在Kafka中,TOPIC(主题)和分区(Partition)是核心概念,它们共同构成了Kafka消息系统的基本架构。以下是对TOPIC分区的详细解释:
一、TOPIC(主题)
-
定义:TOPIC是Kafka中数据发布和订阅的基本单位,它代表了相同类型的消息流。可以将TOPIC理解为一个逻辑上的消息容器,类似于数据库中的表或消息队列中的队列。
-
作用:
-
数据组织与分类:TOPIC将相关的消息进行逻辑分类和组织,使得消息的存储和管理更加灵活和高效。
-
消息发布与订阅:生产者(Producer)将消息发布到特定的TOPIC中,而消费者(Consumer)可以从该TOPIC中订阅并消费消息。
-
二、分区(Partition)
-
定义:分区是TOPIC的物理划分,每个TOPIC可以被划分成一个或多个分区。每个分区是一个有序的消息队列,存储了TOPIC中的一部分消息。
-
作用:
-
并行处理与负载均衡:分区允许Kafka对消息进行并行处理,每个分区可以由不同的Broker和消费者来处理,从而提高了系统的吞吐量和负载均衡能力。
-
数据冗余与容错:每个分区可以有多个副本存储在不同的Broker上,以提供高可用性和数据冗余,防止因Broker故障而导致消息丢失。
-
消息顺序性:在每个分区中,消息是按照写入顺序进行存储的,保证了消息的顺序性。
-
三、TOPIC与分区的关系
-
物理与逻辑:TOPIC是逻辑上的概念,而分区是物理上的存储单元。一个TOPIC可以包含一个或多个分区,每个分区都有独立的存储空间。
-
消息分发:生产者发送的消息会被分发到TOPIC的各个分区中,消费者则从分区中读取消息。Kafka通过分区实现了消息的并行处理和负载均衡。
总之,在Kafka中,TOPIC和分区共同构成了消息系统的基本架构。TOPIC作为逻辑上的消息容器,用于组织和分类消息;而分区作为物理上的存储单元,用于实现消息的并行处理、负载均衡、数据冗余和容错。这种设计使得Kafka能够处理大规模的实时数据流,支持高吞吐量、低延迟和高可用性的数据传输和处理。
四、分区文件的组成
1. 日志文件(.log)
.log文件为数据文件,存放具体消息数据。
每个分区都由一系列有序的、不可变的消息组成,这些消息被连续的追加到分区中。分区中的每个消息都有一个连续的序列号叫做offset,用来在分区中唯一的标识这个消息。
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:
offset
MessageSize
data
其中offset为long型,MessageSize为int32,表示data有多大,data为message的具体内容。它的格式和Kafka通讯协议中介绍的MessageSet格式是一致。
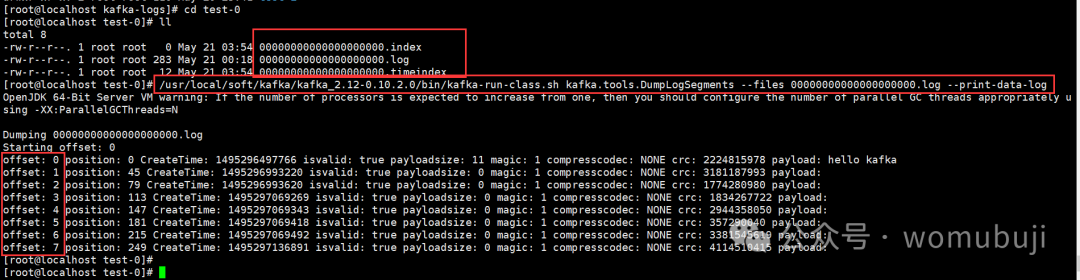
在一个可配置的时间段内,Kafka集群保留所有发布的消息,不管这些消息有没有被消费。比如,如果消息的保存策略被设置为2天,那么在一个消息被发布的两天时间内,它都是可以被消费的。之后它将被丢弃以释放空间。Kafka的性能是和数据量无关的常量级的,所以保留太多的数据并不是问题。
实际上每个consumer唯一需要维护的数据是消息在日志中的位置,也就是offset.这个offset有consumer来维护:一般情况下随着consumer不断的读取消息,这offset的值不断增加,但其实consumer可以以任意的顺序读取消息,比如它可以将offset设置成为一个旧的值来重读之前的消息。
2. 索引文件(.index 和 .timeindex)
为了提高消息的读取效率,Kafka为每个分区的日志文件创建了索引文件。索引文件包括偏移量索引文件(.index)和时间戳索引文件(.timeindex)。偏移量索引文件用于建立消息偏移量到消息在日志文件存储的物理地址之间的映射关系;时间戳索引文件则用于建立消息时间戳与消息偏移量之间的映射关系,以便按时间顺序快速查找消息。
.index文件为索引文件,命名规则为从0开始到,后续的由上一个文件的最大的offset偏移量来开头(19位数字字符长度)。
数据文件分段使得可以在一个较小的数据文件中查找对应offset的Message了,但是这依然需要顺序扫描才能找到对应offset的Message。为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文件名与数据文件的名字是一样的,只是文件扩展名为.index。
索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
-
相对offset 因为数据文件分段以后,每个数据文件的起始offset不为0,相对offset表示这条Message相对于其所属数据文件中最小的offset的大小。举例,分段后的一个数据文件的offset是从20开始,那么offset为25的Message在index文件中的相对offset就是25-20 = 5。存储相对offset可以减小索引文件占用的空间。
-
position 表示该条Message在数据文件中的绝对位置。只要打开文件并移动文件指针到这个position就可以读取对应的Message了。
Partition------index和log的匹配关系
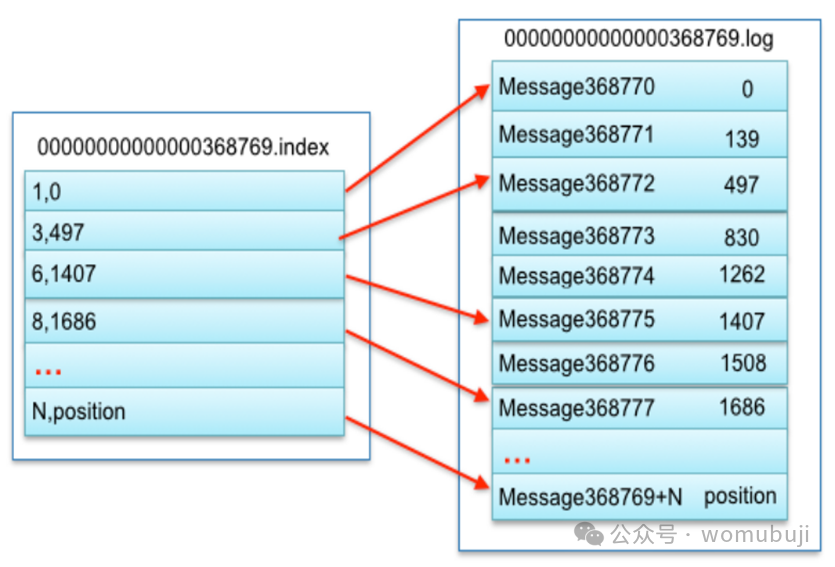
368769.log: 368769为上一文件最大offset;
.index与.log同名;
N:相对offset;
position:全局分区中的绝对位置;
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message的物理偏移地址。其中以索引文件中 元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移 地址为497。
.timeindex文件,是kafka的具体时间日志。





