01
背景
用户在升级到CDP或Impala-3.4后,可能遇到JDBC/ODBC driver返回不完整数据的情况。比如实际查询结果有100行,但返回90行就结束了,每次的结果不一定相同,只有在时长超过10秒的查询会出现。这可能是遇到了JDBC/ODBC driver的bug,可以尝试以下两种方式解决:
-
Query Option 里 set fetch_rows_timeout_ms=0
-
升级driver版本,JDBC driver版本至少要到2.6.20,ODBC driver版本至少要到2.6.12
如果以上方法有效,就跟我们要讲的这个bug有关。
02
客户端流程
客户端与Coordinator交互有两种协议:beeswax和hs2协议。它们都是基于Thrift实现的,各种接口基本上能一一对应。对于一个查询的执行,客户端的请求流程如下,以beeswax协议为例: 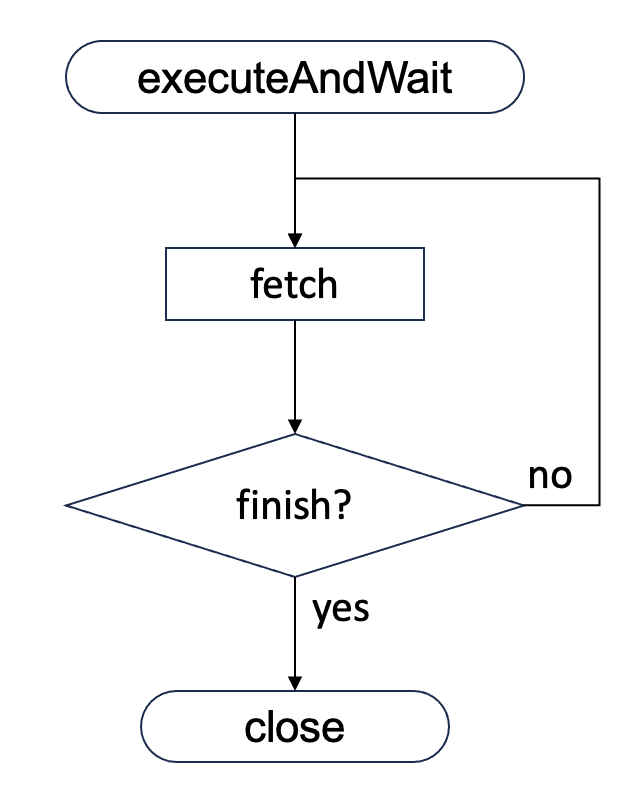 对应的HS2 RPC如下:
对应的HS2 RPC如下:
| beeswax | hs2 | |:--------------:|:----------------:| | executeAndWait | ExecuteStatement | | fetch | FetchResults | | close | CloseOperation |
问题出在finish的判定上。
03
Finish判定 Beeswax 的 fetch RPC 和 HS2 的 FetchResults RPC 的返回类型定义如下:
// beeswax result
struct Results {
// If set, data is valid. Otherwise, results aren't ready yet.
1: bool ready,
// Columns for the results
2: list<string> columns,
// A set of results
3: list<string> data,
// The starting row of the results
4: i64 start_row,
// Whether there are more results to fetch
5: bool has_more
}
// hs2 result
struct TFetchResultsResp {
1: required TStatus status
// TRUE if there are more rows left to fetch from the server.
2: optional bool hasMoreRows
// The rowset. This is optional so that we have the
// option in the future of adding alternate formats for
// representing result set data, e.g. delimited strings,
// binary encoded, etc.
3: optional TRowSet results
}
它们除了返回一组数据,还返回一个bool值(has_more、hasMoreRows)标记是否还有更多的数据。理论上用这个值来判断是否要结束就可以了,但如果客户端偷懒,只判断返回的数据是否为空,是否也可行呢? 04
流水线执行
Impala使用MPP架构设计,区别于MR、Spark、Tez等BSP模式的一大特点是流水线式执行。查询计划由多段流水线组成,查询的执行由流水线的消费者驱动。客户端就是最后一条流水线的消费者。 客户端开始获取结果时,流水线的另一端可能还在执行。比如一个简单的 select ... from tableA where col = 'A' 查询,ScanNode是分布式执行的,每个ScanNode内部也是流式执行的,每次读一片数据过滤完就可以返回结果。因此客户端可以开始拉取数据时(即 "Rows Available" 状态),并不代表所有结果都已经生成了。有可能第一批数据被拉取完后,要过10秒或更长的时间才能拉取下一批数据。 05
IMPALA-7312后 fetch RPC 的变化
在 IMPALA-7312 之前,fetch请求是阻塞式的,会卡住直到有查询结果可返回为止。因此 fetch 返回的结果都有数据。直到所有结果都被拉取完时,fetch 才会返回空集。虽然这是老版本Impala的表现,但这并不是一个定义好的行为,实际上还得用 has_more/hasMoreRows 标记来判定是否还有结果没拉取。 IMPALA-7312 引入了 fetch_rows_timeout_ms 这个查询选项,给 fetch 请求加了超时。服务器端(即coordinator)会在超时前返回一个结果,该结果可能为空,但has_more/hasMoreRows 会标记查询结果是否全返回了。如果客户端没有判断 has_more/hasMoreRows,只看 fetch 返回的结果集是否为空,就可能误判结束标志。此时只能设 fetch_rows_timeout_ms = 0 来绕过这个超时机制。 由于 impala-shell 一直是有判定 has_more / hasMoreRows 这个域的,所以不受影响。这个问题主要出在 Impala JDBC/ODBC driver上。 06
升级Driver 这个问题在 Impala JDBC/ODBC 的 Release Note 中都有提及,如 JDBC driver 2.6.20: Released 2020-12-18
The following issues have been resolved in Simba Impala JDBC Driver 2.6.20.
- [00265194][IMPJ-606] When the server returns 0 rows, the driver stops fetching results.
ODBC driver 2.6.12:
Released 2020-12-23
The following issue has been resolved in Cloudera ODBC Driver for Impala 2.6.12.
- [IMP-806][00265194] When the server returns 0 rows, the driver stops fetching results.
07
总结 Impala JDBC/ODBC driver 使用了未定义的方式来判定查询结束,该方式在 IMPALA-7312 之后不可行。因此解决办法是关闭 IMPALA-7312 引入的超时机制(即 set fetch_rows_timeout_ms = 0)或者升级 driver 版本,JDBC driver版本至少要到2.6.20,ODBC driver版本至少要到2.6.12。
关注Impala 公众号,及时获取更多Impala资讯