今天给大家分享一个实操项目[给视频自动生成双语字幕],手把手教你利用 whisper +qwen1.5_110B大模型+ffmpeg 来给视频添加英文字幕,效果惊艳!干货满满!当然你可以翻译成其他语言(日语或者韩语等等),思路大同小异。下面进入今天的主题~
本文目录
-
第一步: 准备短视频素材
-
第二步: 利用whisper来对电影的声音提取对应的字幕
-
whisper 网络结构介绍
-
whisper 命令行用法介绍
-
利用whisper的large模型来识别素材视频中的中文语言
-
利用whisper的large模型来翻译素材视频中的中文语言为英文
-
-
第三步: 利用大模型来进行翻译添加其他语音字幕
-
Qwen1.5_110B大模型来扮演翻译官
-
之前whisper的large模型识别出的中文的内容
-
搭建Qwen1.5_110B来扮演翻译官进行推理测试
-
-
第四步: 解析字幕文件中的中文翻译成英文
-
第五步: 利用FFmpeg来将新生成的字幕合并到视频中
-
给原视频添加字幕
-
调整英文字幕显示的位置
-
-
参考文档
第一步: 准备短视频素材
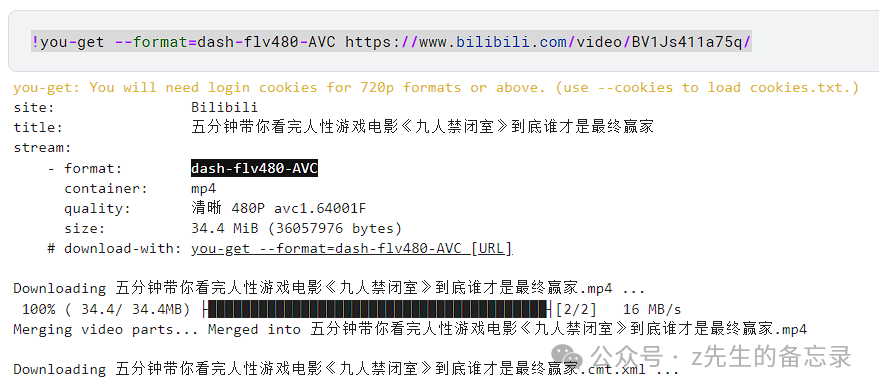
首先我们需要随便找一个短视频作为素材(我在B站上随便找了一个),进行下载:
!you-get --format=dash-flv480-AVC https://www.bilibili.com/video/BV1Js411a75q/
!cp *.mp4 ./demo.mp4
 原始的视频是对<九人禁闭室>电影进行中文二次解说:
原始的视频是对<九人禁闭室>电影进行中文二次解说: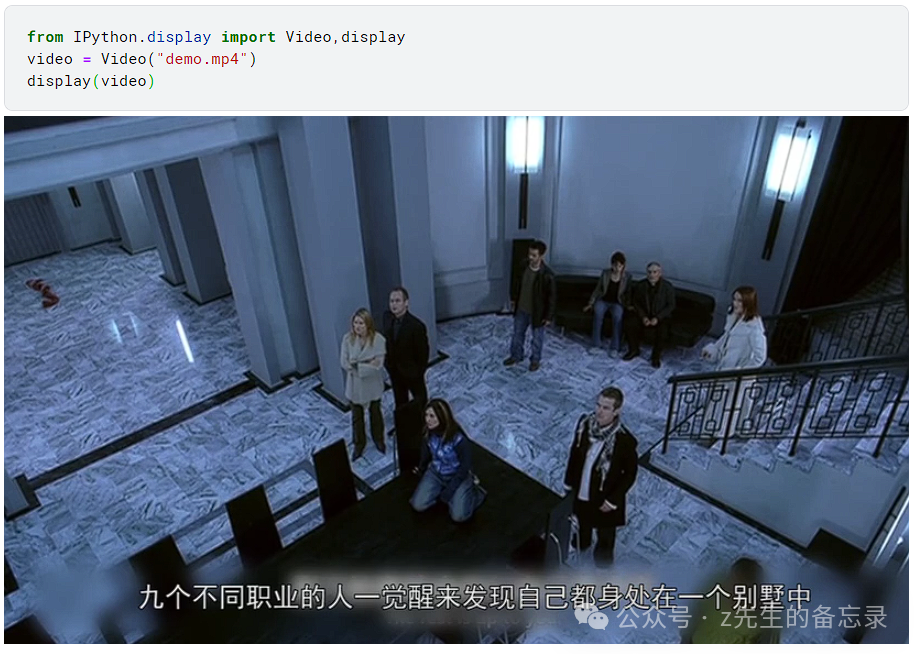 为了便于效果展示,利用ffmpeg来剪切前30秒的视频;
为了便于效果展示,利用ffmpeg来剪切前30秒的视频;
!ffmpeg -i demo.mp4 -ss 0 -to 30 -c copy output.mp4
最终输出的剪切后的视频用于展示(只有前30秒):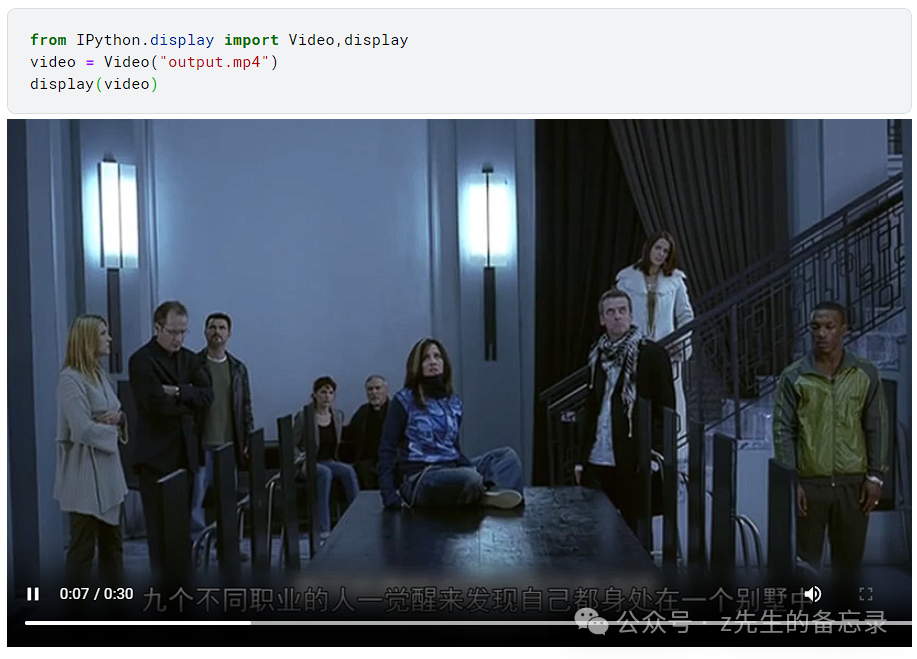
可以看出原视频是中文解说视频,只有中文字幕;我现在想添加对应的英文字幕该怎么办呢~,当然你也可以用各大平台软件来手动操作,今天给大家利用whisper+qwen系列大模型来实现这一过程~
第二步: 利用whisper来对电影的声音提取对应的字幕
whisper 网络结构介绍
Whisper架构是一种简单的端到端方法,实现为编码器-解码器变换器(Transformer),如图。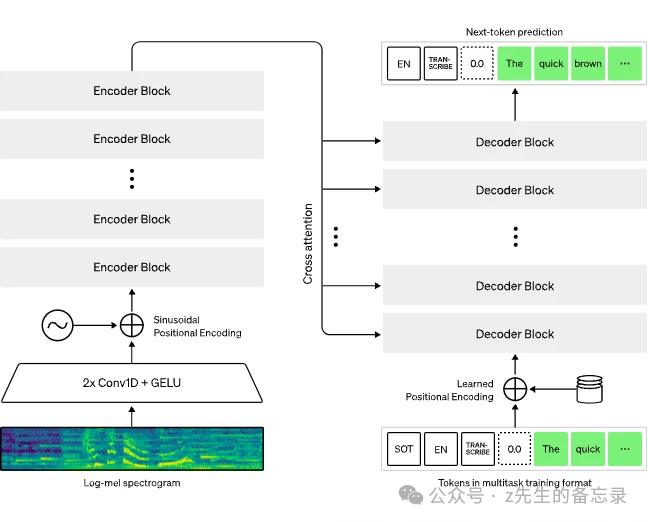 输入的音频被分割成30秒的块,转换成对数Mel频谱图,然后传递给编码器。
输入的音频被分割成30秒的块,转换成对数Mel频谱图,然后传递给编码器。 解码器被训练用来预测相应的文本标题,其中夹杂着特殊标记,这些标记指导单一模型执行诸如语言识别、短语级时间戳、多语种语音转录以及英语语音翻译等任务。
解码器被训练用来预测相应的文本标题,其中夹杂着特殊标记,这些标记指导单一模型执行诸如语言识别、短语级时间戳、多语种语音转录以及英语语音翻译等任务。
whisper 命令行用法介绍
之前给大家介绍过whisper利用权重加载的方式来进行语音识别【3.26M次下载,2.7k次点赞】OpenAI开源Whisper-large-v3语音识别模型权重,错误率大幅下降,效果惊艳!
今天介绍另外一种模式whisper使用命令行模式来处理语音和视频数据,其底层模型调用跟上文提供的权重模型参数是一致的。
whisper 支持的模型版本
下面是whisper各个模型版本的参数信息以及支持语言的能力。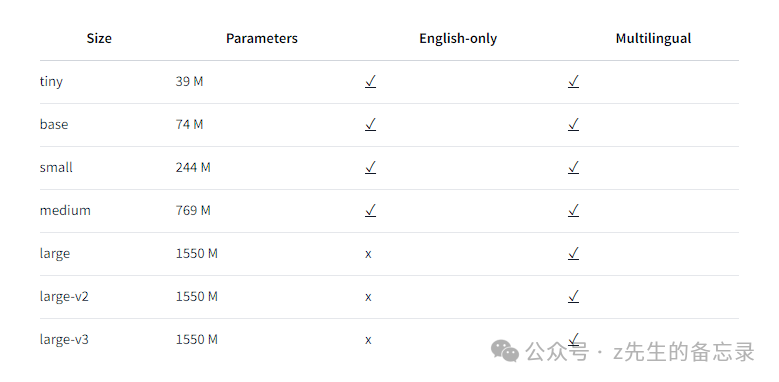 模型参数量越大,模型的效果越好,但是占用的内存也是越多。
模型参数量越大,模型的效果越好,但是占用的内存也是越多。
安装whisper相关的包和环境配置
!pip install -U openai-whisper setuptools-rust
!sudo apt update && sudo apt install ffmpeg -y
whisper最终整体命令行运行常见参数如下:
!whisper your_audio.mp3 -- 输入你的音频和视频
-task transcribe # 指定转录方式,默认使用 transcribe 转录模式, translate 则为 翻译模式,目前只支持翻译成英文。
--model large # 指定使用模型,默认使用 --model small
--language zh# 指定转录语言,默认会截取 30 秒来判断语种;https://github.com/openai/whisper/blob/main/whisper/tokenizer.py
--output_format srt #指定字幕文件的生成格式,txt,vtt,srt,tsv,json,all
-- output_dir ./audio_asr # 指定字幕文件的输出目录,不设置默认输出到当前目录下。
下面我给大家实操一下,自动语音识别样本视频中的中文输出对应的字幕;为了更好的展示效果,我这里采用whisper的large模型来进行测试。
利用whisper的large模型来识别素材视频中的中文语言
!whisper output.mp4 --model large --output_format srt
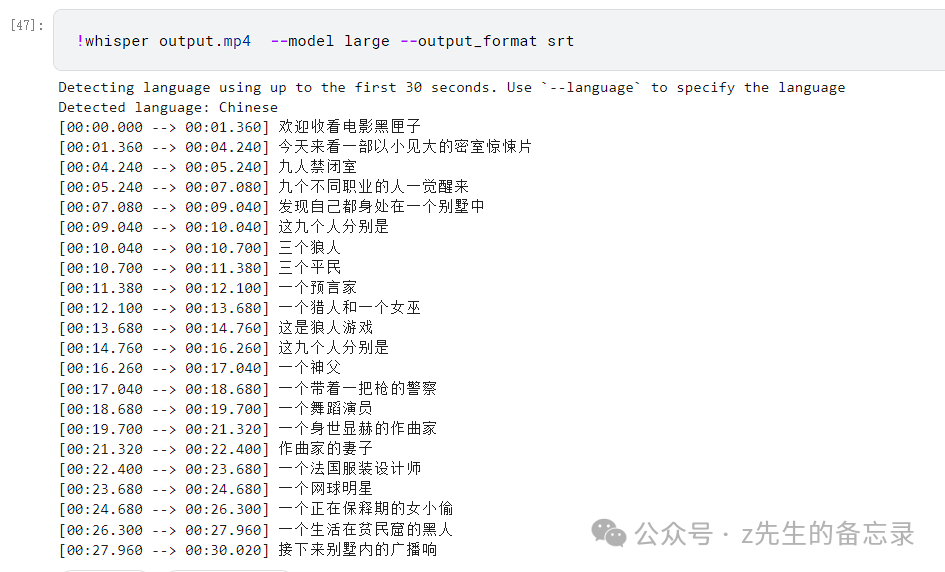 可以看出whisper的large模型识别素材视频的中文,生成的中文字幕结果几乎完全正确。效果非常惊艳!
可以看出whisper的large模型识别素材视频的中文,生成的中文字幕结果几乎完全正确。效果非常惊艳!
利用whisper的large模型来翻译素材视频中的中文语言为英文
!whisper output.mp4 --model large --output_format srt --task translate --output_dir ./audio_asr
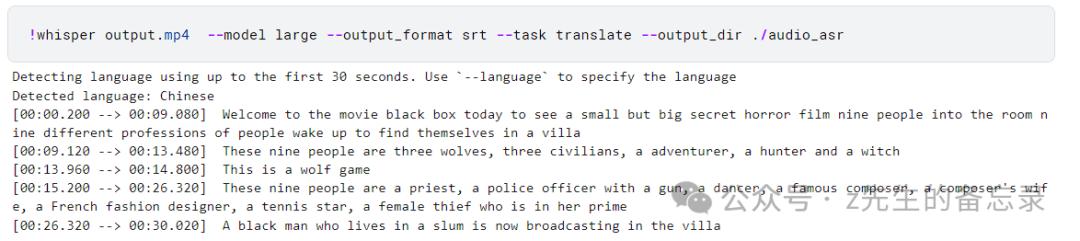 嗯,可以看出在将中文翻译成英文这块,whisper的large模型版本效果还是不够好,其中对应的时间戳和英文翻译都不太对应的上。
嗯,可以看出在将中文翻译成英文这块,whisper的large模型版本效果还是不够好,其中对应的时间戳和英文翻译都不太对应的上。
第三步: 利用大模型来进行翻译添加其他语音字幕
由于whisper的large模型在语音翻译成英文这块效果不好,因为我决定用大模型来对识别出来的中文字幕进行翻译成英文。
Qwen1.5_110B大模型来扮演翻译官
Qwen系列的大模型,之前给大家分享过Qwen2、Qwen-Agent重磅开源!!实操部署Qwen2-7B模型推理效果展示&&语音展示,不愧是大厂出品!!;
当然你可以用最新开源的Qwen2_7B大模型来进行推理实现翻译, 需要本地部署,下载权重推理,可以参考上面的文章;
由于更好的体验效果,我决定给大家展示Qwen1.5_110B的大模型来扮演翻译官进行推理预测;
之前whisper的large模型识别出的中文的内容
!cat output.srt

搭建qwen1.5_110B来扮演翻译官进行推理测试
system_prompt= """
你是一名翻译专家,特别擅长将中文翻译成地道的英文表达,我将给出中文的语句,你直接输出对应的英文地道翻译。
不需要输出其他无关的语言。
"""
response = client.chat.completions.create(
model="QWEN/QWEN1.5-110B-CHAT",
messages=[ {"role": "system", "content": system_prompt},
{"role": "user", "content": "你是谁?你能干什么"}],
)
print(response.choices[0].message.content)
输出的结果:
Who are you and what can you do?
可以看出测试,没有问题~
第四步: 解析字幕文件中的中文翻译成英文
上面我们测试通利用qwen1.5_110B来实现中文翻译成英文,下面我们只需要编写一个脚本将字幕送进大模型中进行依次翻译,但是需要保存格式一致,对应的部分代码如下:
with open("output.srt", "r") as f:
result = f.read()
result = result.split("\n")
total_size = len(result)
from tqdm import tqdm
import time
for index in tqdm(range( int(total_size/4))):
tmp= result[2+4*index]
response = client.chat.completions.create(
model="QWEN/QWEN1.5-110B-CHAT",
messages=[ {"role": "system", "content": system_prompt},
{"role": "user", "content":tmp}],
)
output = response.choices[0].message.content
result[2+4*index]= output
time.sleep(1)
with open("finally_ast.srt","w") as f:
f.write("\n".join(result))
!cat finally_ast.srt
运行的效果展示: 生成的英文字幕
生成的英文字幕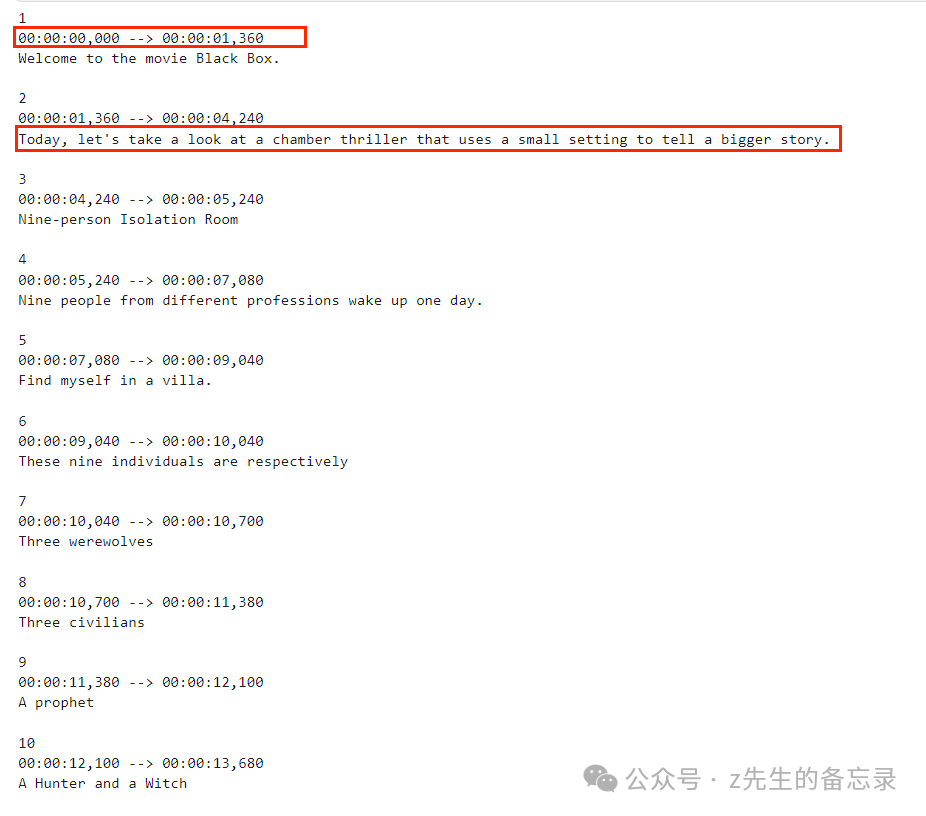
第五步: 利用ffmpeg来将新生成的字幕合并到视频中
给原视频添加字幕
!ffmpeg -i output.mp4 -vf "subtitles=finally_ast.srt" \
-c:a copy release_with_srt.mp4 -y
运行发现出现错误: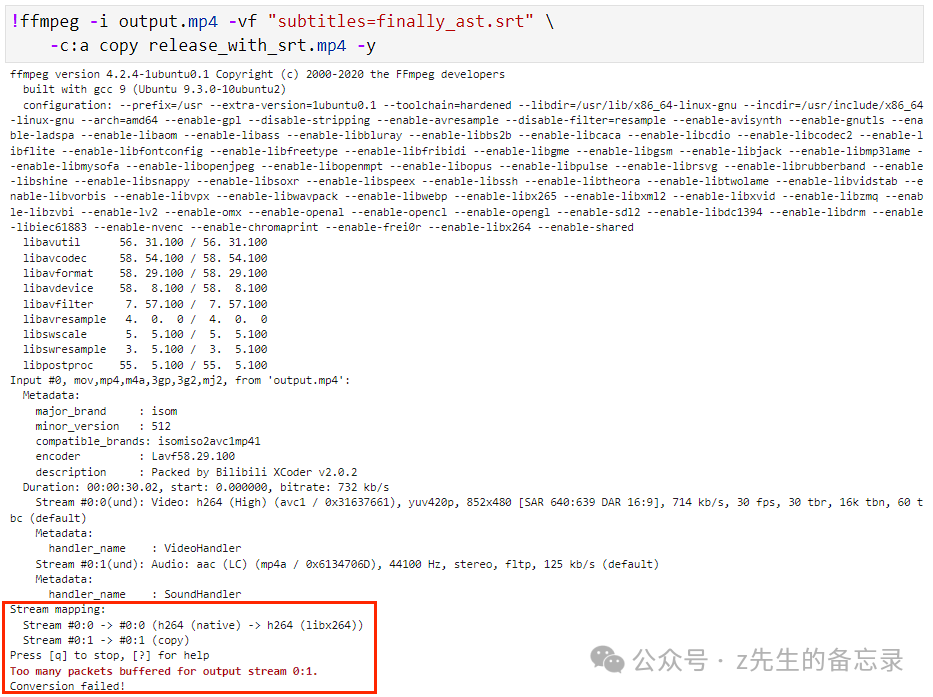
Too many packets buffered for output stream 0:1.
Conversion failed!
经过排查发现是,该异常抛出的原因是部分视频数据有问题,导致视频处理过快,容器封装时队列溢出。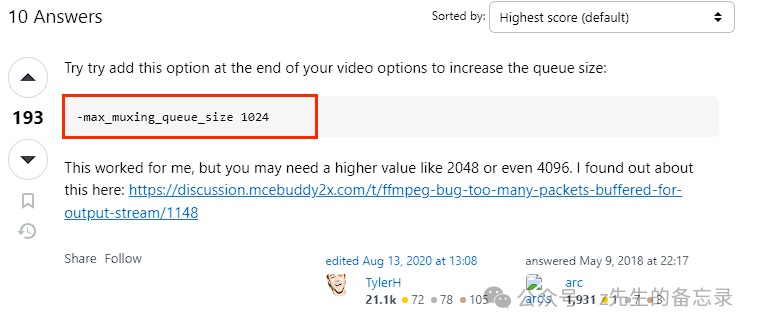 添加该参数后再次执行对应的ffmpeg命令:
添加该参数后再次执行对应的ffmpeg命令:
!ffmpeg -i output.mp4 -vf "subtitles=finally_ast.srt" -max_muxing_queue_size 1024 -c:a copy release_with_srt.mp4 -y
最终输出的视频效果如下: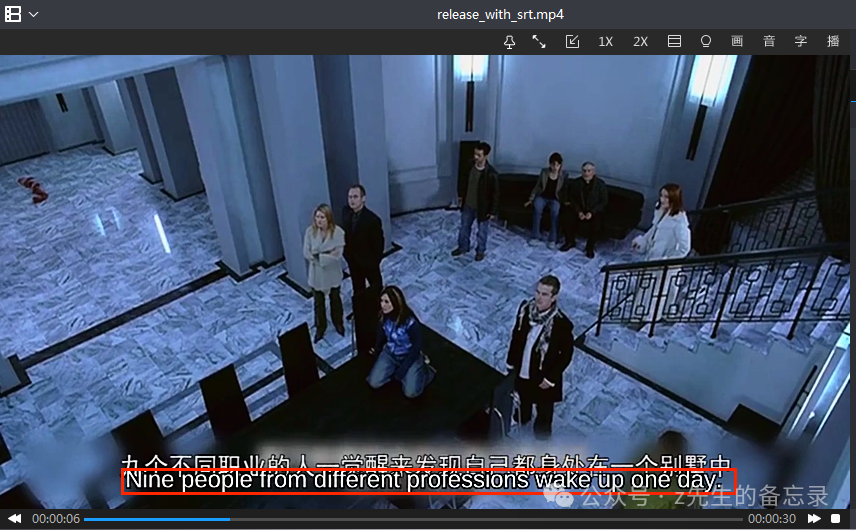 达到我们的效果,在播放视频的同时显示中英文字幕,但是唯一美中不足的是,原视频中的中文字幕和新添加的英文字幕出现重叠,下面我将调节英文字幕的位置。
达到我们的效果,在播放视频的同时显示中英文字幕,但是唯一美中不足的是,原视频中的中文字幕和新添加的英文字幕出现重叠,下面我将调节英文字幕的位置。
调整英文字幕显示的位置
# Alignment=2:底部居中
# MarginV=2:离底部的距离
!ffmpeg -i output.mp4 \
-vf "subtitles=./finally_ast.srt:force_style='Alignment=2,MarginV=2'" \
-max_muxing_queue_size 1024 \
finally_output.mp4 -y
可以看出英文字幕与原视频自带的中文字幕分离开来: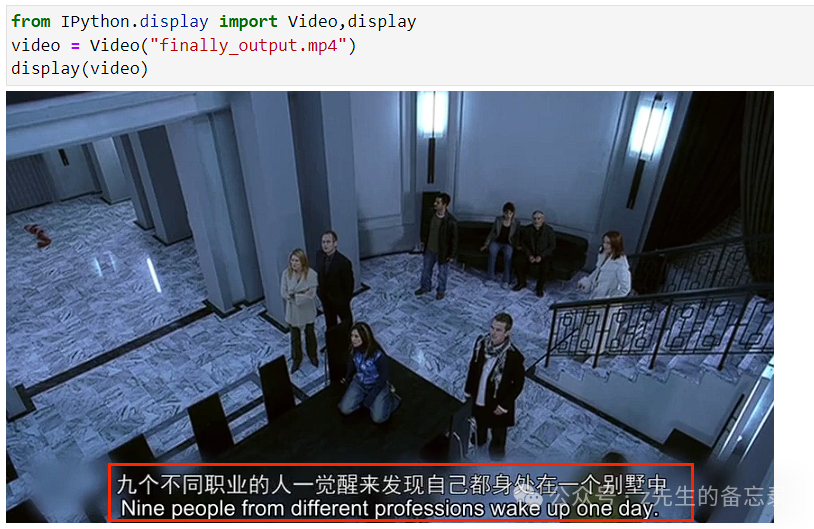
达到我们最终想要的效果,完美~
参考文档
-
https://api.together.xyz
-
https://github.com/openai/whisper
-
https://openai.com/index/whisper/
-
素材视频:https://www.bilibili.com/video/BV1Js411a75q/