主要参考下面两篇文章,有条件的可以直接看原文章。
-
https://github.com/cnlinxi/book-text-to-speech
-
《A Survey on Neural Speech Synthesis》
1、基础概念
本节介绍一些语音相关的基本概念。
短时能量(时域)
 短时能量
短时能量
声强和声强级(时域)
 声强
声强
响度
 响度
响度
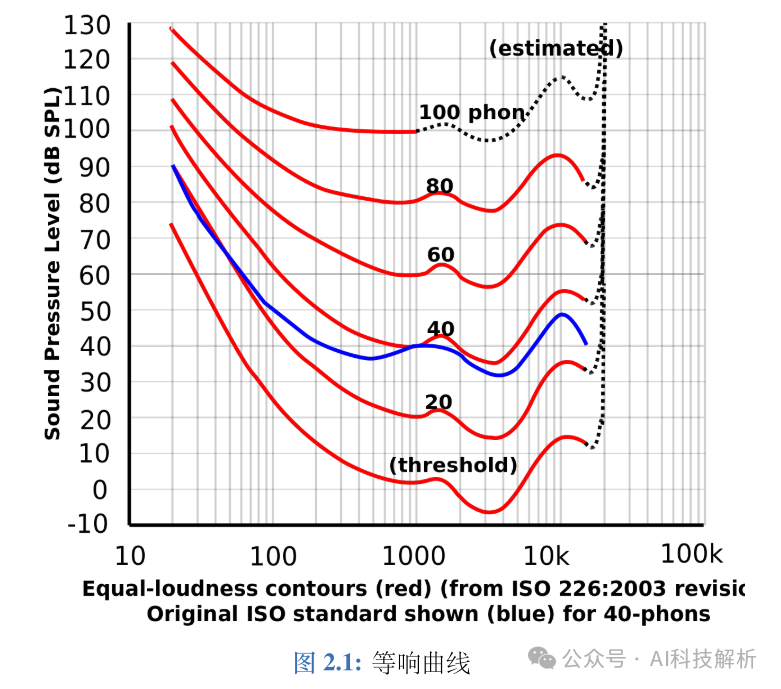 等响曲线
等响曲线
过零率(频域)

过零率
共振峰(频域)

共振峰
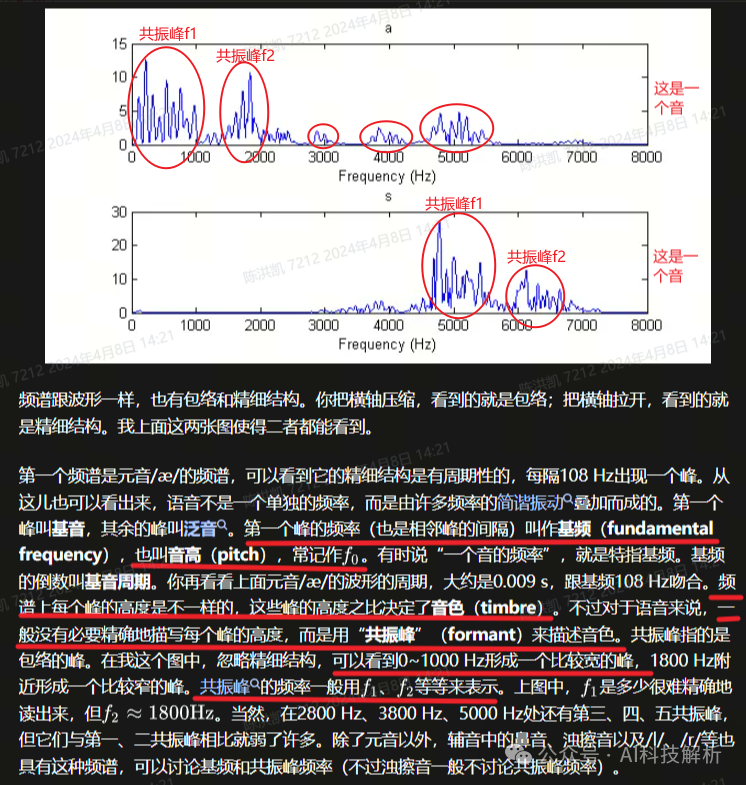 共振峰
共振峰
不同元音辅音在声音频谱的表现是什么样子?
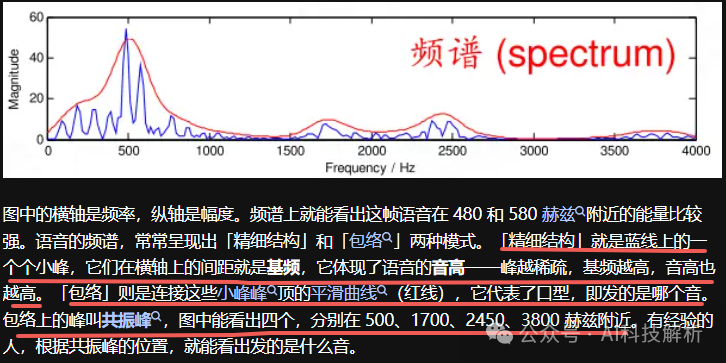 共振峰
共振峰
语音信号处理中怎么理解分帧?
基频和基音周期
基频(fundamental frequency,f0/F0)则是基音周期的倒数,对应着声带振动的频率,代表声音的音高,声带振动越快,基频越高。它是语音激励源的一个重要特征,比如可以通过基频区分性别。一般来说,成年男性基频在 100∼250Hz 左右,成年女性基频在 150∼350Hz 左右,女声的音高一般比男声稍高。 如图2.2所示,蓝色箭头指向的明亮横线对应频率就是基频,决定音高;而绿框中的明亮横线统称为谐波。谐波是基频对应的整数次频率成分,由声带发声带动空气共振形成的,对应着声音三要素的音色。谐波的位置,相邻的距离共同形成了音色特征。谐波之间距离近听起来则偏厚粗,之间距离远听起来偏清澈。在男声变女声的时候,除了基频的移动,还需要调整谐波间的包络,距离等,否则将会丢失音色信息。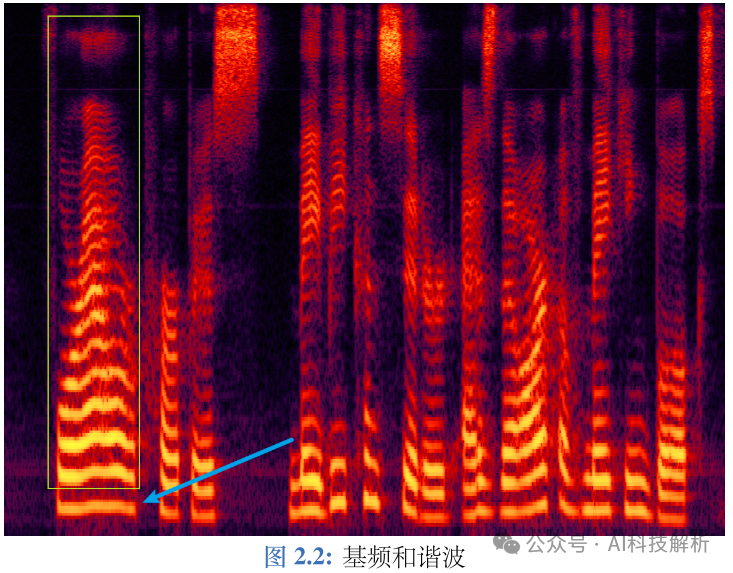
基频和谐波
人类对于基频的感知遵循对数律,因此,音高常常用基频的对数来表示。 基频是语音的重要特征,基频的提取可以分为时域法和频域法。时域法以波形为输入,基本原理是寻找波形的最小正周期;频域法则会先对信号进行傅里叶变换,得到频谱,频谱在基频的整倍数处有尖峰,频域法的基本原理就是求出这些尖峰频率的最大公约数。但是考虑到基频并非每一帧都有,因此在提取基频前后,都需要判断有无基频,称之为清浊音判断(Unvoiced/Voiced Decision,U/V Decision)。
语音的基频往往随着时间变化,在提取基频之前往往要进行分帧,逐帧提取的基频常常含有错误,其中常见的错误就是倍频错误和半频错误,也就是提取出来的基频是真实基频的两倍或者一半,因此基频提取后要进行平滑操作。
音高
音高(pitch)是由声音的基频决定的,音高和基频常常混用。可以这样认为,音高(pitch)是稀疏离散化的 基频(F0)。由规律振动产生的声音一般都会有基频,比如语音中的元音和浊辅音;也有些声音没有基频,比如 人类通过口腔挤压气流的清辅音。
MFCC和语谱图
在语音合成中,通常将频谱作为中间声学特征:首先将文本转换为频谱,再将频谱转换为波形;在语音识别中,则将频谱或者 MFCC作为中间声学特征。语音通过预加重、分帧、加窗、傅里叶变换之后,取功率谱的幅度平方,进行梅尔滤波取对数之后,就得到了梅尔频谱(或称FilterBank/FBank),如果再进行离散余弦变换,就能够获得MFCC。 语音通常是一个短时平稳信号,在进行傅里叶变换之前,一般要进行分帧,取音频的一个小片段进行短时傅里叶变换(STFT)。STFT 的结果是一个复数,包括幅度和相位信息,将该复数中的频率作为横轴,幅度作为纵轴,如图2.3所示,就组成了频谱图,将频谱图中的尖峰点连接起来,就形成了频谱包络。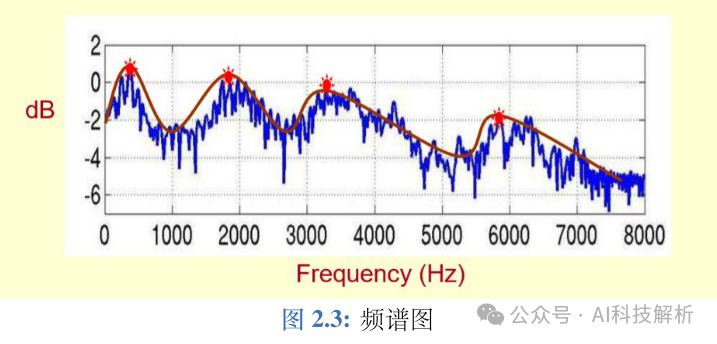 频谱图
频谱图
将每个帧对应的频谱图连接起来,以时间作为横轴,频率作为纵轴,颜色深浅表示幅度,如图2.4下面红图所示,就组成了语谱图。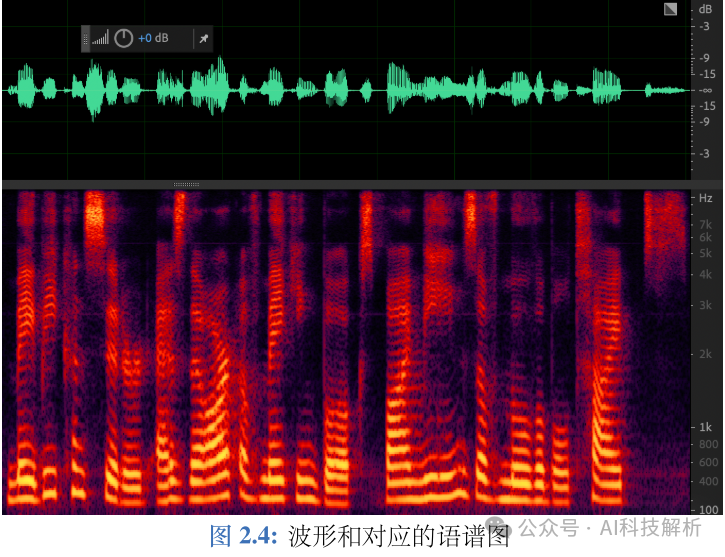 语谱图
语谱图
语言学定义
音素(phone):也称音位,是能够区别意义的最小语音单位(kit三个字母对应的音就是三个音素) 音位(Phoneme,语音单位):和音素基本大概相同,但音位和语言有关。同一个音素(比如l)在不同的单词发音可能是不一样的(比如link和cancel),这样就有了不同的音位(音位变体)。在四川话中l n不分,那么这两个音素就有相同的音位。字素(grapheme):音素对应的文本(kit中的三个字母就是三个文本/字素)。语素(morpheme):有意义的最小单位,英文中通常指单词。(kit整个单词就是一个语素,kits就是两个语素:kit表示工具,s表示多个) 音节(syllable):音节由音素组成。
https://www.youtube.com/watch?v=25r1fyoorko 音素和音位的区别与联系是什么?
音位数量的确定牵扯到对比分布和互补分布两个概念。如果A和B处于对比分布时,那么甲和乙处于同样的语言环境中时,就会引起意义的不同。比如英语中的 [p] 和 [b] 就处于对比分布,当它们处于相同的语言环境中时,比如 pin[pin] 和 bin[bin],但是两个单词的意义完全不同,因此 [p] 和 [b] 就分属两个不同的音位。而假如 A 和 B 处于互补分布时,那么甲和乙不可能出现在同样的语音环境中,例如英语中的 [p] 处于重读音节首时pig[pig],往往表现为送气的 [?ℎ],而在 [s] 后面时 spit[spit],往往表现为不送气的 [p],送气的 [?ℎ] 和不送气的[p] 不会出现在同一语音环境中,可以说,它们是同一个音位在不同语音环境中的音位变体。因此,音位处于对比分布,音位变体于互补分布。确立音位的做法便是寻找最小对比对,也就是说寻找音位时要满足:1. 在相同的语音环境;2. 单词的意思不同。最直接的做法就是找两个意义不同的的单词,并且只有在一个位置上有不同的音段,在其它位置上的音段都相同,这一对单词就是最小对比对。比如 ban[ban] 和man[man] 这对最小对比对中,除了 [b] 和 [m] 之外,其它音段都相同,正因为 [b] 和 [m],这两个单词的意义也不同。因此归纳音位的原则有:对立互补原则和语音相似原则。
国际音标(International Phonetic Alphabet,IPA)
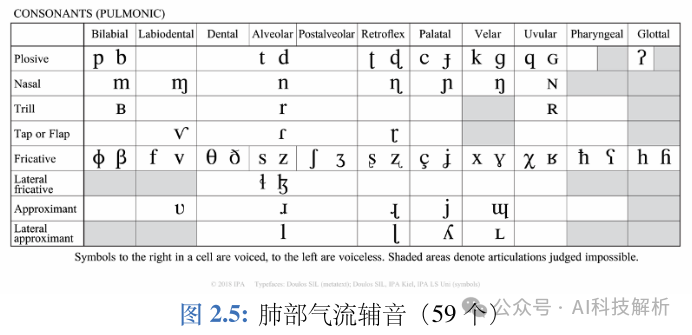
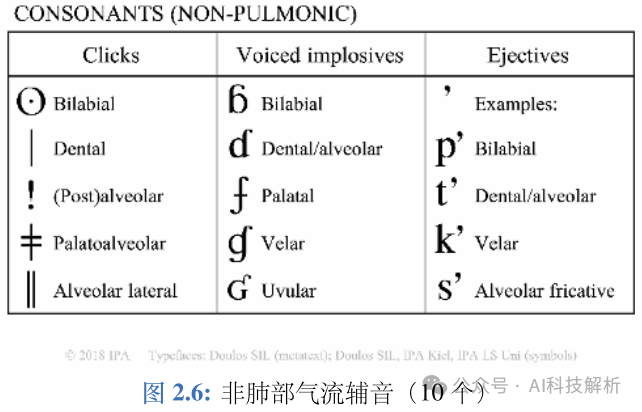
2、TTS
TTS(text-to-speech)是指输入文本生成语音的过程。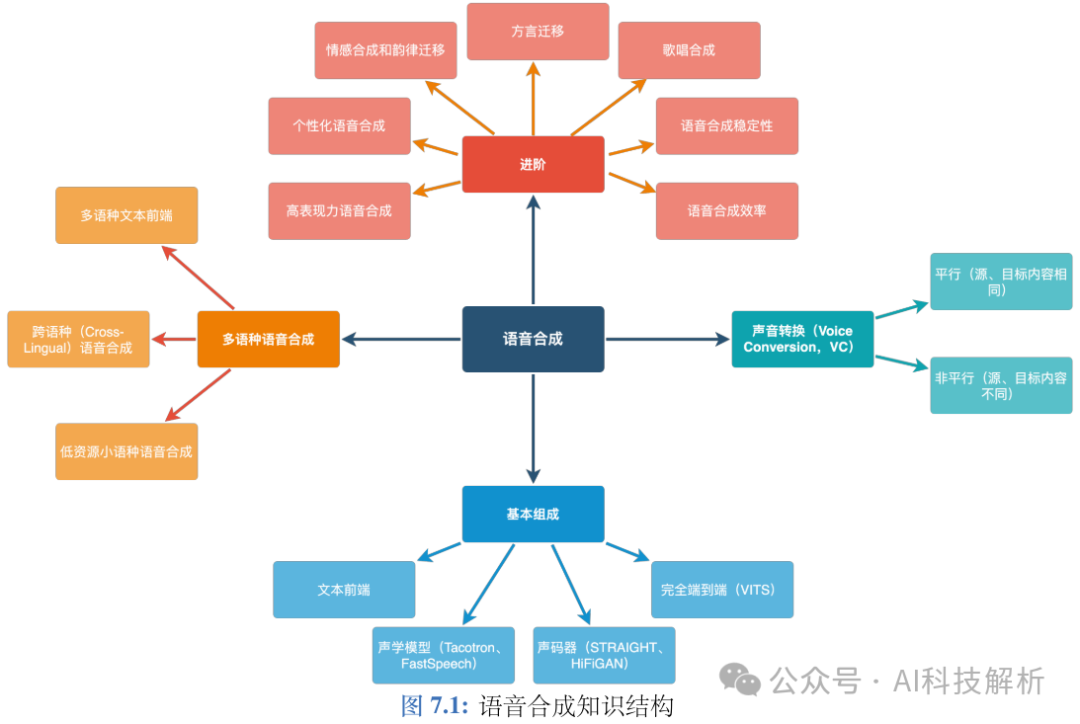
TTS过程详解
TTS主要流程为
TTS
每一部分的技术详情如下所示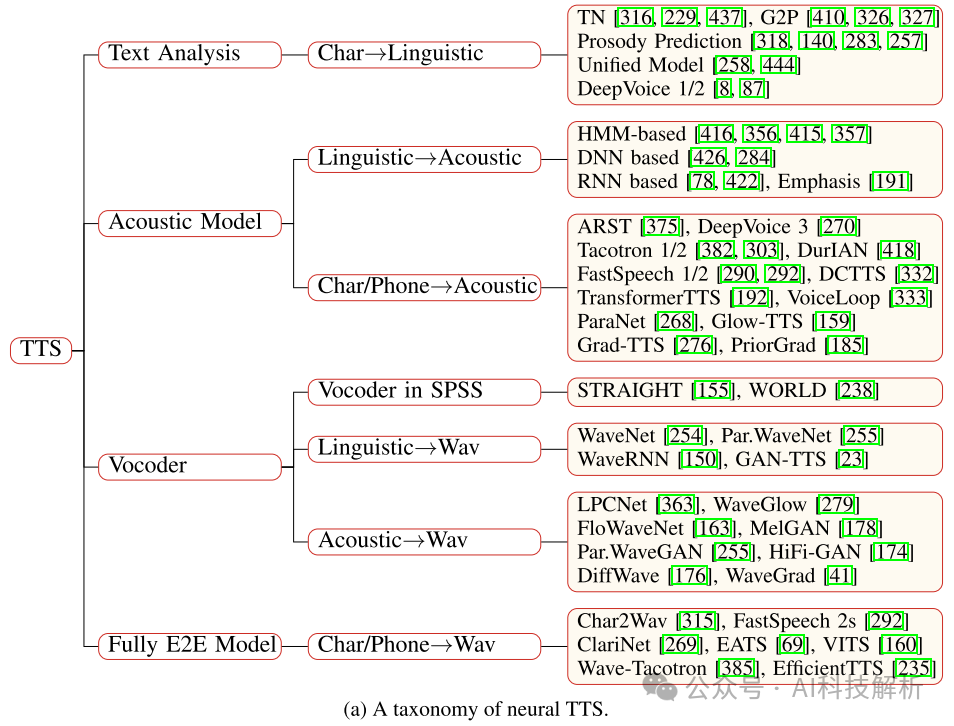 TTS
TTS
整个过程为:1)文本分析将字符转换为音素或语言特征(文本处理); 2)声学模型从语言特征或字符/音素生成声学特征(声学模型); 3)声码器从语言特征或声学特征生成波形(声码器); 4)完全端到端模型直接将字符/音素转换为波形(1-2-3结合,直接End-to-End)。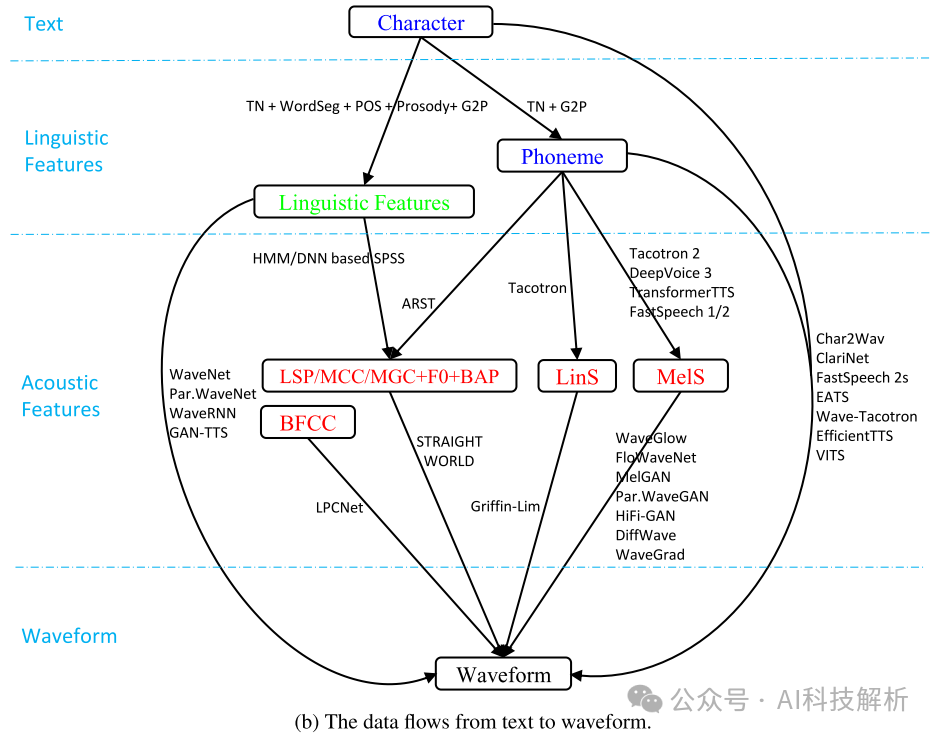
从上图可以看出,从字符到波形通常为下面几个步骤:1)字符→语言特征→声学特征→波形; 2)字符→音素→声学特征→波形; 3)字符→语言特征→波形; 4)字符→音素→声学特征→波形; 5)字符→音素→波形,或字符→波形。 TTS模型列表如下,根据类型可分为Flow、VAE(很少再用了)、GAN(有一些,但SD效果更好)、Diffusion和Seq2Seq(LLM)四大类。
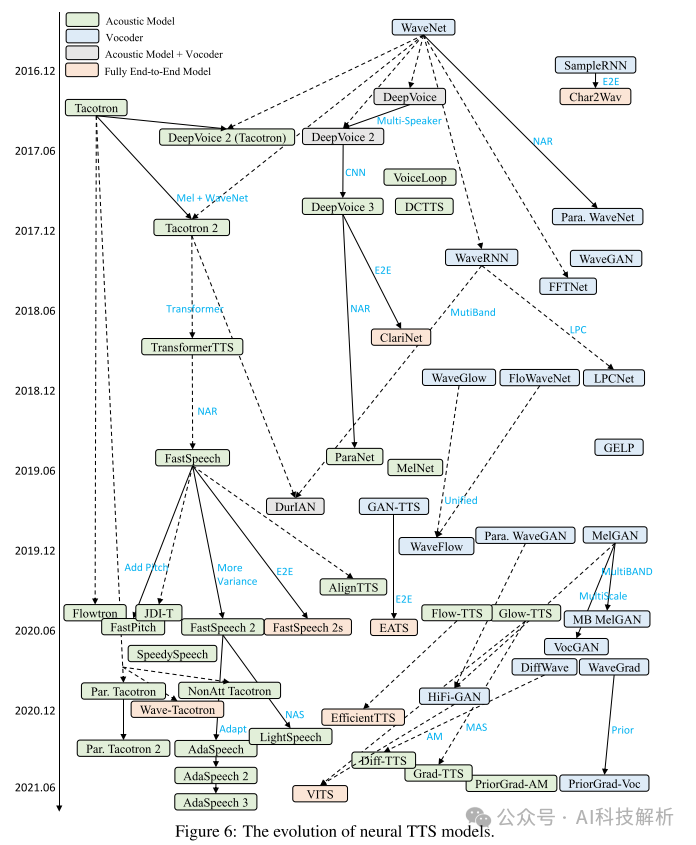
TTS模型演变
以端到端方式训练TTS模型存在很大的挑战,主要是由于文本和语音波形之间存在不同的模态,以及字符/音素序列与波形序列之间存在巨大的长度不匹配。例如,对于长度为5秒,大约20个单词的语音,音素序列的长度仅为100左右,而波形序列的长度为80k(如果采样率为16kHz)。由于内存的限制,很难将整个话语的波形点进行模型训练。如果只使用短音频片段进行端到端训练,很难捕获上下文表示 因此训练过程有如下几个阶段:
-
Stage 0。统计参数合成使用三个基本模块,其中文本分析模块将字符转换为语言特征,声学模型由语言特征生成声学特征(其中通过声码器分析获得目标声学特征),然后声码器通过参数计算从声学特征合成语音波形。
-
Stage 1。Wang等在统计参数合成中探索将文本分析和声学模型结合成端到端的声学模型,直接从音素序列中生成声学特征,然后使用SPSS中的声码器生成波形。
-
Stage 2。WaveNet首次提出直接从语言特征生成语音波形,可以看作是声学模型和声码器的结合。这种模型仍然需要一个文本分析模块来生成语言特征。
-
Stage 3。Tacotron进一步被提出用于简化语言和声学特征,它使用编码器-注意-解码器模型直接预测字符/音素的线性谱图,并使用Griffin-Lim将线性谱图转换为波形。以下作品如DeepVoice 3, Tacotron 2, TransformerTTS和FastSpeech 1/2从字符/音素预测MEL谱图,并进一步使用神经声码器,如WaveNet, WaveRNN, WaveGlow, FloWaveNet和Parallel WaveGAN来生成波形。
-
Stage 4。开发了一些完全端到端TTS模型,用于直接文本到波形的合成,如表7所示。Char2Wav利用基于rnn的编码器-注意-解码器模型从字符中生成声学特征,然后使用SampleRNN生成波形。这两个模型被联合调谐用于直接语音合成。类似地,ClariNet联合调谐自回归声学模型和非自回归声码器,用于直接波形生成。FastSpeech 2s采用全并行结构,直接从文本生成语音,大大加快了推理速度。为了减轻联合文本到波形训练的困难,它利用一个辅助的梅尔谱图解码器来帮助学习音素序列的上下文表示。一个称为EATS的并发工作也直接从字符/音素生成波形,它利用持续时间插值和软动态时间包裹损失进行端到端对齐学习。Wave-Tacotron在Tacotron上构建了基于流的解码器,直接生成波形,在流部分采用并行波形生成,在Tacotron部分仍然采用自回归生成。
TTS模型研究方向
主要有生成效率优化(AR、SD生成效率很低)、低资源场景生成(小语种)、生成的鲁棒性(GAN训练困难、AR生成不稳定)、生成质量等。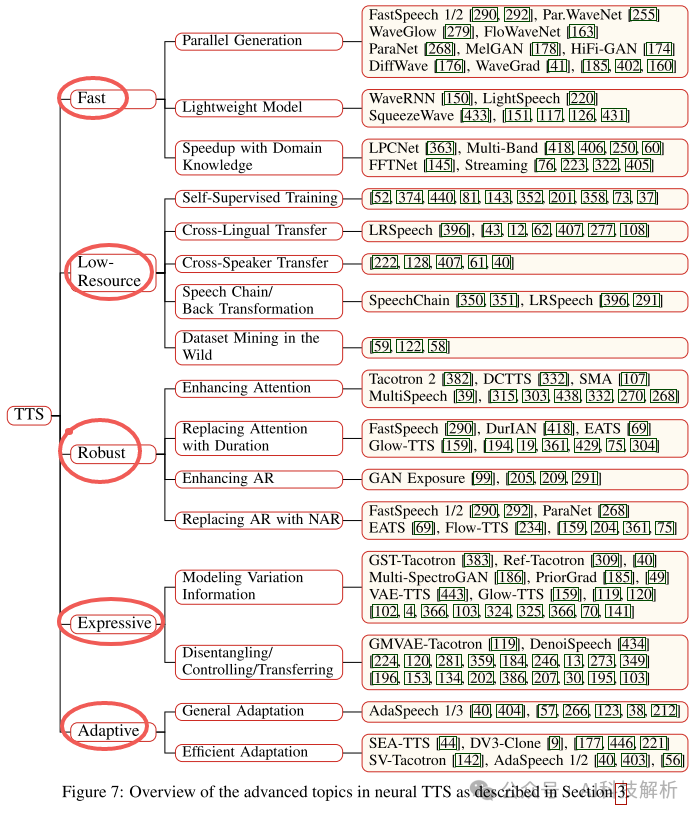
- Robust TTS
声学模型中经常出现跳词、重复和注意力崩溃等鲁棒性问题。从根本上说,这些健壮问题的原因来自两方面: 1)字符/音素与mel-谱图之间的对齐学习困难; 2)自回归生成中暴露偏差和误差传播问题。声码器不会面临严重的鲁棒性问题,因为声学特征和波形已经在帧明智地对齐。 因此,现有的鲁棒TTS研究分别解决了上述两个问题。•对于字符/音素和梅尔谱之间的对齐学习,工作可以分为两个方面:1)增强注意机制的鲁棒性,以及2)去除注意并明确预测持续时间以弥合文本和语音之间的长度不匹配。•对于自回归代中的曝光偏差和误差传播问题,工作也可以分为两个方面:1)改进自回归代以缓解曝光偏差和误差传播问题,2)去除自回归代,使用非自回归代。 我们总结了这些类别中的一些常用技术,以提高鲁棒性,如表10所示。解决这两个问题的工作可能有重叠,例如,一些工作可能会增强AR或NAR生成中的注意机制,同样,持续时间预测可以同时应用于AR和NAR生成。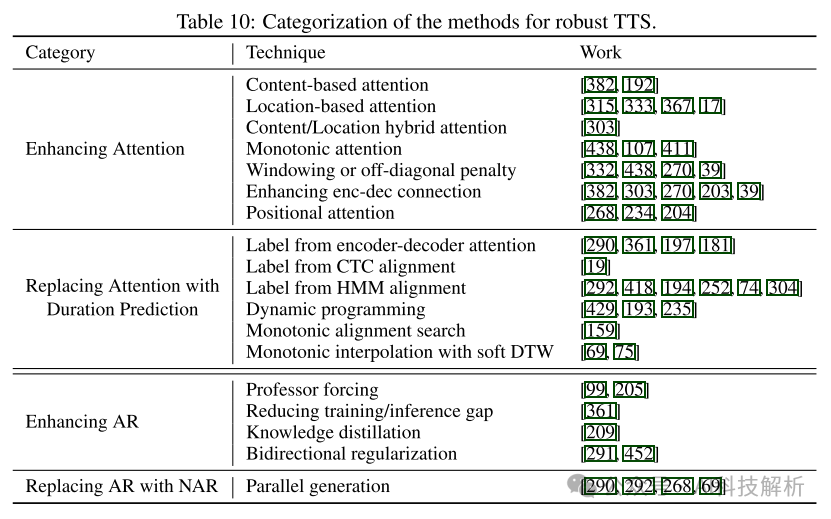
在自回归声学模型中,大量的单词跳/重复和注意崩溃问题是由编码器-解码器注意中学习到的不正确的注意对齐引起的。为了缓解这一问题,本文考虑了文本(字符/音素)序列和梅尔谱图序列之间对齐的一些特性:
-
1)局部:一个字符/音素标记可以对齐到一个或多个连续的梅尔谱图帧,而一个梅尔谱图帧只能对齐到单个字符/音素标记,这样可以避免注意力模糊和注意力崩溃;
-
2)单调性:如果字符A在字符B后面,则A对应的梅尔谱图也在B对应的梅尔谱图后面,可以避免单词重复;
-
3)完整:每个字符/音素标记必须被至少一个梅尔谱图框架覆盖,以避免跳字。

3、文本前端(文本处理)
文本前端一般遵循 文本-->规范化文本-->音素 这 3 个基本步骤,同时会从文本和规范化文本中预测韵律。音素和韵律标识统称为语言学特征(linguistic feature)。
一般来说,文本前端可分为以下五个部分:
-
文本预处理:主要是解决文本中书写错误、一些语种中同形异码等问题。
-
文本归一化:主要解决文本中的特殊符号读法,比如"2kg"转换为"两千克",另外还要处理一些语种比如波兰语、俄语中的性数格变化。
-
分词:一些语种比如中文、藏语、日语、泰语、越南语、维吾尔语、朝鲜语等并非以空格作为词边界,通常需要分词以便后续的处理,但世界上大部分语种都以空格为词边界,该步骤可省略。
-
文本转音素(G2P):将文本转换为注音,比如"中国"转化为"zhong1 guo2"。
-
韵律分析:语音中每个音素的发音时长不同,停顿也不同。将文本转换为音素之后,通常会加入一定的韵律信息,以帮助声学模型提升合成语音的自然度,加入的韵律信息可以分为音素(L0)、单词(L1)、breathbreak(L3)和句子(L4)四个韵律层级。
3.1、文本预处理
筛选文本中的一些错字等问题。
3.2、文本归一化
一个基础的归一化模块至少应覆盖以下几类规则:物理量、货币、缩略语、常用机构名或专有名词、数字(分数/百分数/科学计数法/小数点/基数词/序数词/数字串)、算术表达式、标点符号、日期(月份/星期)的各表示、时间、比分、网络用语或外来词等。比如把1.2改为一点二。
ICASSP 2020中的语音合成 《A HYBRID TEXT NORMALIZATION SYSTEM USING MULTI-HEAD SELF-ATTENTION FOR MANDARIN 》
3.3、分词
对于世界上大部分的语种来说,空格是天然的单词边界,因此分词并非一个常见任务,仅有少部分语种需要分词。
无猫之徒:中文分词算法简介
3.4、文本转音素
文本转音素(G2P/LTS)是将文本转换为注音表示的过程。最简单直白的文本转音素方法无疑是查词典。但是对于带有缩略词、外来词的文本来说,情况略微复杂,因为查询缩略词、本语种和外来词词典的优先级不同,输出的音素序列有时也会有所不同。
文本:'Motivation is a skill that we all possess but few of us ever really use. There a'
-->
音素:mˌoʊɾɪvˈeɪʃən ɪz ɐ skˈɪl ðæt wiː ˈɔːl pəzˈɛs bˌʌt fjˈuː ʌv ˌʌs ˈɛvɚ ɹˈiəli jˈuːs. ðɛɹ ˈeɪ
3.5、韵律分析
韵律分析同样是文本前端的难点之一,一个好的韵律信息可大大提升最终合成语音的自然度。
https://slyne.github.io/%E5%85%AC%E5%BC%80%E8%AF%BE/2020/10/03/TTS1/
3.6、音素编码
音素最终输入到模型中进行处理还需要转换成数字信息。对于英文来说,使用english_cleaners。
音素:mˌoʊɾɪvˈeɪʃən ɪz ɐ skˈɪl ðæt wiː ˈɔːl pəzˈɛs bˌʌt fjˈuː ʌv ˌʌs ˈɛvɚ ɹˈiəli jˈuːs. ðɛɹ ˈeɪ
->
编码:[55, 157, 57, 135, 125, 102, 64, 156, 47, 102, 131, 83, 56, 16, 102, 68, 16, 70, 16, 61, 53, 156, 102, 54, 16, 81, 72, 62, 16, 65, 51, 158, 16, 156, 76, 158, 54, 16, 58, 83, 68, 156, 86, 61, 16, 44, 157, 138, 62, 16, 48, 52, 156, 63, 158, 16, 138, 64, 16, 157, 138, 61, 16, 156, 86, 64, 85, 16, 123, 156, 51, 83, 54, 51, 16, 52, 156, 63, 158, 61, 4, 16, 81, 86, 123, 16, 156, 47, 102]
代码:https://github.com/yl4579/StyleTTS2/blob/main/text_utils.py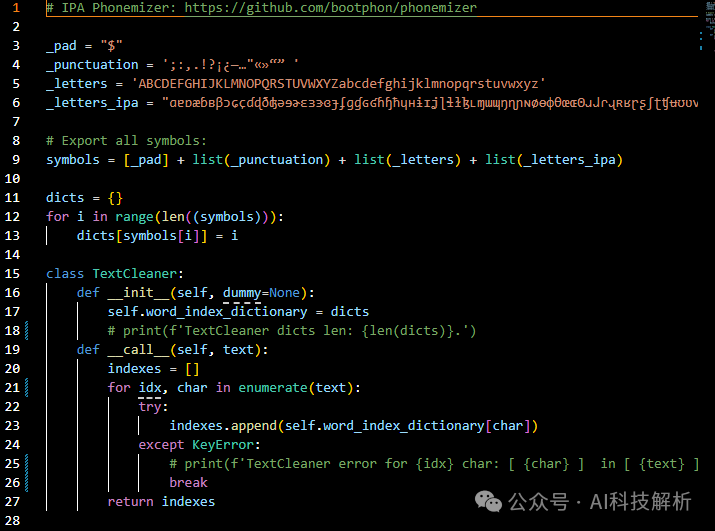 english_cleaner
english_cleaner
每种语言都要有自己的xxx_cleaner,将对应的音素转换为数字编码。
3.7、embedding编码
在LLM中有将文本直接输入到embedding层中得到数字编码的过程,有些TTS方法也进行了借鉴。这种方法虽然可以得到数字编码,但忽略了很重要的音素信息。总结就是可以用,但这么用的基本没有。
4、声学模型
声学模型就是将前面处理的语言特征转换为所需要的声学特征,得到的声学特征用于合成目标音频。
Tacotron-2
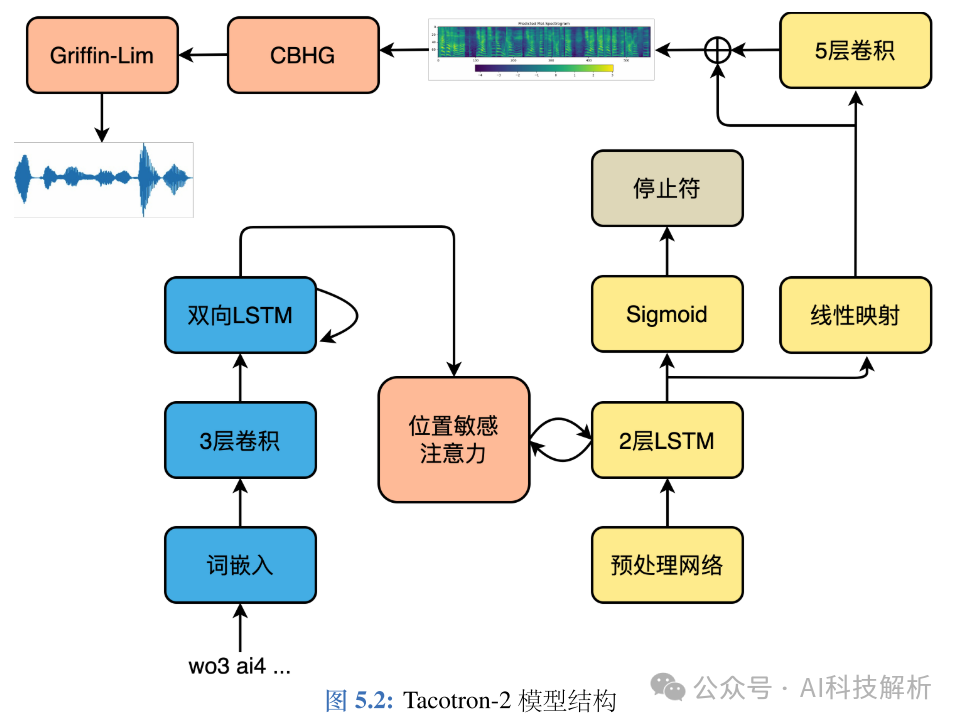
Tacotron-2
代码:https://github.com/NVIDIA/tacotron2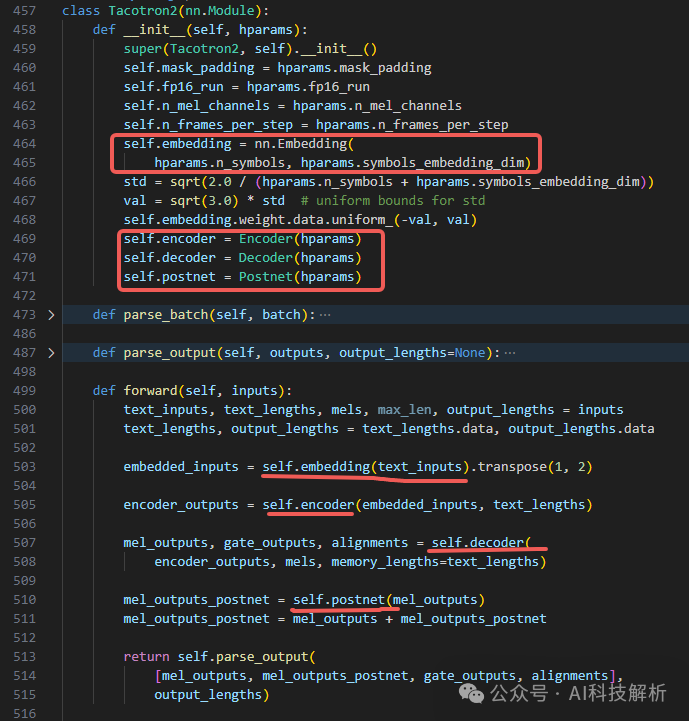
tacotron2
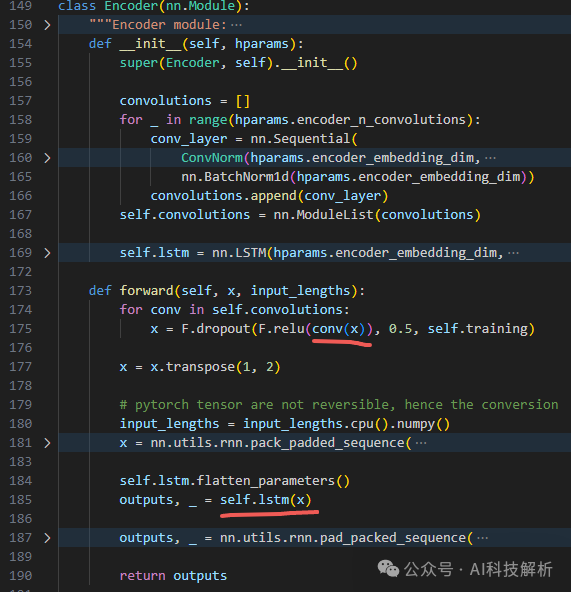
Encoder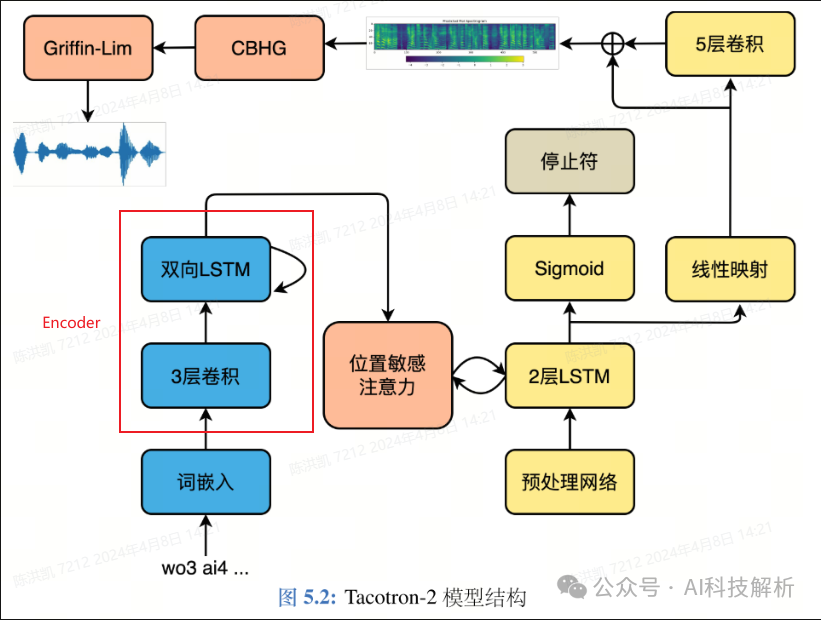
tacotron2 Encoder
Decoder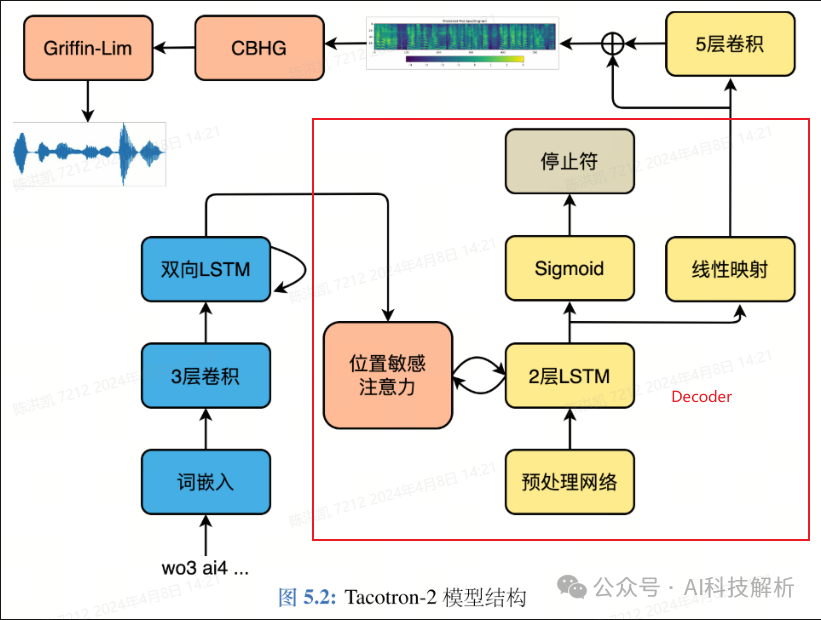
tacotron2 Decoder
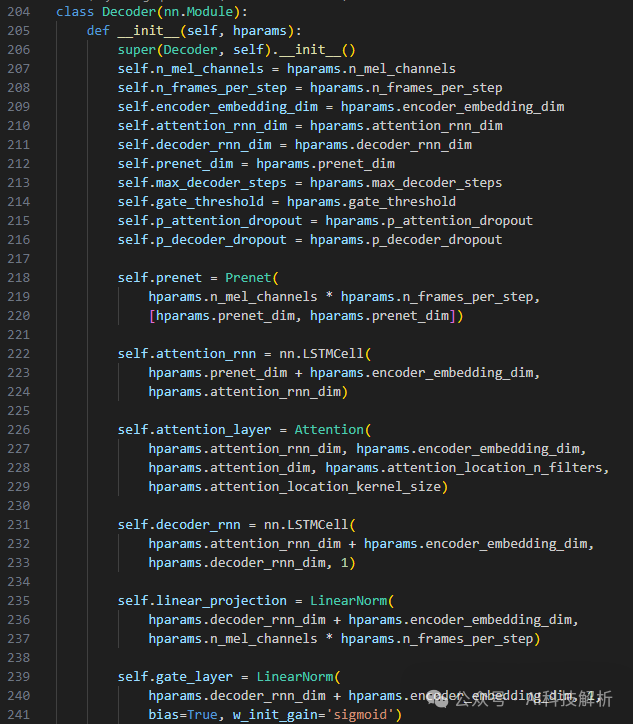
tacotron2 Decoder
Postnet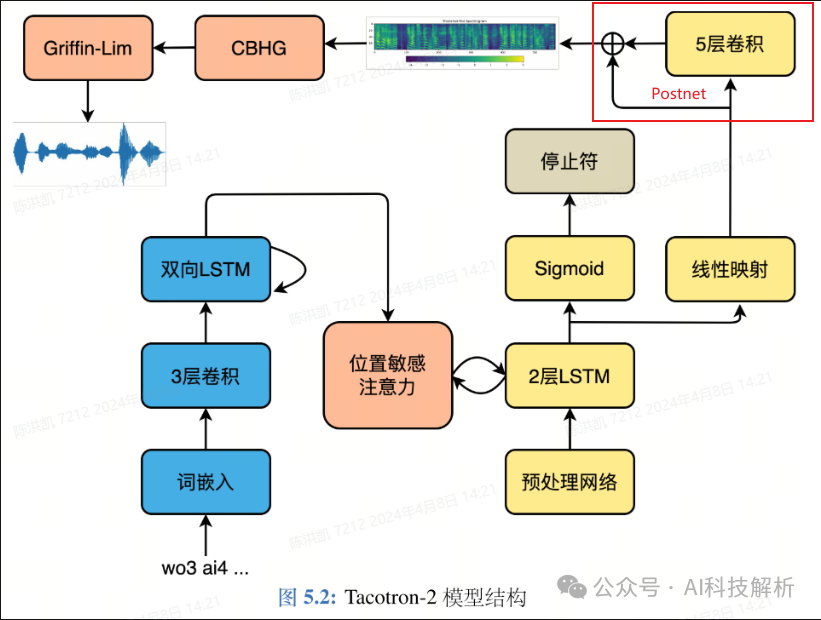 tacotron2 Postnet
tacotron2 Postnet
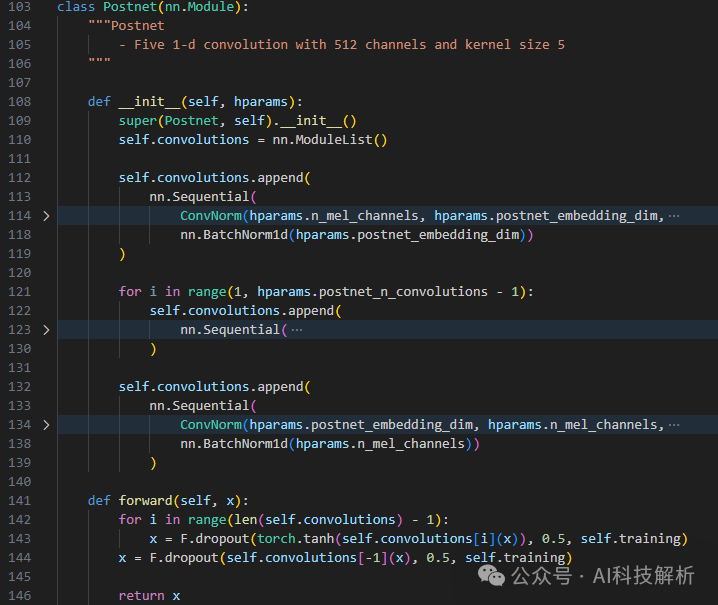 tacotron2 Postnet
tacotron2 Postnet
由postnet特征生成音频还需要专门的声码器(比如waveglow)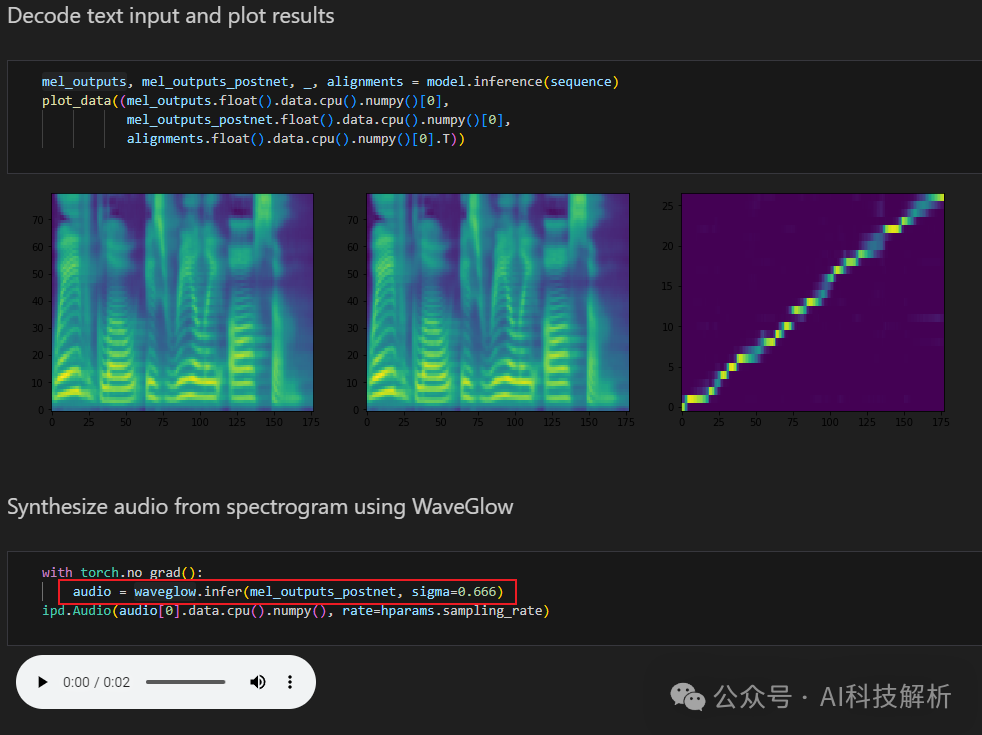
在 Tacotron-2 原始论文中,直接将梅尔频谱送入声码器WaveNet生成最终的时域波形。但是WaveNet计算复杂度过高,几乎无法实际使用,因此可以使用其它声码器,比如 Griffin-Lim、HiFiGAN等。
FastSpeech
https://github.com/ming024/FastSpeech2
论文中提到语音合成是典型的一对多问题,同样的文本可以合成无数种语音。在语音中,音素时长自不必说,直接影响发音长度和整体韵律;音调则是影响情感和韵律的另一个特征;能量则影响频谱的幅度,直接影响音频的音量。在FastSpeech2 中对这三个最重要的语音属性单独建模,从而缓解一对多带来的模型学习目标不确定的问题。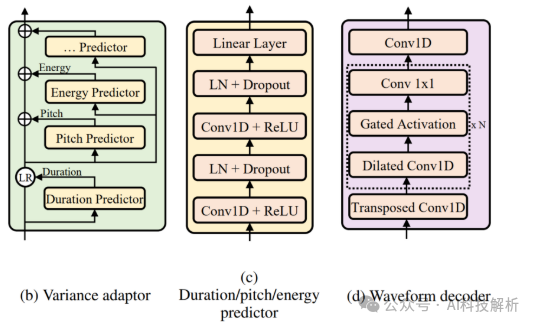 FastSpeech
FastSpeech
VITS
https://github.com/p0p4k/vits2_pytorch
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(vari-ational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。和Tacotron 和FastSpeech不同,Tacotron / FastSpeech 实际是将字符或音素映射为中间声学表征,比如梅尔频谱,然后通过声码器将梅尔频谱还原为波形,而VITS则直接将字符或音素映射为波形,不需要额外的声码器重建波形,真正的端到端语音合成模型。 VITS 通过隐变量而非之前的频谱串联语音合成中的声学模型和声码器,在隐变量上进行建模并利用随机时长预测器,提高了合成语音的多样性,输入同样的文本,能够合成不同声调和韵律的语音。VITS 合成音质较高,并且可以借鉴之前的FastSpeech,单独对音高等特征进行建模,以进一步提升合成语音的质量。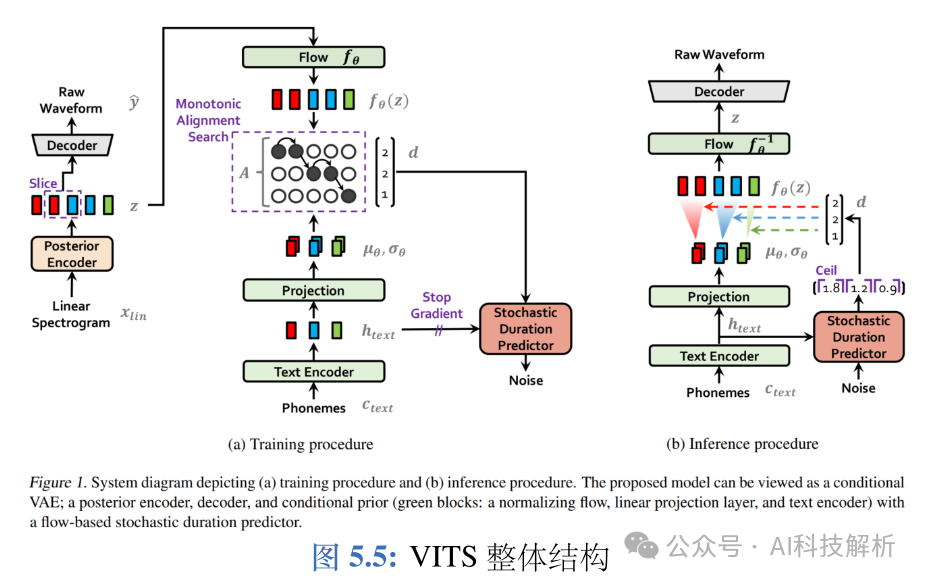
VITS
- 对齐估计
由于在训练时没有对齐的真实标签,因此在训练的每一次迭代时都需要估计对齐。 VITS 是一种由字符或音素直接映射为波形的端到端语音合成模型,该语音合成模型采用对抗训练的模式, 生成器多个模块基于标准化流。
5、声码器
声码器(Vocoder),又称语音信号分析合成系统,负责根据声学特征对声音进行分析和合成,主要用于合成人类的语音。声码器主要由以下功能:
-
分析 Analysis
-
操纵 Manipulation
-
合成 Synthesis
声码器的发展可以分为两个阶段,包括用于统计参数语音合成(Statistical Parameteric Speech Synthesis,SPSS)基于信号处理的声码器和基于神经网络的声码器。常用基于信号处理的声码器包括Griffin-Lim1,STRAIGHT2和WORLD3。早期神经声码器包括WaveNet、WaveRNN 等,近年来神经声码器发展迅速,涌现出包括 MelGAN、HiFiGAN、LPCNet、NHV等优秀的工作。 声码器模型列表如下,主要分为Flow、GAN和Diffusion三大类。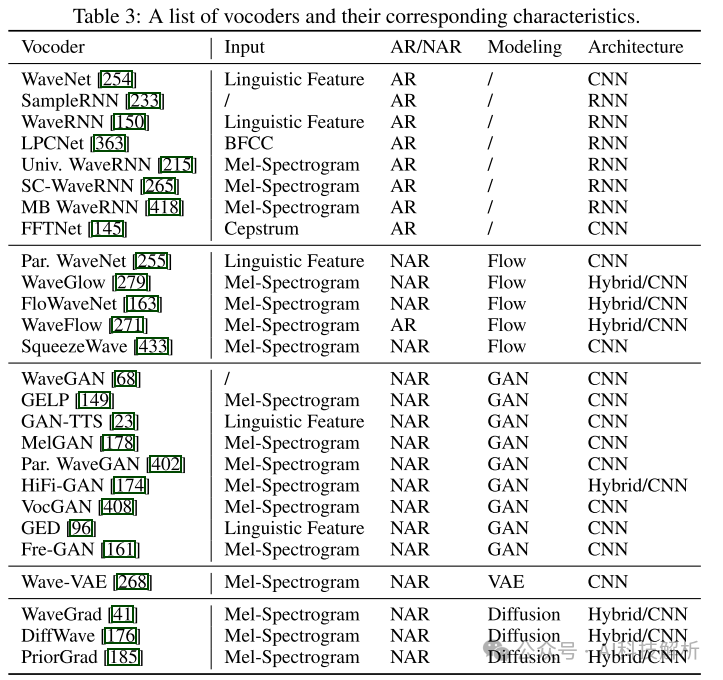
Autoregressive Vocoders
WaveNet是第一个基于神经网络的声码器,它利用扩展卷积自回归生成波形点。WaveRNN是为高效音频合成而开发的,它使用循环神经网络并利用多种设计,包括双softmax层、权值修剪和子尺度技术来减少计算量。 因为语音波形数据很长,自回归方式速度太慢。
Flow-based Vocoders
归一化流是一种生成模型。它用一系列可逆映射变换概率密度。由于我们可以通过基于变量变换规则的可逆映射序列得到标准/归一化概率分布(如高斯分布),因此这种基于流的生成模型称为归一化流。在采样期间,它通过这些变换的逆从标准概率分布生成数据。根据两种不同的技术,神经TTS中使用的基于流的模型可以分为两类: 1)自回归变换(例如,Parallel WaveNet中使用的逆自回归流), 2)bipartite变换(例如,WaveGlow[279]中使用的Glow, FloWaveNet[163]中使用的RealNVP)
自回归变换和bipartite变换都有各自的优缺点:
1)自回归变换通过对数据分布x与标准概率分布z之间的依赖关系进行建模,比bipartite变换更具表现力,但需要教师进行提炼,训练过程比较复杂。2)bipartite变换具有更简单的训练管道,但通常需要更多的参数(例如,更深的层,更大的隐藏尺寸)才能达到与自回归模型相当的能力。为了结合自回归和bipartite变换的优点,WaveFlow为音频数据提供了基于似然的模型的统一视图,以显式地将推理并行性交换为模型容量。这样,WaveNet、WaveGlow和FloWaveNet可以看作是waveflow的特殊情况。
Leo Guo:Normalization Flow (标准化流) 总结
GAN-based Vocoders
常用的GAN声码器类型
Generator。大多数基于gan的声码器使用扩展卷积来增加接收野来模拟波形序列中的长依赖性,并使用转置卷积来对条件信息(例如语言特征或mel-谱图)进行上采样以匹配波形序列的长度。Yamamoto等人[402]选择对条件信息进行一次上采样,然后进行展开卷积以保证模型容量。然而,这种上采样过早地增加了序列长度,导致了较大的计算成本。因此,一些声码器[178,174]选择对条件信息进行迭代上采样并进行展开卷积,这样可以避免较低层次序列过长。具体而言,VocGAN提出了一种多尺度发生器,可以从粗粒度到细粒度逐步输出不同尺度的波形序列。HiFi-GAN通过多接受场融合模块并行处理不同长度的不同图案,并且还具有在合成效率和样品质量之间进行权衡的灵活性。
Discriminator。Discriminator的研究主要集中在如何设计模型来捕捉波形特征,以便为发生器提供更好的引导信号。我们回顾了这些努力如下:
-
GAN-TTS中提出的随机窗口Discriminator,它使用多个Discriminator,其中每个Discriminator分别输入有条件信息和没有条件信息的波形的不同随机窗口。随机窗口Discriminator有几个好处,例如以不同的互补方式评估音频,与完整音频相比简化真假判断,以及起到数据增强效应等。
-
MelGAN提出的多尺度Discriminator,它使用多个Discriminator来判断不同尺度(与原始音频相比不同的下采样比)的音频。多尺度Discriminator的优点是每个尺度上的Discriminator都能集中于不同频率范围内的特征
-
HiFiGAN中提出的多周期Discriminator,它利用多个Discriminator,其中每个Discriminator接受具有周期的输入音频的等间隔采样。具体而言,将长度为T的一维波形序列重构为二维数据[p, T/p],其中p为周期,并进行二维卷积处理。多周期Discriminator可以通过观察输入音频在不同时期的不同部分来捕获不同的隐式结构。
-
分层Discriminator,在VocGAN中利用分层Discriminator从粗粒度到细粒度对生成的不同分辨率的波形进行判断,引导发生器学习低频和高频声学特征与波形之间的映射关系。
Loss。除了常规的GAN Loss,如WGAN-GP、hinge-loss和LS-GAN外,其他特定的Loss,如STFTLoss和特征匹配Loss也被利用。这些额外的损失可以提高对抗性训练的稳定性和效率,并改善感知音频质量。Gritsenko等人提出了带有排斥项的广义能量距离,以更好地捕获多模态波形分布。
- HiFiGAN
《HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis》 https://github.com/jik876/hifi-gan
HiFiGAN 是近年来在学术界和工业界都较为常用的声码器,能够将声学模型产生的频谱转换为高质量的音频,这种声码器采用生成对抗网络(Generative Adversial Networks,GAN)作为基础生成模型,相比于之前相近的 MelGAN,改进点在于:
-
引入了多周期判别器(Multi-Period Discriminator,MPD)。HiFiGAN 同时拥有多尺度判别器(Multi-ScaleDiscriminator,MSD)和多周期判别器,尽可能增强GAN判别器甄别合成或真实音频的能力,从而提升合成音质。
-
生成器中提出了多感受野融合模块。WaveNet为了增大感受野,叠加带洞卷积,音质虽然很好,但是也使得模型较大,推理速度较慢。HiFiGAN则提出了一种残差结构,交替使用带洞卷积和普通卷积增大感受野,保证合成音质的同时,提高推理速度。
Diffusion-based Vocoders
其基本思想是通过扩散过程和反向过程来表述数据与潜在分布之间的映射关系:在扩散过程中,波形数据样本逐渐加入一些随机噪声,最终成为高斯噪声;在反向过程中,随机高斯噪声逐步降噪到波形数据样本中。基于扩散的声码器可以生成高质量的语音,但由于迭代过程长,导致推理速度慢。因此,许多关于扩散模型的研究都在研究如何在保持生成质量的同时减少推理时间。
总结
我们总结了声码器中使用的不同类型生成模型的特征,如表6所示: 1)在数学简单性方面,基于自回归(AR)的模型比其他生成模型(如VAE、Flow、Diffusion和GAN)更容易。2)除AR外,所有生成模型均支持并行语音生成。3)除AR模型外,所有生成模型都能在一定程度上支持潜在操作(一些基于gan的声码器不以随机高斯噪声作为模型输入,因此不支持潜在操作)。4)基于gan的模型不能估计数据样本的似然,而其他模型则具有这一优点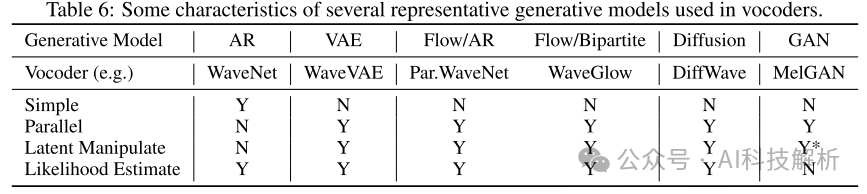
6、语音特征提取
上面已经讲解了将文本处理得到语音特征、声学模型将语言特征转换为声学特征、声码器将声学特征转换为音频的过程。这已经是一个完整的TTS推理过程。
但是在训练过程中,需要输入原始音频,用于鉴别生成的声学特征是否和原始音频的声学特征相似。(比如PitchPredictor生成的音高特征是否和原始音频的音高接近,EnergePredictor生成的能量特征是否和原始音频的音频能量接近。若数据接近,则有利于生成效果更好的目标音频) 那么就引入了常见声学特征有哪些以及如何获取这些特征的问题。
6.1、预处理
- 6.1.1 预加重
语音经过说话人的口唇辐射发出,受到唇端辐射抑制,高频能量明显降低。
赵易明:为什么要对语音信号「预加重」
一般来说,当语音信号的频率提高两倍时,其功率谱的幅度下降约 6dB,即语音信号的高频部分受到的抑制影响较大。在进行语音信号的分析和处理时,可采用预加重(pre-emphasis)的方法补偿语音信号高频部分的振幅,在傅里叶变换操作中避免数值问题,本质是施加高通滤波器。假设输入信号第 ? 个采样点为 ? [?] ,则预加重公式如下: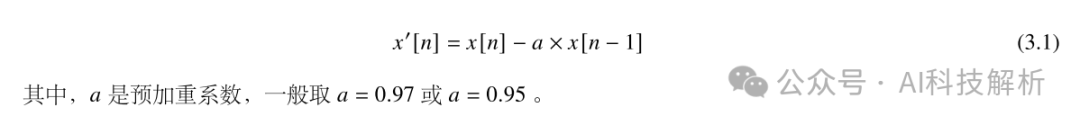
这个过程一般在数字音频信号经过模数转换之后,进入数字信号处理前的阶段。
- 6.1.2、分帧
语音信号是非平稳信号,考虑到发浊音时声带有规律振动,即基音频率在短时范围内时相对固定的,因此可以认为语音信号具有短时平稳特性,一般认为 10ms~50ms 的语音信号片段是一个准稳态过程。短时分析采用分帧方式,一般每帧帧长为 20ms或50ms。假设语音采样率为 16kHz,帧长为 20ms,则一帧有 16000 × 0.02 = 320个数据。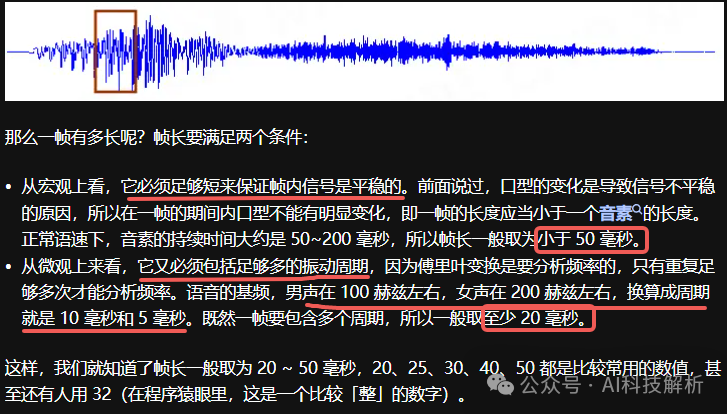
语音信号处理中怎么理解分帧?
相邻两帧之间的基音有可能发生变化,如两个音节之间,或者声母向韵母过渡。为确保声学特征参数的平滑性,一般采用重叠取帧的方式,即相邻帧之间存在重叠部分。一般来说,帧长和帧移的比例为 1 : 4 或 1 : 5 。
- 6.1.2、加窗
分帧相当于对语音信号加矩形窗,矩形窗在时域上对信号进行截断,在边界处存在多个旁瓣,会发生频谱泄露。为了减少频谱泄露,通常对分帧之后的信号进行其它形式的加窗操作。常用的窗函数有:汉明(Hamming)窗、汉宁(Hanning)窗和布莱克曼(Blackman)窗等。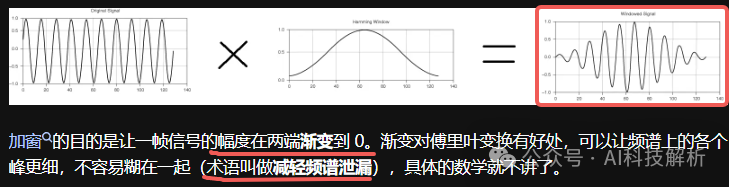
6.2、短时傅里叶变换
声音从频率上可以分为纯音和复合音,纯音只包含一种频率的声音(基音),而没有倍音。复合音是除了基音之外,还包含多种倍音的声音。大部分语音都是复合音,涉及多个频率段。傅里叶变换就是将一个函数拆成无数个不同频率正弦波之和的过程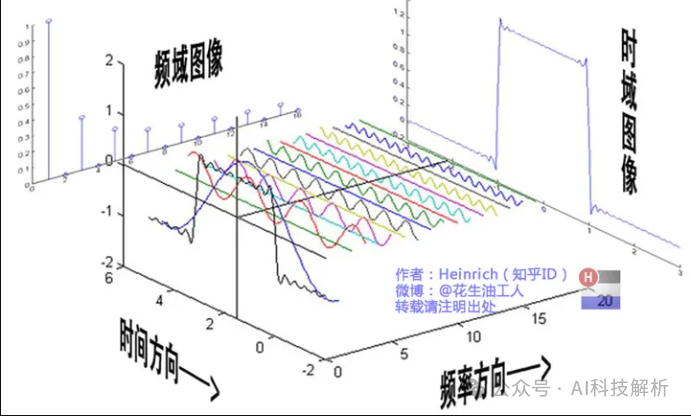
参考:Heinrich:如果看了这篇文章你还不懂傅里叶变换,那就过来掐死我吧
6.3、听觉特性
- 梅尔滤波
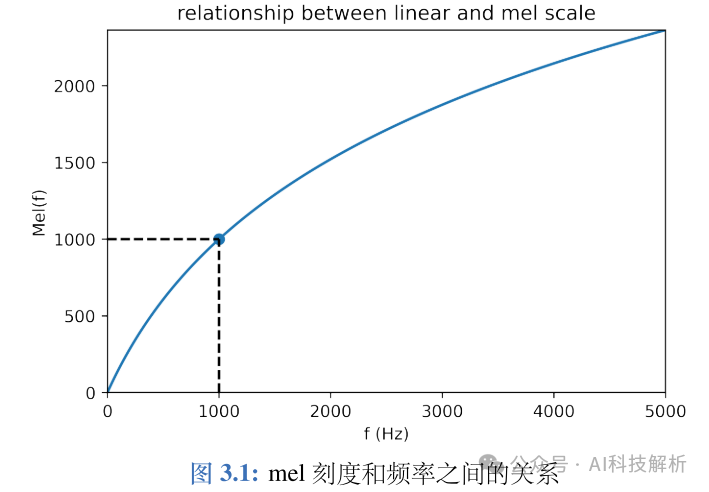
人类对不同频率的语音有不同的感知能力:
-
1kHz 以下,人耳感知与频率成线性关系。
-
1kHz 以上,人耳感知与频率成对数关系。
因此,人耳对低频信号比高频信号更为敏感。因此根据人耳的特性提出了一种mel刻度,即定义1个mel刻度相当于人对 1kHz 音频感知程度的千分之一,mel 刻度表达的是,从线性频率到"感知频率"的转换关系:
- Bark 滤波
人耳对响度的感知有一个范围,当声音低于某个响度时,人耳是无法感知到的,这个响度值称为听觉阈值,或称听阈。在实际环境中,但一个较强信号(掩蔽音)存在时,听阈就不等于安静时的阈值,而是有所提高。这意味着,邻近频率的两个声音信号,弱响度的声音信号会被强响度的声音信号所掩蔽(Mask),这就是频域掩蔽。根据听觉频域分辨率和频域掩蔽的特点,定义能够引起听觉主观变化的频率带宽为一个临界频带。一个临界频带的宽度被称为一个 Bark,Bark 频率 ?( ?) 和线性频率 ? 的对应关系定义如下: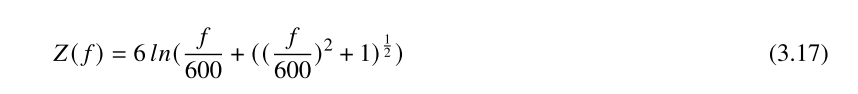
6.4、倒谱分析
人在发声时,肺部空气受到挤压形成气流,气流通过声门(声带)振动产生声门源激励 ?[?] 。对于浊音,激励 ?[?] 是以基音周期重复的单位冲激;对于清音,?[?] 是平稳白噪声。该激励信号 ?[?] 经过咽喉、口腔形成声道的共振和调制,特别是舌头能够改变声道的容积,从而改变发音,形成不同频率的声音。气流、声门可以等效为一个激励源,声道等效为一个时变滤波器,语音信号 ? [?] 可以被看成激励信号 ?[?] 与时变滤波器的单位响应 ? [?] 的卷积:
已知语音信号 ? [?] ,待求出上式中参与卷积的各个信号分量,也就是解卷积处理。可以采用倒谱分析实现解卷积处理。
倒谱分析,又称为同态滤波,采用时频变换,得到对数功率谱,再进行逆变换,分析出倒谱域的倒谱系数。
6.5、声学特征
FBank特征本质上是对数功率谱,包括低频和高频信息。相比于语谱图,FBank经过了梅尔滤波,依据人耳 听觉特性进行了压缩,抑制了一部分人耳无法感知的冗余信息。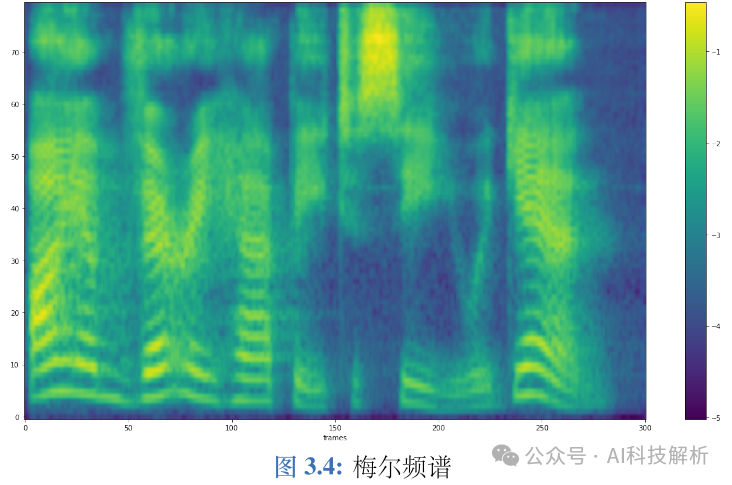
MFCC和 FBank唯一的不同就在于,获得 FBank特征之后,再经过反离散余弦变换,就得到 ? 个MFCC系 数。在实际操作中,得到的 ? 个MFCC特征值可以作为静态特征,再对这些静态特征做一阶和二阶差分,得到 相应的静态特征。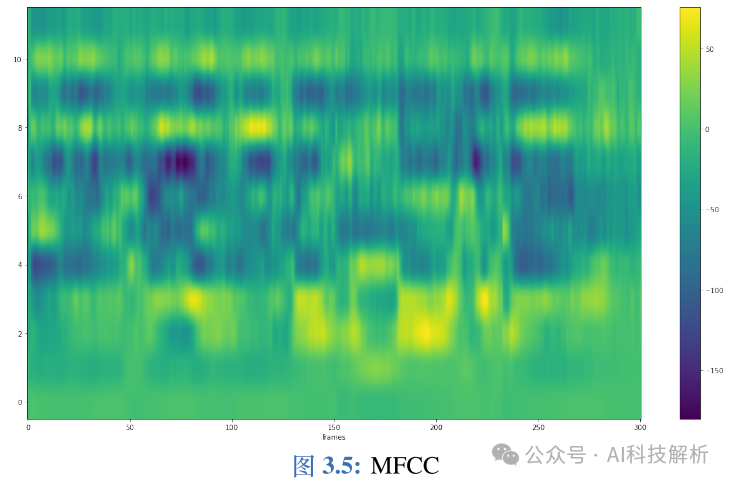
总结
1、基于LLM的方式在音色克隆方面质量更好,但生成质量不稳定,容易重复、漏字。参考VALL-E-X、GPT-SoVITS。
2、基于GAN的方式训练很困难。参考StyleTTS2。
3、基于SD的方式,音色多样性方面比GAN好一些,但是生成速度比较慢。参考NaturalSpeech1/2/3。
4、有些只基于SD生成style信息,再通过GAN生成音频,效果还不错,比如StyleTTS2。
5、基于Flow的模型在生成完整性上面更好一些。比如HierSpeechpp。
相关文章
-
akaihaoshuai:【TTS】2:VALL-E-X学习和代码实战
-
akaihaoshuai:【TTS】7:最强音色克隆GPT-SoVITS---代码讲解
-
akaihaoshuai:【TTS】5:StyleTTS2论文阅读和代码实战
-
akaihaoshuai:【TTS】8:NaturalSpeech 2论文和代码解读
-
akaihaoshuai:【TTS】6:HierSpeechpp论文阅读和代码实战
参考文章
-
https://github.com/cnlinxi/book-text-to-speech
-
《A Survey on Neural Speech Synthesis》
-
不同元音辅音在声音频谱的表现是什么样子?
-
语音信号处理中怎么理解分帧?
-
音素和音位的区别与联系是什么?
-
ICASSP 2020中的语音合成
-
《A HYBRID TEXT NORMALIZATION SYSTEM USING MULTI-HEAD SELF-ATTENTION FOR MANDARIN 》
-
无猫之徒:中文分词算法简介
-
https://slyne.github.io/%E5%85%AC%E5%BC%80%E8%AF%BE/2020/10/03/TTS1/
-
Leo Guo:Normalization Flow (标准化流) 总结
-
《HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
-
https://github.com/jik876/hifi-gan
-
赵易明:为什么要对语音信号「预加重」
-
Heinrich:如果看了这篇文章你还不懂傅里叶变换,那就过来掐死我吧