目录一、背景
二、方案流程
-
方案可行性评估口径
-
方案设计
-
方案规划
-
方案实施
-
方案验证&验收
三、方案成果
四、方案展望一 引言 2024年之前,DBA维护的StarRocks集群存在在用低版本多、稳定性受组件bug影响大的问题,给日常运维带来一定压力,版本升级迫在眉睫。于是,我们在今年年初安排了针对2.5以下版本升级2.5.13的专项。这里和大家分享下,针对因版本兼容问题而不能原地升级的场景下,进行跨集群升级时迁移数据方面的实践。 二 方案流程 方案可行性评估口径 针对跨集群迁移方案的评估,主要从迁移成本角度考虑,主要分为资源成本和稳定性成本:
资源成本 完成迁移所需要的人力工时投入、软硬件投入(如使用哪些三方平台、需要多少机器资源、带宽资源等)。 稳定性成本 数据迁移过程中,线上业务一般仍会继续提供服务,则迁移操作对系统产生的压力可能影响正常的生产服务,随之会带来额外的稳定性成本。这里从迁移服务产生系统压力的可监控预警能力评估稳定性成本。 方案设计 方案一:StarRocks外表 1. 技术原理 1.19 版本开始,StarRocks支持将数据通过外表方式写入另一个StarRocks集群的表中。这可以解决用户的读写分离需求,提供更好的资源隔离。用户需要首先在目标集群上创建一张目标表,然后在源StarRocks集群上创建一个Schema信息一致的外表,并在属性中指定目标集群和表的信息。 通过INSERT INTO写入数据至StarRocks外表,可以将源集群的数据写入至目标集群。借助这一能力,可以实现如下目标:
-
集群间的数据同步;
-
读写分离。向源集群中写入数据,并且源集群的数据变更同步至目标集群,目标集群提供查询服务。
2. 方案评估  3. 适用场景
3. 适用场景
-
数据量较小(200G以内);
-
无三方平台可用;
-
数据迁移无需考虑稳定性成本;
-
测试场景快速验证;
-
存在hll、bitmap类型字段,但是又没有底表数据进行数据重建(hll/bitmap类型字段借助三方组件进行迁移的方案可参考官方文档flink导入至-bitmap-列、flink导入导入至-hll-列等);
-
Array/Map/Row等复杂类型的迁移。方案二:Flink Connector 1. 技术原理 Flink是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。随着不断迭代,Flink已提供了接口统一的批流处理模型定义,同时提供了灵活强大的DataStream API和抽象度更高的Table API,供开发人员尽情发挥,更提供了SQL支持。 Flink提供了丰富的Connector,用以打通各类数据源,形成强大的数据联通能力。StarRocks官方也推出了导入和导出Connector,满足基于Flink对StarRocks的读写能力。 2. 方案评估
 3. 适用场景
3. 适用场景 -
数据量较大;
-
有三方平台可用;
-
稳定性要求高,期望控制稳定性成本;
-
有24h持续同步需求。方案规划 在同步操作前,需要明确待同步的数据范围,统计较精确的待迁移数据量,评估数据迁移所需耗时,决策数据迁移完成时间等。
 方式一 结合预期的同步完成DDL,集群每天可用于同步的时间段,推导出同步时需要达到的速率。 计算公式: 预期同步最大速率(MB/s)=待同步数据总量(MB)/同步总耗时(天)/每天可同步时间(个小时/天) 方式二 根据集群负载可支持的最大速率、集群每天可用于同步的时间段,计算完成同步所需的时间。 同步总耗时(天)=待同步数据总量(MB)/预期同步最大速率(MB/s)/每天可同步时间(个小时/天) 注意
方式一 结合预期的同步完成DDL,集群每天可用于同步的时间段,推导出同步时需要达到的速率。 计算公式: 预期同步最大速率(MB/s)=待同步数据总量(MB)/同步总耗时(天)/每天可同步时间(个小时/天) 方式二 根据集群负载可支持的最大速率、集群每天可用于同步的时间段,计算完成同步所需的时间。 同步总耗时(天)=待同步数据总量(MB)/预期同步最大速率(MB/s)/每天可同步时间(个小时/天) 注意 -
准确的待迁移数据量评估,依赖数据时间范围的确认。对于新旧集群双写场景,同步的最晚时间是完全双写介入的那一天(包含)。
-
预期同步最大速率(MB/s),需要兼顾集群当前流量和预估可承受的最大流量,避免因数据同步给集群造成预期外的压力,影响线上服务稳定性。
方案实施 方案一:外表 1. 创建外表 在源集群/库 上创建外表,指向目标集群。 建议创建一个外表专用db,用于与源db隔离,避免误操作风险。
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
CREATE EXTERNAL TABLE external_db.external_t( k1 DATE, k2 INT, k3 SMALLINT, k4 VARCHAR(2048), k5 DATETIME)ENGINE=olapDUPLICATE KEY(`timestamp`)PARTITION BY RANGE(`timestamp`)(PARTITION p20231016 VALUES [("2023-10-16 00:00:00"), ("2023-10-17 00:00:00")),PARTITION p20231017 VALUES [("2023-10-17 00:00:00"), ("2023-10-18 00:00:00")))DISTRIBUTED BY HASH(k1) BUCKETS 10PROPERTIES( "host" = "127.0.0.x", "port" = "9020", "user" = "${user}", "password" = "${passwd}", "database" = "test_db", "table" = "t");
2. 写入外表 在源集群/库上写入外表。 *
insert into external_db.external_t select * from db.other_table;
3. 优缺点 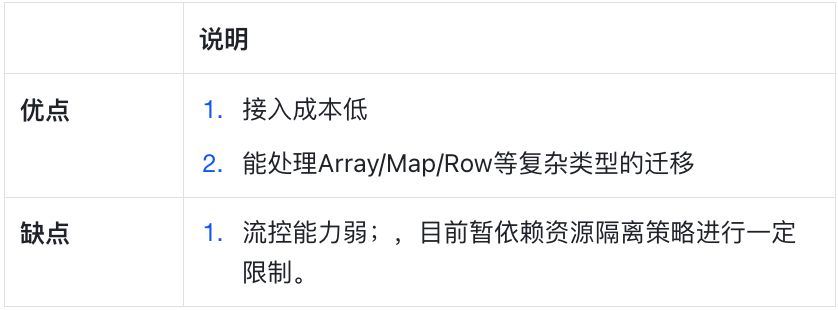 方案二 Flink SQL 1. 接入实时计算平台 本方案基于我司自研的实时计算平台(Flink任务开发调度平台)实现,需要业务方先接入平台,拥有专属项目空间和计算资源,这里不再赘述。 2. 新建Flink SQL任务 同步任务SQL即为Flink SQL,分为定义数据来源表、定义数据输出表、定义同步ETL SQL三部分。
方案二 Flink SQL 1. 接入实时计算平台 本方案基于我司自研的实时计算平台(Flink任务开发调度平台)实现,需要业务方先接入平台,拥有专属项目空间和计算资源,这里不再赘述。 2. 新建Flink SQL任务 同步任务SQL即为Flink SQL,分为定义数据来源表、定义数据输出表、定义同步ETL SQL三部分。
- 定义数据来源表
语法上遵守Flink SQL规范,更多参数设置可参见官方文档使用Flink Connector读取数据-使用 Flink SQL读取数据。 注意事项:
-
StarRocks与Flink SQL的数据类型映射;
-
Flink scan参数设置,尤其是超时(time-out)类字段的设置,建议往大了设置;
-
考虑到数据迁移的源端和目标端的库、表均同名,在定义时需要对源表和输出表的表名做区分,以免混淆错乱。比如源表命名为{table名}_source,输出表命名为{table名}_sink 。
示例: * * * * * * * * * * * * * * * * * * * * * * *
CREATE TABLE rule_script_etl_source ( `timestamp` TIMESTAMP, `identity_id` STRING, `app` STRING, `cost` BIGINT, `name` STRING, `error` STRING, `script` STRING, `rule_id` STRING) WITH ( 'connector'='du-starrocks-1.27', --具体值以官方组件或自研组件定义为准 'jdbc-url'='jdbc:mysql://1.1.1.1:9030?useSSL=false&rewriteBatchedStatements=true', 'scan-url'='1.1.1.1:8030', "user" = "${user}", "password" = "${passwd}", 'database-name'='test_db', 'table-name'='rule_script_etl', 'scan.max-retries'='3', 'scan.connect.timeout-ms'='600000', 'scan.params.keep-alive-min'='1440', 'scan.params.query-timeout-s'='86400', 'scan.params.mem-limit-byte'='1073741824');
- 定义数据输出表
注意事项:
-
StarRocks与Flink SQL的数据类型映射;
-
Flink sink参数设置,尤其是超时(time-out)类字段的设置,建议往大了设置;
-
尽量进行攒批,减小对StarRocks的导入压力;
-
考虑到数据迁移的源端和目标端的库、表均同名,在定义时需要对源表和输出表的表名做区分,以免混淆错乱。比如源表命名为{table名}_source,输出表命名为{table名}_sink ;
-
如果输出表是主键模型,表定义中字段列表后需要加上PRIMARY KEY ({primary_key}) NOT ENFORCED。
示例: * * * * * * * * * * * * * * * * * * * * * * * * * *
CREATE TABLE rule_script_etl_sink ( `timestamp` TIMESTAMP, `identity_id` STRING, `app` STRING, `rule_id` STRING, `uid` BIGINT, `cost` BIGINT, `name` STRING, `error` BIGINT, `script` STRING, `sink_time` TIMESTAMP, PRIMARY KEY (`identity_id`) NOT ENFORCED # 仅适用主键模型) WITH ( 'connector'='du-starrocks-1.27', 'jdbc-url'='jdbc:mysql://1.1.1.2:9030?useSSL=false&rewriteBatchedStatements=true', 'load-url'='1.1.1.2:8030', "user" = "${user}", "password" = "${passwd}", 'database-name'='test_db', 'table-name'='rule_script_etl', 'sink.buffer-flush.max-rows'='400000', 'sink.buffer-flush.max-bytes'='94371840', 'sink.buffer-flush.interval-ms'='30000', 'sink.connect.timeout-ms'='60000', 'sink.wait-for-continue.timeout-ms'='60000');
- 定义同步ETL
一般为insert select语句;可以根据自身需求,添加一些ETL逻辑。 注意事项:
-
有映射关系的非同名字段,添加as,提升可阅读性;
-
前后字段类型不一样的,需要使用case as进行显式类型转换;
-
如果是仅输出表包含的字段,也需要在select子句中显式指出,并使用case null as {dataType}的形式进行类型转换;
-
部分String/VARCHAR(n)类型字段中,可能存在StarRocks Flink Connector使用的默认列分隔符(参数sink.properties.column_separator,默认\t)、行分隔符(参数sink.properties.row_delimiter,默认\n),导致导入是报"errorLog:Error:Value count does not match column count. Expect xx, but got xx. Row:xxx"错误,需要替换为自定义的分隔符;
-
select子句尽量添加filter信息,一般是分区字段,以便Flink根据同步任务设置的并行度,拆分任务,生成合适的执行计划。
示例: * * * * * * * * * * * * * *
insert into rule_script_etl_sinkselect `timestamp`, `identity_id`, `app`, `rule_id`, cast(null as BIGINT) `uid`, `cost`, `name`, cast(`error` as BIGINT) `error`, `script`, `timestamp` as `sink_time`from rule_script_etl_sourcewhere `timestamp` >='2023-08-20 00:00:00' and `timestamp` < '2023-09-20 00:00:00';
完整示例: * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
CREATE TABLE rule_script_etl_source ( `timestamp` TIMESTAMP, `identity_id` STRING, `app` STRING, `cost` BIGINT, `name` STRING, `error` STRING, `script` STRING, `rule_id` STRING) WITH ( 'connector'='du-starrocks-1.27', 'jdbc-url'='jdbc:mysql://1.1.1.1:9030?useSSL=false&rewriteBatchedStatements=true', 'scan-url'='1.1.1.1:8030', "user" = "${user}", "password" = "${passwd}", 'database-name'='test_db', 'table-name'='rule_script_etl', 'scan.max-retries'='3', 'scan.connect.timeout-ms'='600000', 'scan.params.keep-alive-min'='1440', 'scan.params.query-timeout-s'='86400', 'scan.params.mem-limit-byte'='1073741824');
CREATE TABLE rule_script_etl_sink ( `timestamp` TIMESTAMP, `identity_id` STRING, `app` STRING, `rule_id` STRING, `uid` BIGINT, `cost` BIGINT, `name` STRING, `error` BIGINT, `script` STRING, `sink_time` TIMESTAMP, PRIMARY KEY (`identity_id`) NOT ENFORCED # 仅适用主键模型) WITH ( 'connector'='du-starrocks-1.27', 'jdbc-url'='jdbc:mysql://1.1.1.2:9030?useSSL=false&rewriteBatchedStatements=true', 'load-url'='1.1.1.2:8030', "user" = "${user}", "password" = "${passwd}", 'database-name'='test_db', 'table-name'='rule_script_etl', 'sink.buffer-flush.max-rows'='400000', 'sink.buffer-flush.max-bytes'='94371840', 'sink.buffer-flush.interval-ms'='30000', 'sink.connect.timeout-ms'='60000', 'sink.wait-for-continue.timeout-ms'='60000', 'sink.properties.column_separator'='#=#', -- 自定义列分隔符 'sink.properties.row_delimiter'='@=@' -- 自定义行分隔符);
insert into rule_script_etl_sinkselect `timestamp`, `identity_id`, `app`, `rule_id`, cast(null as BIGINT) `uid`, -- sinl表才有的字段 `cost`, `name`, cast(`error` as BIGINT) `error`, `script`, `timestamp` as `sink_time`from rule_script_etl_sourcewhere `timestamp` >='2023-08-20 00:00:00' and `timestamp` < '2023-09-20 00:00:00';
3. 调度任务 在开始调度前,还需要为任务的设置合适的并行度。通常SlotNum/TM设置为1,Parallelism设置为3,以长耗时换取导入任务的运行稳定性。 为避免任务失败带来的重跑工作量,单表每次任务可以迁移部分分区,多次执行。 4. 优缺点 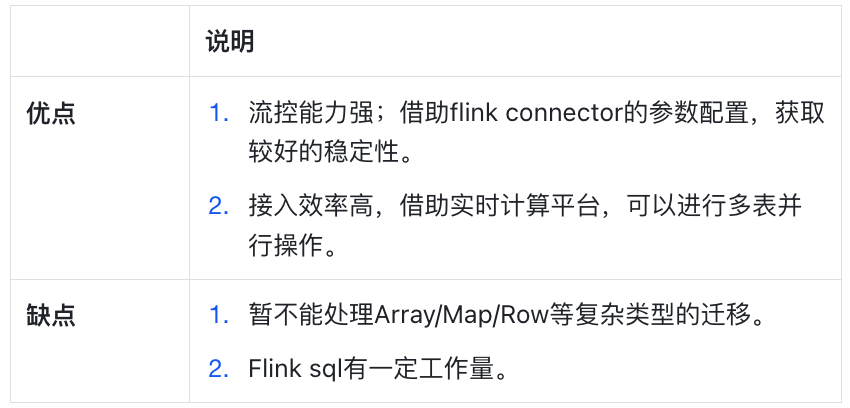 方案验证&验收 验证 可以选取不同大小的表若干,组成有梯度的待同步数据量,使用上述任一种方案,执行同步操作,并观察同步时间内集群的负载。 以集群各水位不超过80%、无业务报错为准,尝试验证集群可承载的最大同步速率,及时校正上面的数据同步规划。 验收 1. 集群负载 以集群各水位不超过80%、无业务报错为准。可根据集群水位情况,酌情增加或减少同步任务的并发。 2. 数据diff校验
方案验证&验收 验证 可以选取不同大小的表若干,组成有梯度的待同步数据量,使用上述任一种方案,执行同步操作,并观察同步时间内集群的负载。 以集群各水位不超过80%、无业务报错为准,尝试验证集群可承载的最大同步速率,及时校正上面的数据同步规划。 验收 1. 集群负载 以集群各水位不超过80%、无业务报错为准。可根据集群水位情况,酌情增加或减少同步任务的并发。 2. 数据diff校验
- 数据行数校验
针对迁移前后数据模型未发生改变的表,一定范围内(通常是单分区级别)的数据量需要保持相等; 针对迁移前后数据模型发生改变的表,需要case by base分析。 如下: 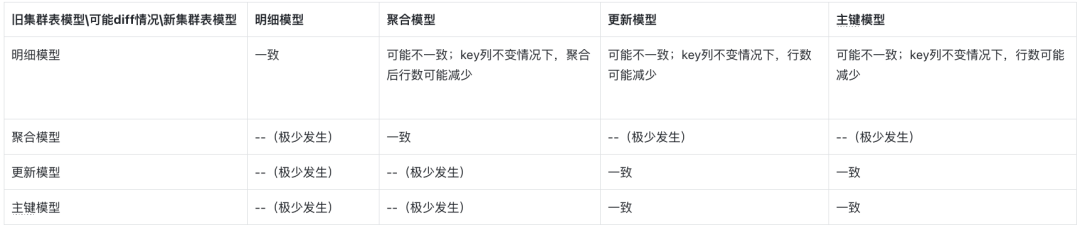
-
数据质量校验
-
针对维度表,可参考分区及或表级行数校验结果;
-
针对事实表,可以在分区级别做指标列的SUM/MAX/MIN/AVG值校验;
-
研发也可以结合业务自定义更多的校验方式。
-
三 方案成果 基于本方案,有效地解决了原地升级异常再回滚的方案带来的不稳定风险,完成了多个集群从低版本直升2.5.13的目标,累计迁移数据逾10T,迁移流量摸高至2Gb/s(10+个节点)。 结合原地升级方式,共同构成了较完善的升级方案,尽量减少升级带给业务的闪断等影响的同时,以较高效率完成升级。 四 方案展望 方案的不足 对比云商和自建DTS平台的数据迁移功能,本方案在流程化、产品化上的建设还有较大进步空间,诸如在迁移任务的量级分析、任务拆分、持续性调度、容错等步骤都可以做更多的自动化建设。 因StarRocks 2.5.13尚未支持CDC功能,当前的迁移方案暂只能提供离线同步的能力,在跨集群升级过程中,为保障数据的一致性,仍需要花费较多的精力,诸如协调新旧集群的双写、切流、补数等。 未来规划 方案中一些功能点,可以封装成原子功能,供更多场景使用。封装随着新版本StarRocks稳定性逐渐增强,组件自身bug影响稳定向的概率已经非常低了,跨集群升级的场景需求也越来越少。但方案中的原子能力,诸如库表特征分析、跨集群的shcema同步、表重建等等,仍有继续打磨的空间,可以在日常运维中提供帮助。 数据迁移的实时CDC能力也是一项亟待补齐的能力,集成离线和实时迁移功能,将助力实现无感升级。 探索跨集群迁移流程将探索更多的适用场景,诸如基于资源利用率或稳定性的集群拆分、合并等场景。
引用: https://docs.starrocks.io/zh/docs/2.5/loading/Flink-connector-starrocks/#%E5%AF%BC%E5%85%A5%E8%87%B3-bitmap-%E5%88%97 https://docs.starrocks.io/zh/docs/2.5/loading/Flink-connector-starrocks/#%E5%AF%BC%E5%85%A5%E8%87%B3-hll-%E5%88%97 https://docs.starrocks.io/zh/docs/2.5/unloading/Flink_connector/ 往期回顾