今天发现一个最新重磅开源的FishSpeech项目,其功能强大,除了支持超逼真人TTS,还支持声音克隆,效果炸裂!感觉应该是目前开源中文最好的TTS效果!如果你想要商用,请参考官方文档~ 本文手把手带你利用python来进行FishSpeech模型权重进行推理,复现官方demo效果,轻松打造个人语音AI助手。下面进入我们今天的主题~
本文目录
-
FishSpeech项目介绍
- FishSpeech项目提供在线效果demo展示
-
实战篇: FishSpeech部署推理-环境和素材准备
-
配置项目的环境
-
准备音频素材
-
-
实战篇: FishSpeech部署推理-声音克隆-效果展示
-
第一步:从语音生成 prompt(会输出.npy文件)
-
第二步:利用whisper语音识别参考音频的文本
-
第三步:生成文本语义 token
-
第四步:从语义 token 解码生成人声
-
-
实战篇: FishSpeech部署推理-随机生成说话人-效果展示
-
第一步:准备文本素材
-
第二步:进行推理生成语义token
-
第三步: 从语义 token 解码生成人声
-
-
参考链接
FishSpeech项目介绍
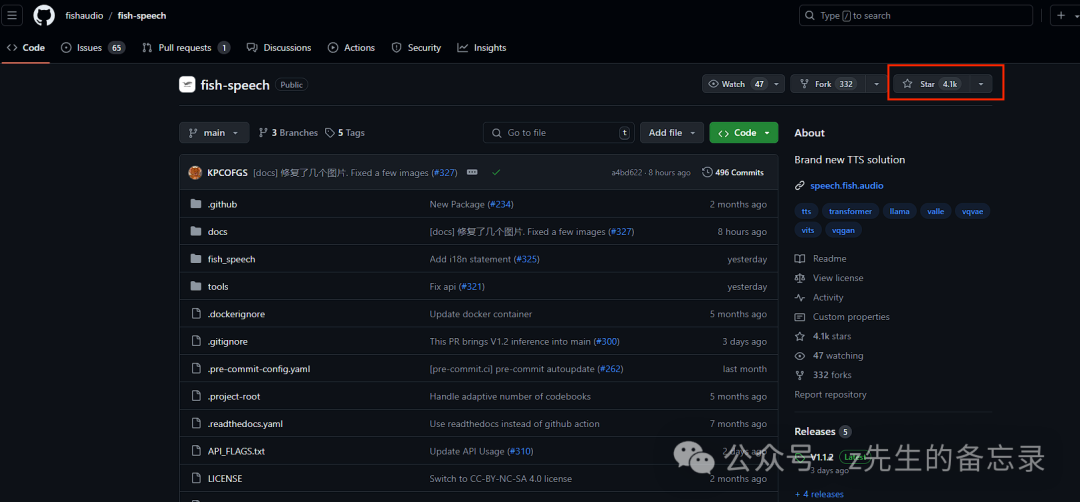 FishSpeech 是一款由 fishaudio 开发的文本转语音(TTS)工具,具有以下特色:
FishSpeech 是一款由 fishaudio 开发的文本转语音(TTS)工具,具有以下特色:
-
多语言支持:支持中文、英文和日语。
-
逼真语音效果:生成的语音效果堪比真人。
-
语音克隆能力:用户提供参考语音后,模型能够快速准确地进行语音克隆。
-
训练数据丰富:使用了大约十五万小时的三语数据进行训练,在中文方面的表现尤为出色。
-
低GPU内存需求:推模推理仅需4GB,微调仅需16GB,消费级显卡完全够用。
-
易用性强: Fish Speech模型参数量小,效果逼真。
下图是fish-speech-1.2的在huggingface上的开源权重: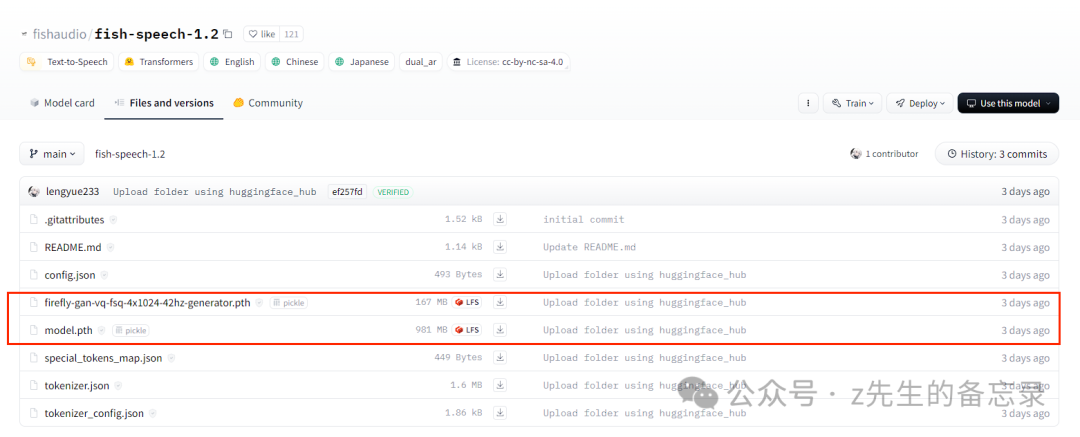
FishSpeech项目提供在线效果demo展示
在线demo效果展示:https://speech.fish.audio/samples/
英文效果展示: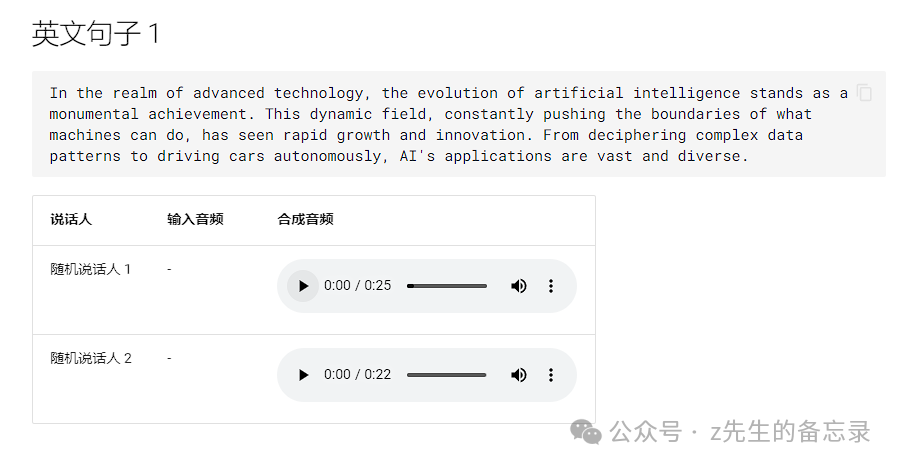
中文效果展示: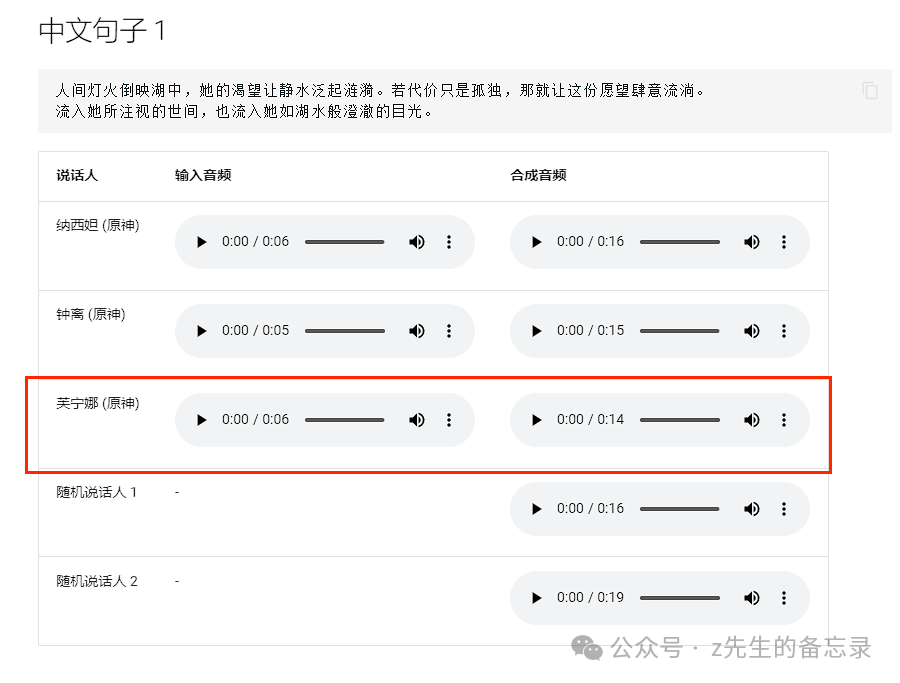
其中效果展示;
面对效果这么惊艳的TTS和声音克隆技术,我决定实操部署推理FishSpeech权重代码,看是否真如官方demo宣传的那样效果好用~
实战篇: FishSpeech部署推理-环境和素材准备
配置项目的环境
from IPython.display import Video,clear_output,Audio,Image
!git clone https://github.com/fishaudio/fish-speech.git
%cd fish-speech
!apt install libsox-dev -y
!pip install -e .
!pip install torchaudio==2.3.1 torch==2.3.1
# 注意torch要升级到最新版本,不然后面推理是会报错
clear_output()
import warnings
warnings.filterwarnings("ignore")
import torch
import torchvision
import torchaudio
import transformers
print("transformers: ", transformers.__version__)
print("torch: ", torch.__version__)
print("torchvision: ", torchvision.__version__)
print("torchaudio: ", torchaudio.__version__)
准备音频素材
为了能够达到官方demo的效果,我决定1:1还原,使用同样的原音频来实现声音克隆。这里我采用上面的"芙宁娜 (原神)"的参考音频来复现看是否通过代码推理也能达到官网的demo里面的效果。
!wget https://demo-r2.speech.fish.audio/v1.1-sft-large/zh/2_input.wav
!git clone https://hf-mirror.com/fishaudio/fish-speech-1.2.git
!tree fish-speech-1.2
对应的fish-speech-1.2目录效果:
 这是官网给的"芙宁娜 (原神)"的参考音频:
这是官网给的"芙宁娜 (原神)"的参考音频:
实战篇: FishSpeech部署推理-声音克隆-效果展示
接下来我将开始进行对声音克隆和推理,具体步骤如下:
第一步:从语音生成 prompt(会输出.npy文件)
!python tools/vqgan/inference.py \
-i "2_input.wav" \
--checkpoint-path "./fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth"
效果展示: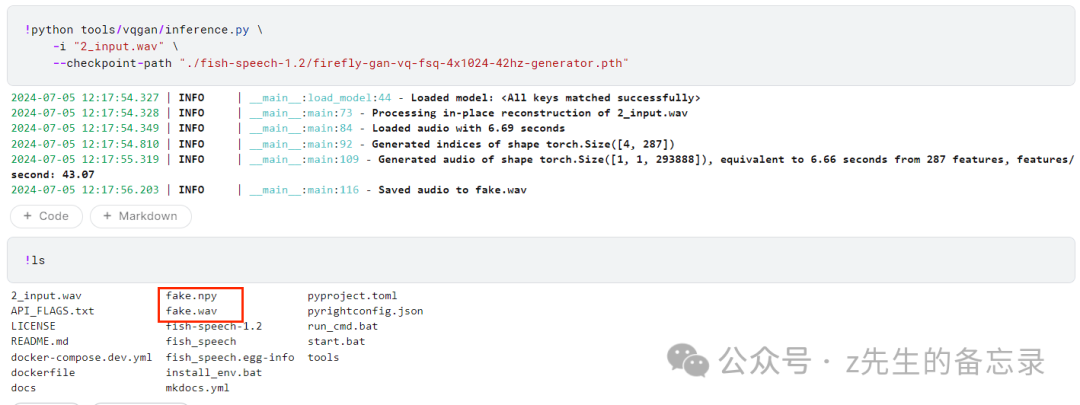 注意这里的fake.npy是非常重要的。
注意这里的fake.npy是非常重要的。
第二步:利用whisper语音识别参考音频的文本
这里我使用openai开源的whisper模型来进行语音识别,可以参考文章【3.26M次下载,2.7k次点赞】OpenAI开源Whisper-large-v3语音识别模型权重,错误率大幅下降,效果惊艳!,下面是我的推理代码:
!pip install -U openai-whisper setuptools-rust
!sudo apt update && sudo apt install ffmpeg -y
clear_output()
!whisper 2_input.wav --model large --output_format srt
输出的结果: 输出参考音频对应的文本:
输出参考音频对应的文本:
既然如此,审判的事就到此结束。
正义之神可不能冤枉了无罪之人。
可以看出识别得非常正确。
第三步:生成文本语义 token
这是我参考官网的demo对应的文本
人间灯火倒映湖中,她的渴望让静水泛起涟漪。
若代价只是孤独,那就让这份愿望肆意流淌。
流入她所注视的世间,也流入她如湖水般澄澈的目光。
这是对应的推理代码:
!python tools/llama/generate.py \
--text "人间灯火倒映湖中,她的渴望让静水泛起涟漪。若代价只是孤独,那就让这份愿望肆意流淌。流入她所注视的世间,也流入她如湖水般澄澈的目光。" \
--prompt-text "既然如此,审判的事就到此结束。正义之神可不能冤枉了无罪之人。" \
--prompt-tokens "./fake.npy" \
--checkpoint-path "./fish-speech-1.2" \
--num-samples 2 \ # 设置输出语音样本的数量
--half
输出的结果: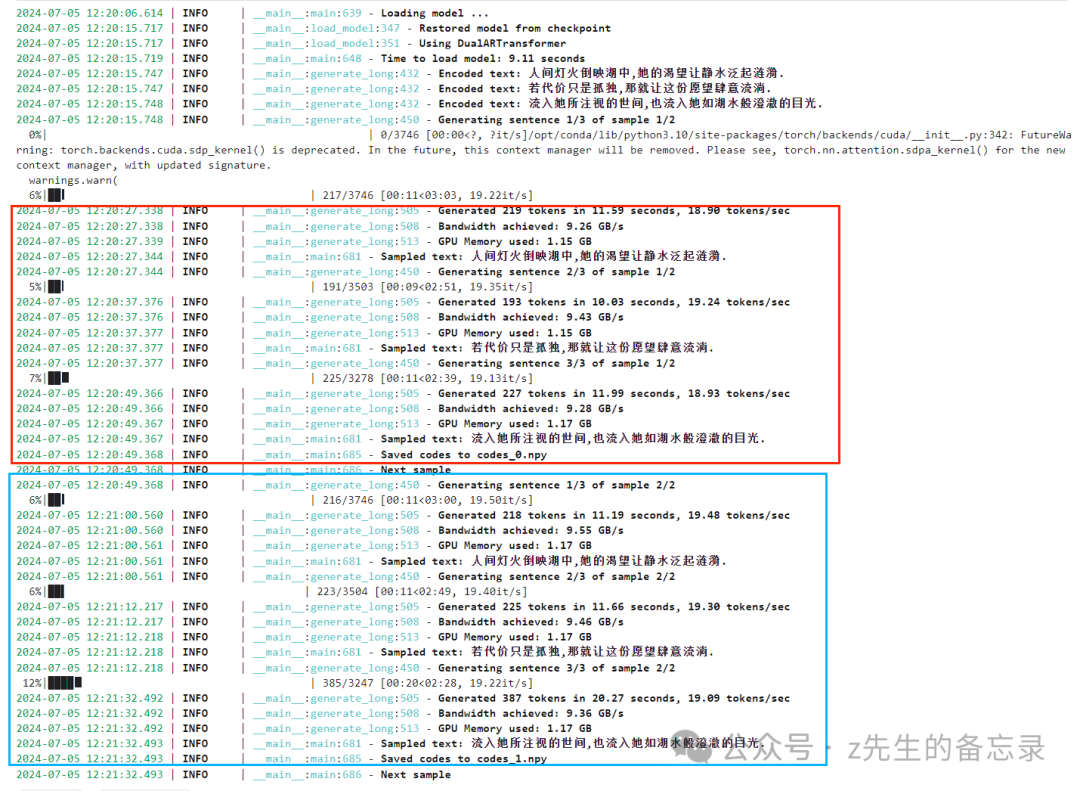 可以看出模型推理过程中生成2个npy文件分别为codes_0.npy、codes_1.npy;对应2个说话人样本。
可以看出模型推理过程中生成2个npy文件分别为codes_0.npy、codes_1.npy;对应2个说话人样本。
第四步:从语义 token 解码生成人声
!python tools/vqgan/inference.py \
-i "codes_0.npy" \
--checkpoint-path "./fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth" \
-o "codes_0.wav"
输出的效果展示: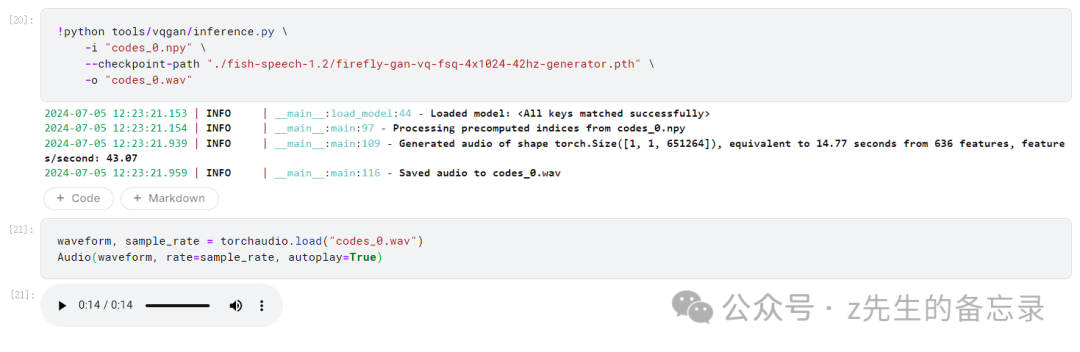 这是最终"芙宁娜 (原神)"输出的tts效果展示:
这是最终"芙宁娜 (原神)"输出的tts效果展示:
下面是官网对应的效果:
效果几乎一致,可以说是准确复现官方demo!该说不说,效果是真的惊艳!
实战篇: FishSpeech部署推理-随机生成说话人-效果展示
第一步:准备文本素材
当你压力大到快要崩溃的时候,不要跟别人讲,也不觉得自己委屈,没有人会心疼你。
要像余华说的那样:在夜深人静的时候,把心掏出来,自己缝缝补补,然后睡一觉醒来,又是信心百倍。
无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事情,而不是让烦恼和焦虑,毁掉你本就不多的热情和定力。
心可以碎,手不能停,该干什么干什么在崩溃中继续前行,这才是一个成年人的素养。
第二步:进行推理生成语义token
!python tools/llama/generate.py \
--text """当你压力大到快要崩溃的时候,不要跟别人讲,也不觉得自己委屈,没有人会心疼你。\
要像余华说的那样:在夜深人静的时候,把心掏出来,自己缝缝补补,然后睡一觉醒来,又是信心百倍。\
无人问津也好,技不如人也罢,你都要试着安静下来,去做自己该做的事情,而不是让烦恼和焦虑,毁掉你本就不多的热情和定力。\
心可以碎,手不能停,该干什么干什么在崩溃中继续前行,这才是一个成年人的素养。""" \
--checkpoint-path "./fish-speech-1.2" \
--num-samples 2 \ # 设置输出语音样本的数量
--half
输出的效果展示: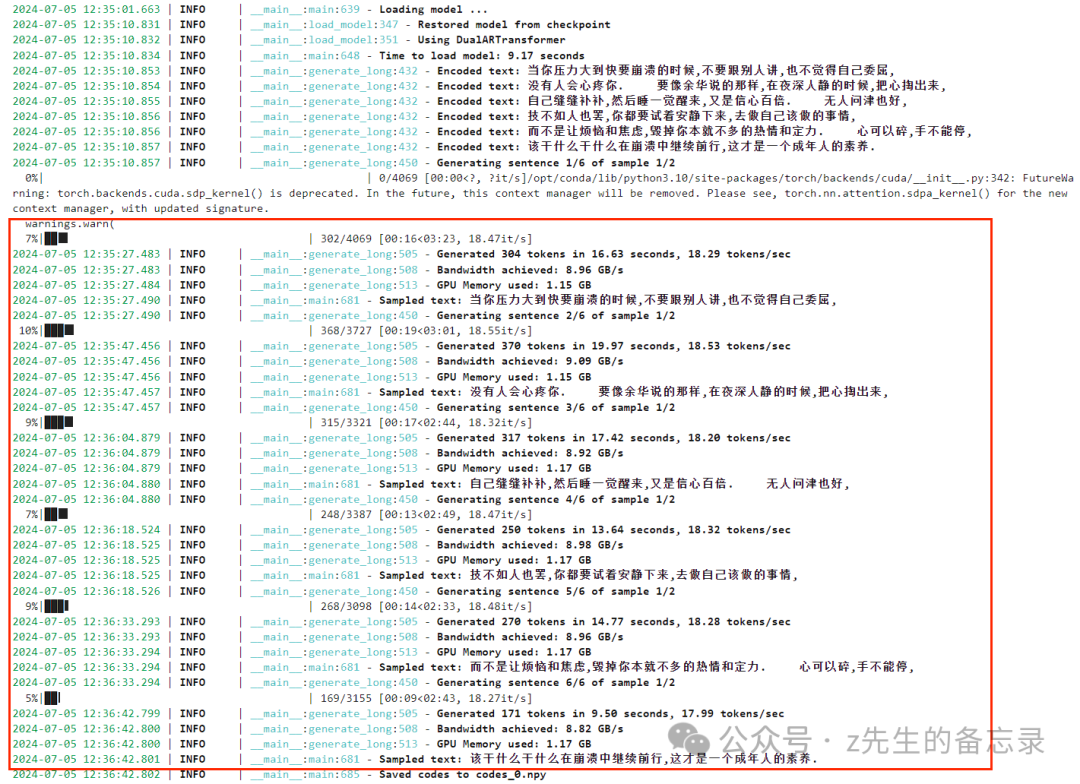 可以看出在这里是没有--prompt-text和--prompt-tokens参数输入的。
可以看出在这里是没有--prompt-text和--prompt-tokens参数输入的。
第三步:从语义token中解码成人声
!python tools/vqgan/inference.py \
-i "codes_0.npy" \
--checkpoint-path "./fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth" \
-o "random_codes_1.wav"
输出的效果展示: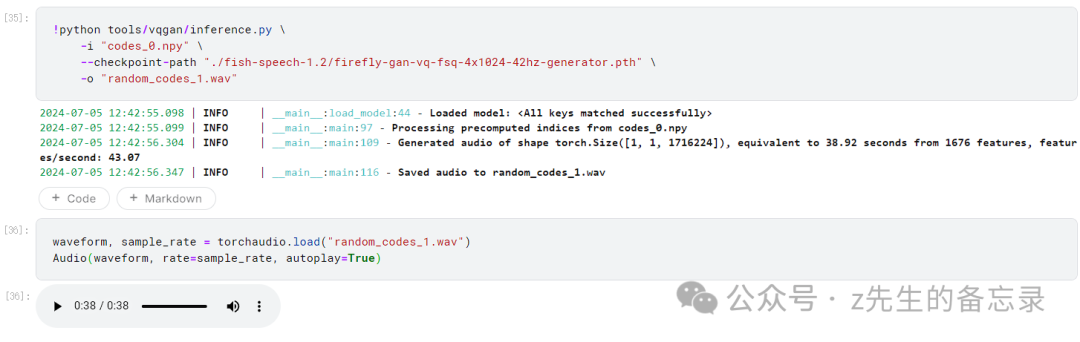 对应的音频效果展示:
对应的音频效果展示:
参考链接
-
fish的官网介绍文档: https://speech.fish.audio/
-
fish的github: https://github.com/fishaudio/fish-speech
-
fish在线demo: https://fish.audio/zh-CN/text-to-speech/
-
fish-speech-1.2模型权重: https://hf-mirror.com/fishaudio/fish-speech-1.2