https://fish.audio/zh-CN/
Hi,这里是Aitrainee,欢迎阅读本期新文章。
今天说说最新开源TTS项目Fish Speech一些功能和使用吧:
Fish Speech是一款创新的文本转语音(TTS)工具,它提供了极高的自定义性和灵活性,以满足用户的个性化需求。该工具采用了为处理大规模数据而设计的Flash-Attn算法,该算法以其高效性、准确性和稳定性著称,显著提升了TTS技术的性能。
**例子2:**10年之后,90%的软件开发人员将拿不到他们从前的薪资。AI当道,是时候从「极客」开发者转型成为「六边形战士」------独立制作者了,越快越好!
**例子3:**从受雇于人到「超级个体」可以预见的是,伴随着AI的发展,人类社会已经走过了体力经济时代,正在经历思维经济时代,并已经显露出情感经济的特征。在情感经济时代,随着机器被训练出「思考」能力,过去需要人类智能的许多任务现在都通过AI实现了自动化。
使用Fish Speech 当你想要克隆音色时:你提供音频的时候,同时要提供这段音频的文字,你提供的音频可以是你自己的声音,也可以是你喜欢的角色的声音。然后你输入任何的文字,它就可以把你的文字转换成这种音色的音频。
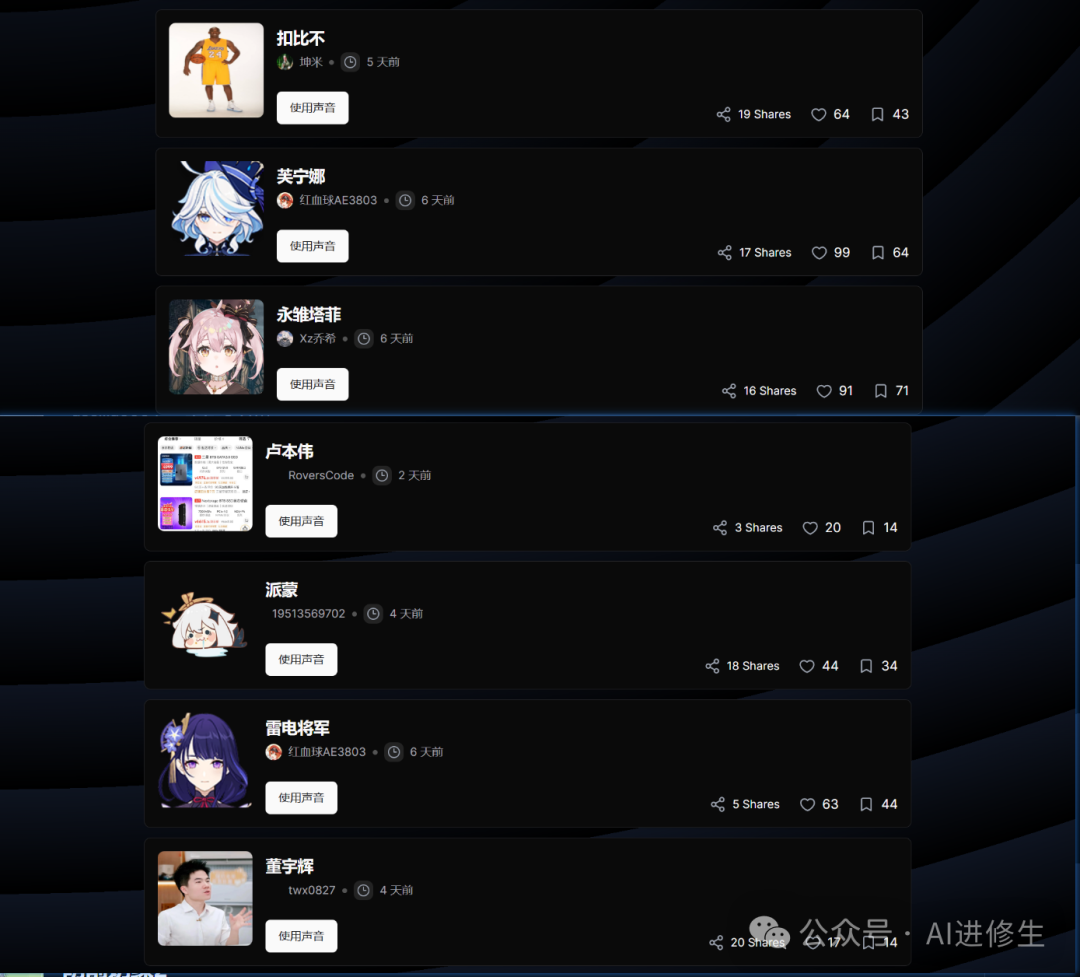
▲ 已经可使用的角色音色广场
官网提供了许多例子
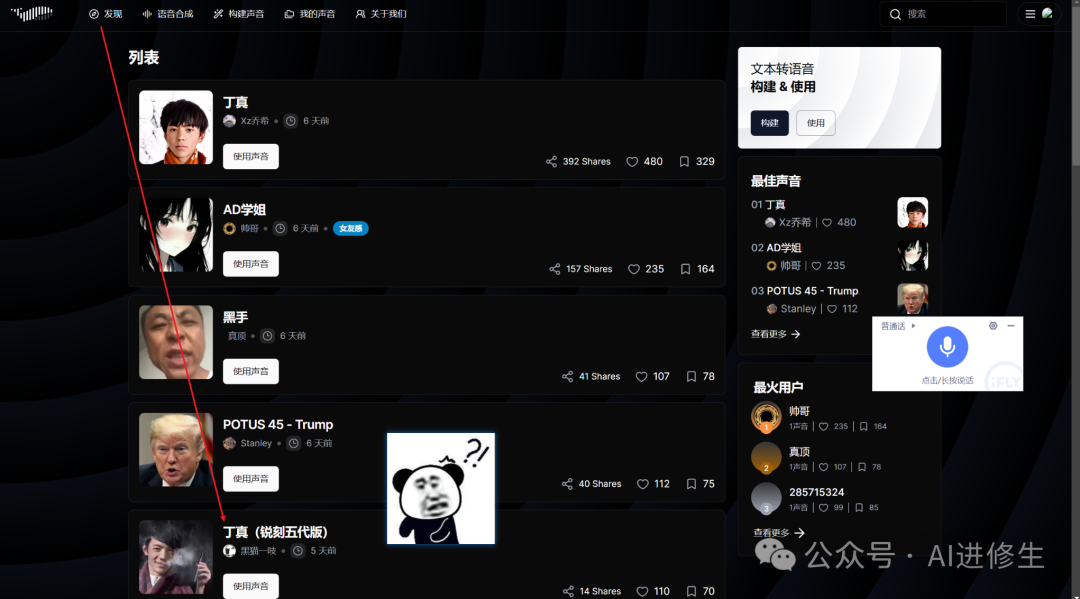
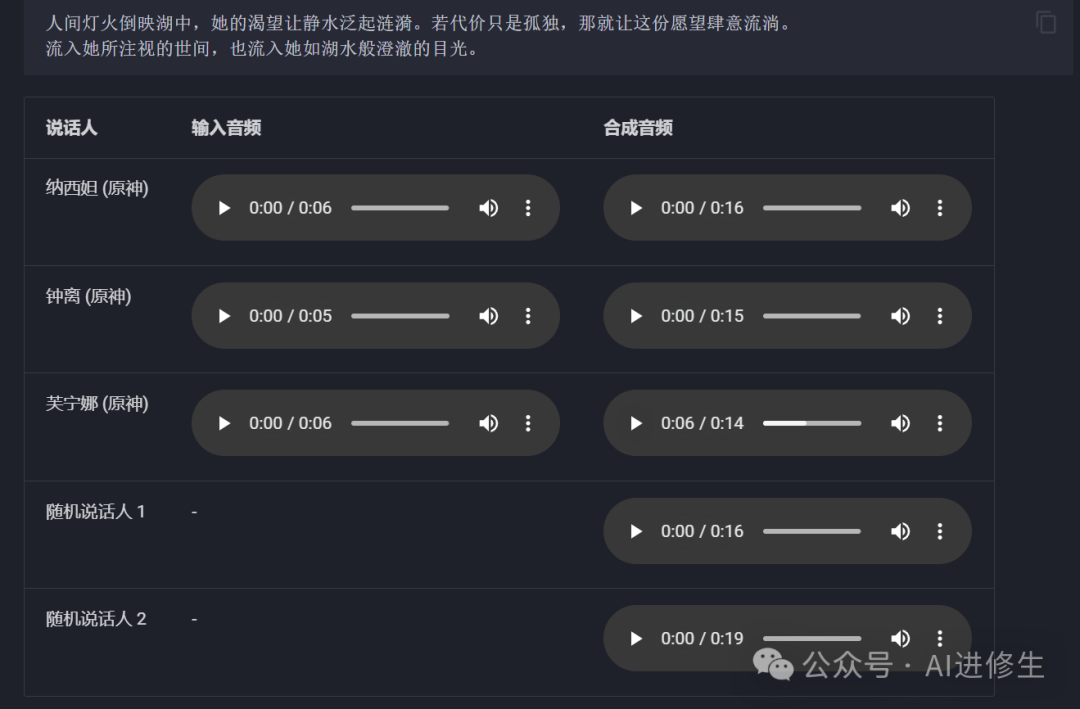 下面具体来说说官网有哪些功能(可直接上手): 在官网首页发现这里可以直接选择你喜欢角色的音色或者点击右上方的搜索,类型还是挺多的,我想要搜索的几个基本都能搜到比如:
下面具体来说说官网有哪些功能(可直接上手): 在官网首页发现这里可以直接选择你喜欢角色的音色或者点击右上方的搜索,类型还是挺多的,我想要搜索的几个基本都能搜到比如:
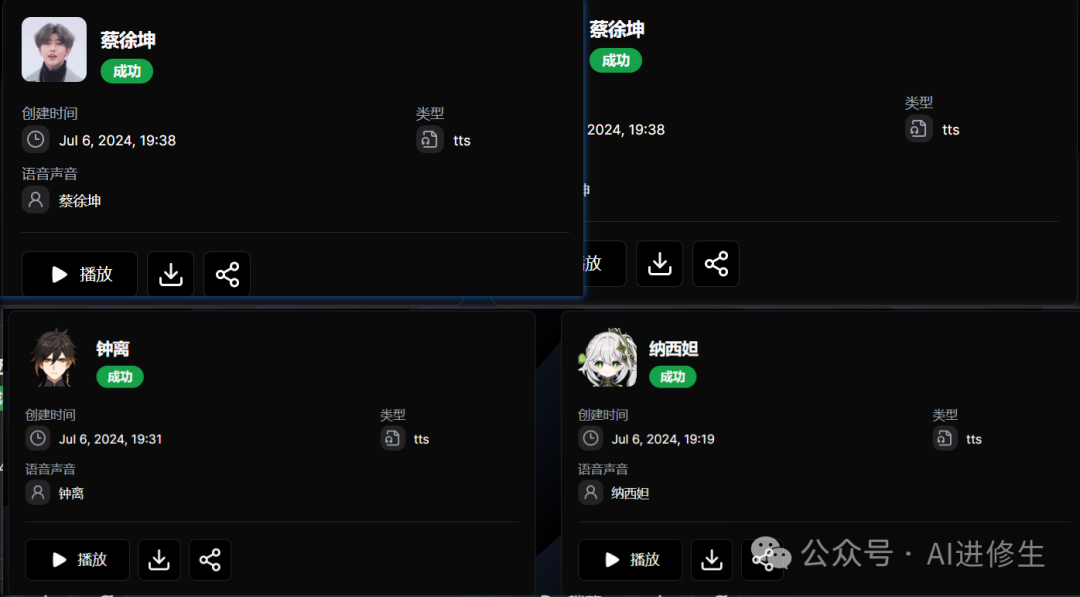

然后这个旁边语音合成就是选择刚才那些市场上已经有的音色,填入你想转换的文本:
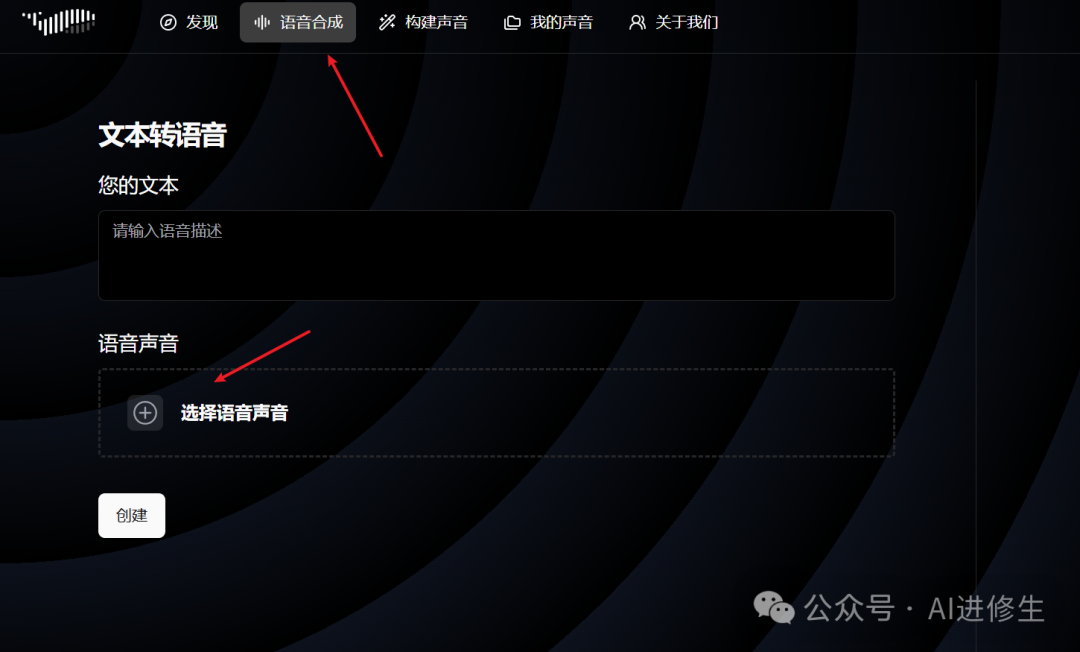
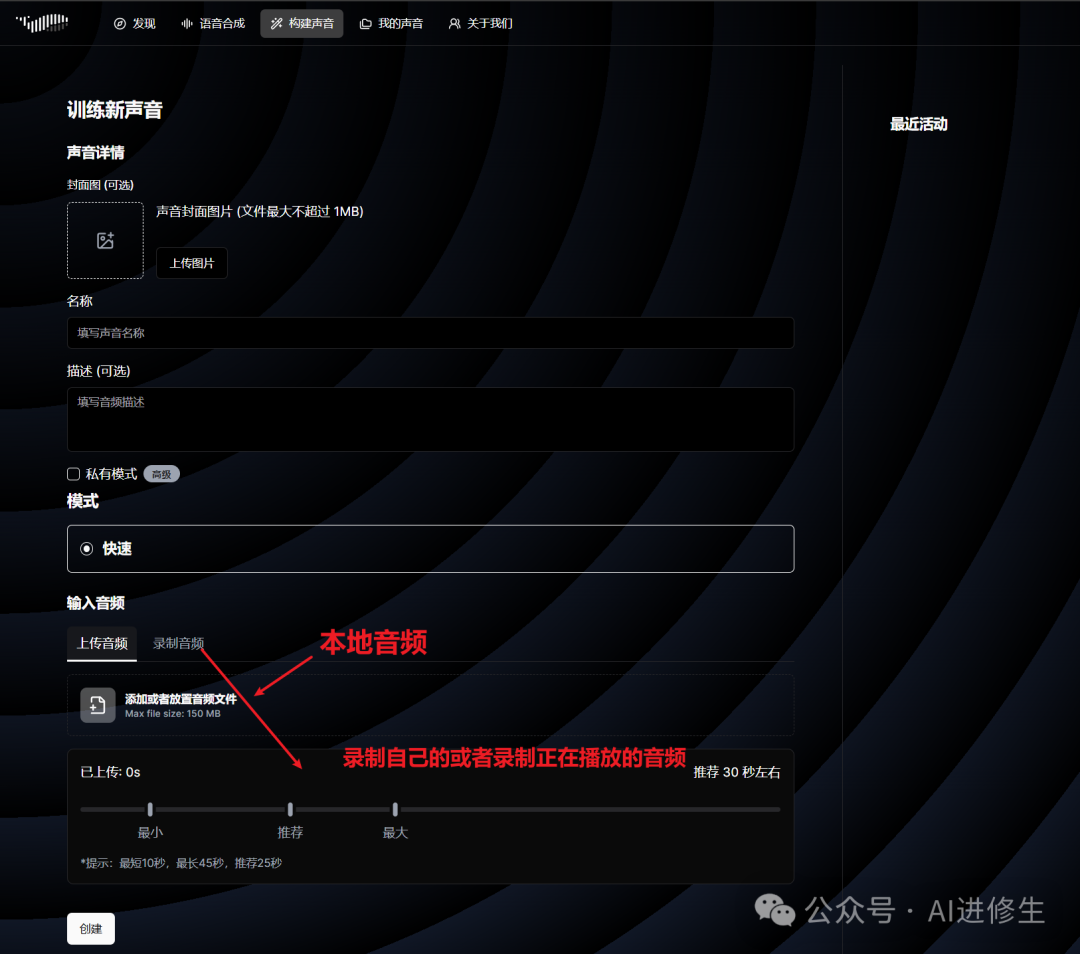
旁边这个构建声音就是制作你自己的声音,或者你喜欢角色的声音。
除此以外,如果你选择代码的方式:
三种推理方式,对于第1种命令行推理来说,简单提一提,你需要两个东西:一段音频、这段音频的文字(可以使用语音转文字工具(剪映、whisper等等),或者你知道他的文字);
第1步是把音频转为一个 fake.npy 文件,切记;剩下两步请看下面的,除此以外,你如果觉得直接推理不符合你的期望,作者也提供了微调教程(文末文档):
推理支持命令行, http api, 以及 webui 三种方式.
!!! note 总的来说, 推理分为几个部分:
1. 给定一段 ~10 秒的语音, 将它用 VQGAN 编码.
2. 将编码后的语义 token 和对应文本输入语言模型作为例子.
3. 给定一段新文本, 让模型生成对应的语义 token.
4. 将生成的语义 token 输入 VQGAN 解码, 生成对应的语音.
命令行推理
从我们的 huggingface 仓库下载所需的 vqgan 和 llama 模型。
huggingface-cli download fishaudio/fish-speech-1.2 --local-dir checkpoints/fish-speech-1.2
对于中国大陆用户,可使用 mirror 下载。
HF_ENDPOINT=https://hf-mirror.com huggingface-cli download fishaudio/fish-speech-1.2 --local-dir checkpoints/fish-speech-1.2
1. 从语音生成 prompt:
!!! note 如果你打算让模型随机选择音色, 你可以跳过这一步.
python tools/vqgan/inference.py \
-i "paimon.wav" \
--checkpoint-path "checkpoints/fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth"
你应该能得到一个 fake.npy 文件.
2. 从文本生成语义 token:
python tools/llama/generate.py \
--text "要转换的文本" \
--prompt-text "你的参考文本" \
--prompt-tokens "fake.npy" \
--checkpoint-path "checkpoints/fish-speech-1.2" \
--num-samples 2 \
--compile
该命令会在工作目录下创建 codes_N 文件, 其中 N 是从 0 开始的整数.
!!! note 您可能希望使用 --compile 来融合 cuda 内核以实现更快的推理 (~30 个 token/秒 -> ~500 个 token/秒).
对应的, 如果你不打算使用加速, 你可以注释掉 --compile 参数.
!!! info 对于不支持 bf16 的 GPU, 你可能需要使用 --half 参数.
3. 从语义 token 生成人声:
VQGAN 解码
python tools/vqgan/inference.py \
-i "codes_0.npy" \
--checkpoint-path "checkpoints/fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth"
HTTP API 推理
运行以下命令来启动 HTTP 服务:
python -m tools.api \
--listen 0.0.0.0:8000 \
--llama-checkpoint-path "checkpoints/fish-speech-1.2" \
--decoder-checkpoint-path "checkpoints/fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth" \
--decoder-config-name firefly_gan_vq
如果你想要加速推理,可以加上--compile参数。
# 推荐中国大陆用户运行以下命令来启动 HTTP 服务:
HF_ENDPOINT=https://hf-mirror.com python -m ...
随后, 你可以在 http://127.0.0.1:8000/ 中查看并测试 API.
下面是使用tools/post_api.py发送请求的示例。
python -m tools.post_api \
--text "要输入的文本" \
--reference_audio "参考音频路径" \
--reference_text "参考音频的文本内容"
--streaming True
上面的命令表示按照参考音频的信息,合成所需的音频并流式返回.
如果需要通过{说话人}和{情绪}随机选择参考音频,那么就根据下列步骤配置:
1. 在项目根目录创建ref_data文件夹.
2. 在ref_data文件夹内创建类似如下结构的目录.
.
├── SPEAKER1
│ ├──EMOTION1
│ │ ├── 21.15-26.44.lab
│ │ ├── 21.15-26.44.wav
│ │ ├── 27.51-29.98.lab
│ │ ├── 27.51-29.98.wav
│ │ ├── 30.1-32.71.lab
│ │ └── 30.1-32.71.flac
│ └──EMOTION2
│ ├── 30.1-32.71.lab
│ └── 30.1-32.71.mp3
└── SPEAKER2
└─── EMOTION3
├── 30.1-32.71.lab
└── 30.1-32.71.mp3
也就是ref_data里先放{说话人}文件夹, 每个说话人下再放{情绪}文件夹, 每个情绪文件夹下放任意个音频-文本对。
3. 在虚拟环境里输入
python tools/gen_ref.py
生成参考目录.
4. 调用 api.
python -m tools.post_api \
--text "要输入的文本" \
--speaker "说话人1" \
--emotion "情绪1" \
--streaming True
以上示例仅供测试.
WebUI 推理
你可以使用以下命令来启动 WebUI:
python -m tools.webui \
--llama-checkpoint-path "checkpoints/fish-speech-1.2" \
--decoder-checkpoint-path "checkpoints/fish-speech-1.2/firefly-gan-vq-fsq-4x1024-42hz-generator.pth" \
--decoder-config-name firefly_gan_vq
!!! note 你可以使用 Gradio 环境变量, 如 GRADIO_SHARE, GRADIO_SERVER_PORT, GRADIO_SERVER_NAME 来配置 WebUI.
祝大家玩得开心!
FishSpeech 是由 fishaudio 开发的一款文本转语音(TTS)工具,具有以下显著特色:
多语言支持
FishSpeech 支持中文、英文和日语,可以满足多语言用户的需求。
逼真语音效果
生成的语音效果非常接近真人,让听众几乎无法分辨是人工还是合成语音。
语音克隆能力
用户可以提供参考语音,FishSpeech 能够快速且准确地进行语音克隆,生成的语音与参考语音非常相似。
训练数据丰富
FishSpeech 使用了大约十五万小时的三语数据进行训练,特别是在中文方面表现尤为出色。这保证了模型在处理复杂语音任务时的高质量表现。
低GPU内存需求
推理阶段仅需 4GB GPU 内存,微调阶段仅需 16GB GPU 内存,使用消费级显卡即可满足需求,大大降低了硬件门槛。
易用性强
FishSpeech 模型参数量小,但效果逼真,非常适合各类应用场景,使用者可以轻松上手。 TTS相关:
6k Star!ChatTTS:开源领域最强的文本到语音转换(TTS)模型!
23.5k Star!OpenVoice:这款AI工具能够精准模仿你的声音并说出任何语言!了解了 FishSpeech 的详细介绍后,这里是一些有用的链接,以便你深入了解和使用 FishSpeech:
-
官网介绍文档: https://speech.fish.audio/
-
GitHub 仓库: https://github.com/fishaudio/fish-speech
-
官网: https://fish.audio/zh-CN/
-
模型权重: https://hf-mirror.com/fishaudio/fish-speech-1.2