择会影响算法的可扩展性和性能。可用的核如下:
-
(exp(−?|?−?|²), ?>0)。?通过关键字 gamma 指定。
-
(1[?′∈???(?)])。?通过关键字 n_neighbors 指定。
RBF核将生成一个完全连接的图,该图在内存中表示为稠密矩阵。该矩阵可能非常大,并且每次迭代算法时执行全矩阵乘法计算的成本可能导致运行时间过长。另一方面,KNN核将生成一个更节省内存的稀疏矩阵,可以大大减少运行时间。