英文:
Converting JSON output from API pull to pandas Dataframe?
问题 {#heading}
我可以帮你将asset_list列转化为一个单独的数据框(DataFrame),其中包含asset_ID、asset_class、begin_date_utc、begin_date_mpt和metered_volume作为列名。以下是相应的代码:
import pandas as pd
# 假设你已经有一个名为df的数据框,其中包含了JSON数据
# 首先,将asset_list列展开成一个新的数据框
asset_df = pd.concat([pd.json_normalize(x) for x in df['return']], ignore_index=True)
# 选取所需的列
asset_df = asset_df[['asset_ID', 'asset_class', 'metered_volume_list']]
# 将metered_volume_list列展开
metered_volume_df = pd.concat([pd.json_normalize(x) for x in asset_df['metered_volume_list']], ignore_index=True)
# 选取所需的列
metered_volume_df = metered_volume_df[['begin_date_utc', 'begin_date_mpt', 'metered_volume']]
# 将两个数据框合并
result_df = pd.concat([asset_df[['asset_ID', 'asset_class']], metered_volume_df], axis=1)
# 打印结果数据框
print(result_df)
这段代码将会把asset_list列中的数据展开成一个新的数据框,然后从中选择所需的列,并将metered_volume_list列也展开并选择所需的列,最后将两个数据框合并为一个包含asset_ID、asset_class、begin_date_utc、begin_date_mpt和metered_volume列的数据框。
英文:
I am using an API pull to extract data from the AESO API in python. My code is as follows:
API_KEY = 'api_key_here'
merit_order_url = 'https://api.aeso.ca/report/v1/meteredvolume/details?startDate=2022-01-01'
url = merit_order_url
headers = {'accept': 'application/json', 'X-API-Key': API_KEY}
response = requests.get(url, headers=headers)
The JSON response looks something like this:
{'timestamp': '2023-08-10 14:07:24.976+0000',
'responseCode': '200',
'return': [{'pool_participant_ID': '9496',
'asset_list': [{'asset_ID': '941A',
'asset_class': 'RETAILER',
'metered_volume_list': [{'begin_date_utc': '2022-01-01 07:00',
'begin_date_mpt': '2022-01-01 00:00',
'metered_volume': '0.0005865'},
{'begin_date_utc': '2022-01-01 08:00',
'begin_date_mpt': '2022-01-01 01:00',
'metered_volume': '0.0005363'},
{'begin_date_utc': '2022-01-01 09:00',
'begin_date_mpt': '2022-01-01 02:00',
'metered_volume': '0.0005209'},
{'begin_date_utc': '2022-01-01 10:00',
'begin_date_mpt': '2022-01-01 03:00',
'metered_volume': '0.0005171'},
{'begin_date_utc': '2022-01-01 11:00',
'begin_date_mpt': '2022-01-01 04:00',
'metered_volume': '0.0005152'},
{'begin_date_utc': '2022-01-01 12:00',
'begin_date_mpt': '2022-01-01 05:00',
'metered_volume': '0.0005104'},
{'begin_date_utc': '2022-01-01 13:00',
'begin_date_mpt': '2022-01-01 06:00',
'metered_volume': '0.0005164'},
{'begin_date_utc': '2022-01-01 14:00',
'begin_date_mpt': '2022-01-01 07:00',
'metered_volume': '0.0005426'},
{'begin_date_utc': '2022-01-01 15:00',
'begin_date_mpt': '2022-01-01 08:00',
'metered_volume': '0.0005907'},
{'begin_date_utc': '2022-01-01 16:00',
'begin_date_mpt': '2022-01-01 09:00',
'metered_volume': '0.0006283'},
{'begin_date_utc': '2022-01-01 17:00',
'begin_date_mpt': '2022-01-01 10:00',
'metered_volume': '0.0006528'},
{'begin_date_utc': '2022-01-01 18:00',
'begin_date_mpt': '2022-01-01 11:00',
'metered_volume': '0.0007141'},
{'begin_date_utc': '2022-01-01 19:00',
'begin_date_mpt': '2022-01-01 12:00',
'metered_volume': '0.0007192'},
{'begin_date_utc': '2022-01-01 20:00',
'begin_date_mpt': '2022-01-01 13:00',
'metered_volume': '0.0007495'},
{'begin_date_utc': '2022-01-01 21:00',
'begin_date_mpt': '2022-01-01 14:00',
'metered_volume': '0.0006842'},
{'begin_date_utc': '2022-01-01 22:00',
'begin_date_mpt': '2022-01-01 15:00',
'metered_volume': '0.0006804'},
{'begin_date_utc': '2022-01-01 23:00',
'begin_date_mpt': '2022-01-01 16:00',
'metered_volume': '0.0007282'},
{'begin_date_utc': '2022-01-02 00:00',
'begin_date_mpt': '2022-01-01 17:00',
'metered_volume': '0.0008322'},
{'begin_date_utc': '2022-01-02 01:00',
'begin_date_mpt': '2022-01-01 18:00',
'metered_volume': '0.0008516'},
{'begin_date_utc': '2022-01-02 02:00',
'begin_date_mpt': '2022-01-01 19:00',
'metered_volume': '0.0007729'},
{'begin_date_utc': '2022-01-02 03:00',
'begin_date_mpt': '2022-01-01 20:00',
'metered_volume': '0.0006861'},
{'begin_date_utc': '2022-01-02 04:00',
'begin_date_mpt': '2022-01-01 21:00',
'metered_volume': '0.0006861'},
{'begin_date_utc': '2022-01-02 05:00',
'begin_date_mpt': '2022-01-01 22:00',
'metered_volume': '0.0006434'},
{'begin_date_utc': '2022-01-02 06:00',
'begin_date_mpt': '2022-01-01 23:00',
'metered_volume': '0.0005783'}]},
{'asset_ID': '941C',
'asset_class': 'RETAILER',
'metered_volume_list': [{'begin_date_utc': '2022-01-01 07:00',
'begin_date_mpt': '2022-01-01 00:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 08:00',
'begin_date_mpt': '2022-01-01 01:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 09:00',
'begin_date_mpt': '2022-01-01 02:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 10:00',
'begin_date_mpt': '2022-01-01 03:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 11:00',
'begin_date_mpt': '2022-01-01 04:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 12:00',
'begin_date_mpt': '2022-01-01 05:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 13:00',
'begin_date_mpt': '2022-01-01 06:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 14:00',
'begin_date_mpt': '2022-01-01 07:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 15:00',
'begin_date_mpt': '2022-01-01 08:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 16:00',
'begin_date_mpt': '2022-01-01 09:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 17:00',
'begin_date_mpt': '2022-01-01 10:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 18:00',
'begin_date_mpt': '2022-01-01 11:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 19:00',
'begin_date_mpt': '2022-01-01 12:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 20:00',
'begin_date_mpt': '2022-01-01 13:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 21:00',
'begin_date_mpt': '2022-01-01 14:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 22:00',
'begin_date_mpt': '2022-01-01 15:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-01 23:00',
'begin_date_mpt': '2022-01-01 16:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 00:00',
'begin_date_mpt': '2022-01-01 17:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 01:00',
'begin_date_mpt': '2022-01-01 18:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 02:00',
'begin_date_mpt': '2022-01-01 19:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 03:00',
'begin_date_mpt': '2022-01-01 20:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 04:00',
'begin_date_mpt': '2022-01-01 21:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 05:00',
'begin_date_mpt': '2022-01-01 22:00',
'metered_volume': '0'},
{'begin_date_utc': '2022-01-02 06:00',
'begin_date_mpt': '2022-01-01 23:00',
'metered_volume': '0'}]},
When I use the following code:
df1 = pd.json_normalize(df['return'])
The dataset looks like the following:
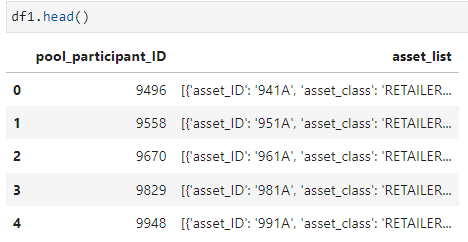
I would like to convert the asset_list column into its own dataframe. Where asset_ID, asset_class, begin_date_utc, begin_date_mpt andmetered_volume` are column. How would I go about this?
答案1 {#1}
得分: 3
使用 json_normalize(),您需要映射 meta 和 record_path 中的级别:
代码:
df = pd.json_normalize(
data=data,
meta=[
["return", "pool_participant_ID"],
["return", "asset_list", "asset_ID"],
["return", "asset_list", "asset_class"],
],
record_path=["return", "asset_list", "metered_volume_list"]
).rename(columns=lambda x: x.split(".")[-1])
print(df)
输出:
begin_date_utc begin_date_mpt metered_volume pool_participant_ID asset_ID asset_class
0 2022-01-01 07:00 2022-01-01 00:00 0.0005865 9496 941A RETAILER
1 2022-01-01 08:00 2022-01-01 01:00 0.0005363 9496 941A RETAILER
2 2022-01-01 09:00 2022-01-01 02:00 0.0005209 9496 941A RETAILER
3 2022-01-01 10:00 2022-01-01 03:00 0.0005171 9496 941A RETAILER
4 2022-01-01 11:00 2022-01-01 04:00 0.0005152 9496 941A RETAILER
5 2022-01-01 12:00 2022-01-01 05:00 0.0005104 9496 941A RETAILER
6 2022-01-01 13:00 2022-01-01 06:00 0.0005164 9496 941A RETAILER
7 2022-01-01 14:00 2022-01-01 07:00 0.0005426 9496 941A RETAILER
8 2022-01-01 15:00 2022-01-01 08:00 0.0005907 9496 941A RETAILER
9 2022-01-01 16:00 2022-01-01 09:00 0.0006283 9496 941A RETAILER
10 2022-01-01 17:00 2022-01-01 10:00 0.0006528 9496 941A RETAILER
11 2022-01-01 18:00 2022-01-01 11:00 0.0007141 9496 941A RETAILER
12 2022-01-01 19:00 2022-01-01 12:00 0.0007192 9496 941A RETAILER
13 2022-01-01 20:00 2022-01-01 13:00 0.0007495 9496 941A RETAILER
14 2022-01-01 21:00 2022-01-01 14:00 0.0006842 9496 941A RETAILER
15 2022-01-01 22:00 2022-01-01 15:00 0.0006804 9496 941A RETAILER
16 2022-01-01 23:00 2022-01-01 16:00 0.0007282 9496 941A RETAILER
17 2022-01-02 00:00 2022-01-01 17:00 0.0008322 9496 941A RETAILER
18 2022-01-02 01:00 2022-01-01 18:00 0.0008516 9496 941A RETAILER
19 2022-01-02 02:00 2022-01-01 19:00 0.0007729 9496 941A RETAILER
20 2022-01-02 03:00 2022-01-01 20:00 0.0006861 9496 941A RETAILER
21 2022-01-02 04:00 2022-01-01 21:00 0.0006861 9496 941A RETAILER
22 2022-01-02 05:00 2022-01-01 22:00 0.0006434 9496 941A RETAILER
23 2022-01-02 06:00 2022-01-01 23:00 0.0005783 9496 941A RETAILER
24 2022-01-01 07:00 2022-01-01 00:00 0 9496 941C RETAILER
25 2022-01-01 08:00 2022-01-01 01:00 0 9496 941C RETAILER
26 2022-01-01 09:00 2022-01-01 02:00 0 9496 941C RETAILER
27 2022-01-01 10:00 2022-01-01 03:00 0 9496 941C RETAILER
28 2022-01-01 11:00 2022-01-01 04:00 0 9496 941C RETAILER
29 2022-01-01 12:00 2022-01-01 05:00 0 9496 941C RETAILER
30 2022-01-01 13:00 2022-01-01 06:00 0 9496 941C RETAILER
31 2022-01-01 14:00 2022-01-01 07:00 0 9496
<details>
<summary>英文:</summary>
Using [json_normalize()][1] You need to map the levels in meta and record_path:
Code:
df = pd.json_normalize(
data=data,
meta=[
["return", "pool_participant_ID"],
["return", "asset_list", "asset_ID"],
["return", "asset_list", "asset_class"],
],
record_path=["return", "asset_list", "metered_volume_list"]
).rename(columns=lambda x: x.split(".")[-1])
print(df)
Output:
begin_date_utc begin_date_mpt metered_volume pool_participant_ID asset_ID asset_class
0 2022-01-01 07:00 2022-01-01 00:00 0.0005865 9496 941A RETAILER
1 2022-01-01 08:00 2022-01-01 01:00 0.0005363 9496 941A RETAILER
2 2022-01-01 09:00 2022-01-01 02:00 0.0005209 9496 941A RETAILER
3 2022-01-01 10:00 2022-01-01 03:00 0.0005171 9496 941A RETAILER
4 2022-01-01 11:00 2022-01-01 04:00 0.0005152 9496 941A RETAILER
5 2022-01-01 12:00 2022-01-01 05:00 0.0005104 9496 941A RETAILER
6 2022-01-01 13:00 2022-01-01 06:00 0.0005164 9496 941A RETAILER
7 2022-01-01 14:00 2022-01-01 07:00 0.0005426 9496 941A RETAILER
8 2022-01-01 15:00 2022-01-01 08:00 0.0005907 9496 941A RETAILER
9 2022-01-01 16:00 2022-01-01 09:00 0.0006283 9496 941A RETAILER
10 2022-01-01 17:00 2022-01-01 10:00 0.0006528 9496 941A RETAILER
11 2022-01-01 18:00 2022-01-01 11:00 0.0007141 9496 941A RETAILER
12 2022-01-01 19:00 2022-01-01 12:00 0.0007192 9496 941A RETAILER
13 2022-01-01 20:00 2022-01-01 13:00 0.0007495 9496 941A RETAILER
14 2022-01-01 21:00 2022-01-01 14:00 0.0006842 9496 941A RETAILER
15 2022-01-01 22:00 2022-01-01 15:00 0.0006804 9496 941A RETAILER
16 2022-01-01 23:00 2022-01-01 16:00 0.0007282 9496 941A RETAILER
17 2022-01-02 00:00 2022-01-01 17:00 0.0008322 9496 941A RETAILER
18 2022-01-02 01:00 2022-01-01 18:00 0.0008516 9496 941A RETAILER
19 2022-01-02 02:00 2022-01-01 19:00 0.0007729 9496 941A RETAILER
20 2022-01-02 03:00 2022-01-01 20:00 0.0006861 9496 941A RETAILER
21 2022-01-02 04:00 2022-01-01 21:00 0.0006861 9496 941A RETAILER
22 2022-01-02 05:00 2022-01-01 22:00 0.0006434 9496 941A RETAILER
23 2022-01-02 06:00 2022-01-01 23:00 0.0005783 9496 941A RETAILER
24 2022-01-01 07:00 2022-01-01 00:00 0 9496 941C RETAILER
25 2022-01-01 08:00 2022-01-01 01:00 0 9496 941C RETAILER
26 2022-01-01 09:00 2022-01-01 02:00 0 9496 941C RETAILER
27 2022-01-01 10:00 2022-01-01 03:00 0 9496 941C RETAILER
28 2022-01-01 11:00 2022-01-01 04:00 0 9496 941C RETAILER
29 2022-01-01 12:00 2022-01-01 05:00 0 9496 941C RETAILER
30 2022-01-01 13:00 2022-01-01 06:00 0 9496 941C RETAILER
31 2022-01-01 14:00 2022-01-01 07:00 0 9496 941C RETAILER
32 2022-01-01 15:00 2022-01-01 08:00 0 9496 941C RETAILER
33 2022-01-01 16:00 2022-01-01 09:00 0 9496 941C RETAILER
34 2022-01-01 17:00 2022-01-01 10:00 0 9496 941C RETAILER
35 2022-01-01 18:00 2022-01-01 11:00 0 9496 941C RETAILER
36 2022-01-01 19:00 2022-01-01 12:00 0 9496 941C RETAILER
37 2022-01-01 20:00 2022-01-01 13:00 0 9496 941C RETAILER
38 2022-01-01 21:00 2022-01-01 14:00 0 9496 941C RETAILER
39 2022-01-01 22:00 2022-01-01 15:00 0 9496 941C RETAILER
40 2022-01-01 23:00 2022-01-01 16:00 0 9496 941C RETAILER
41 2022-01-02 00:00 2022-01-01 17:00 0 9496 941C RETAILER
42 2022-01-02 01:00 2022-01-01 18:00 0 9496 941C RETAILER
43 2022-01-02 02:00 2022-01-01 19:00 0 9496 941C RETAILER
44 2022-01-02 03:00 2022-01-01 20:00 0 9496 941C RETAILER
45 2022-01-02 04:00 2022-01-01 21:00 0 9496 941C RETAILER
46 2022-01-02 05:00 2022-01-01 22:00 0 9496 941C RETAILER
47 2022-01-02 06:00 2022-01-01 23:00 0 9496 941C RETAILER
[1]: https://pandas.pydata.org/docs/reference/api/pandas.json_normalize.html
</details>
# 答案2
**得分**: 2
你可以尝试这样做。对于列表部分使用 `explode`,然后再次对嵌套对象使用 `json_normalize`。
```python
df = (pd.json_normalize(df['return'], record_path=['asset_list'])
.explode('metered_volume_list'))
df = pd.concat([df[['asset_ID', 'asset_class']].reset_index(drop=True),
pd.json_normalize(df.metered_volume_list)], axis=1)
英文:
you can try this. Use explode for the list and use json_normalize again on the nested object.
df = (pd.json_normalize(df['return'], record_path=['asset_list'])
.explode('metered_volume_list'))
df = pd.concat([df[['asset_ID', 'asset_class']].reset_index(drop=True),
pd.json_normalize(df.metered_volume_list)], axis=1)





{kind=link}