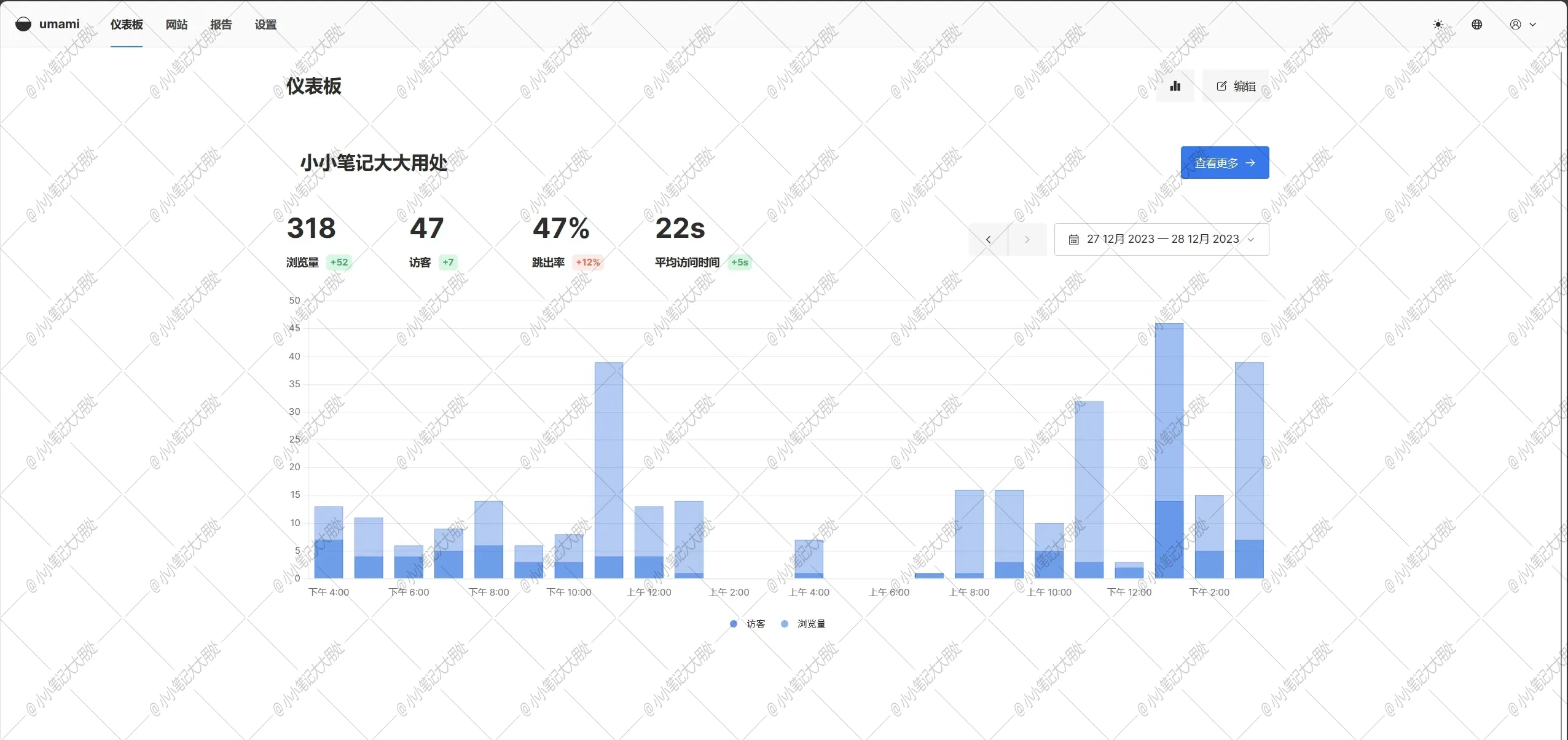
1.MySQL的索引为什么使用B+Tree这种数据结构?
1.我们先来看一下B+Tree数据结构的样子 2. 可以看到,它的根节点和支节点不保存数据区,只是保存了一些键,因此一次读取的话,就可以读取到更多的键,这样就可以快速的缩小查找范围。
3. 可以看到B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候。只需要找到最小的节点,然后通过链进行顺序遍历即可获取。
4. 具体的话可以结合别的树来进行对比理解可以参考这篇文章
2. 可以看到,它的根节点和支节点不保存数据区,只是保存了一些键,因此一次读取的话,就可以读取到更多的键,这样就可以快速的缩小查找范围。
3. 可以看到B+树的叶节点由一条链相连,因此,当需要进行一次全数据遍历的时候。只需要找到最小的节点,然后通过链进行顺序遍历即可获取。
4. 具体的话可以结合别的树来进行对比理解可以参考这篇文章
2.什么是索引?索引的优缺点?
-
简单的理解,索引就相当于目录。为了方便查找书中的内容,我们通常可以去查看目录看看要找的内容在哪页或者哪个区域页里。然后就可以快速的查找到我们想要的内容。
-
官方理解:索引是一种数据结构。数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树
-
索引的优缺点:
-
优点:
-
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
-
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能
-
-
缺点:
-
时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率
-
空间方面:索引需要占物理空间
-
3.innoDB是否支持hash索引?
-
InnoDB引起有一个特殊的功能叫做"自适应哈希索引" 。当InnoDB注意到某些索引值被使用的非常频繁时,它会在内存中基于B+Tree索引之上再创建一个哈希索引。
4.创建索引的原则
-
最左前缀匹配原则,组合索引非常重要的原则。
-
较频繁作为查询条件的字段才去创建索引
-
更新频繁字段不适合创建索引
-
若是不能有效区分数据的列不适合做索引列
-
尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可
-
定义有外键的数据列一定要建立索引
5.数据库为什么使用B+树而不是B树?
-
B树只适合随机检索,而B+树同时支持随机检索和顺序检索
-
B+树空间利用率更高,可减少I/O次数,磁盘读写代价更低
-
增删文件(节点)时,效率更高。因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率
6.什么是前缀索引?
-
使用字段值的前6(n)个字符建立索引,默认是使用字段的全部内容建立索引
-
语法:alter table 表名 add index 索引名字(列名(取个值)); 如:alter table test add index key(address(6));
-
怎么确定前缀长度:select COUNT(DISTINCT address)/COUNT(*) from test; PS:查询表的索引:show index from 表名;
7.什么是回表,索引覆盖,索引下推,最左匹配原则?======+1
-
回表:比如一个表(test)有字段id和name,给id(主键索引)和name(二级索引)建立索引,此时我们使用命令:select * from test where name = "李四";由于索引底层数据结构的B+Tree,对name列建立的索引叫做二级索引或者辅助索引,这个索引的数据存储的是id,我们执行完SQL时,会从name的B+Tree中拿到id,再回到id的B+Tree中去搜索所对应的数据,这个过程就叫做回表
-
索引覆盖:如果此时我们用的是这样的命令:select id from student where name="李四";那么,就不会再去id的对应索引的那颗B+Tree上再去搜索一遍了,这就是索引覆盖
-
索引下推:比如现在查询name和age字段,在没有索引下推前是这样的:存储引擎先从磁盘中筛选出name符合条件的数据,全部取出,MySQL 服务器再根据age条件筛选一次。索引下推后:存储引擎先从磁盘中直接筛选出name,age同时都符合条件的数据,不需要服务器再去做任何的数据筛选
-
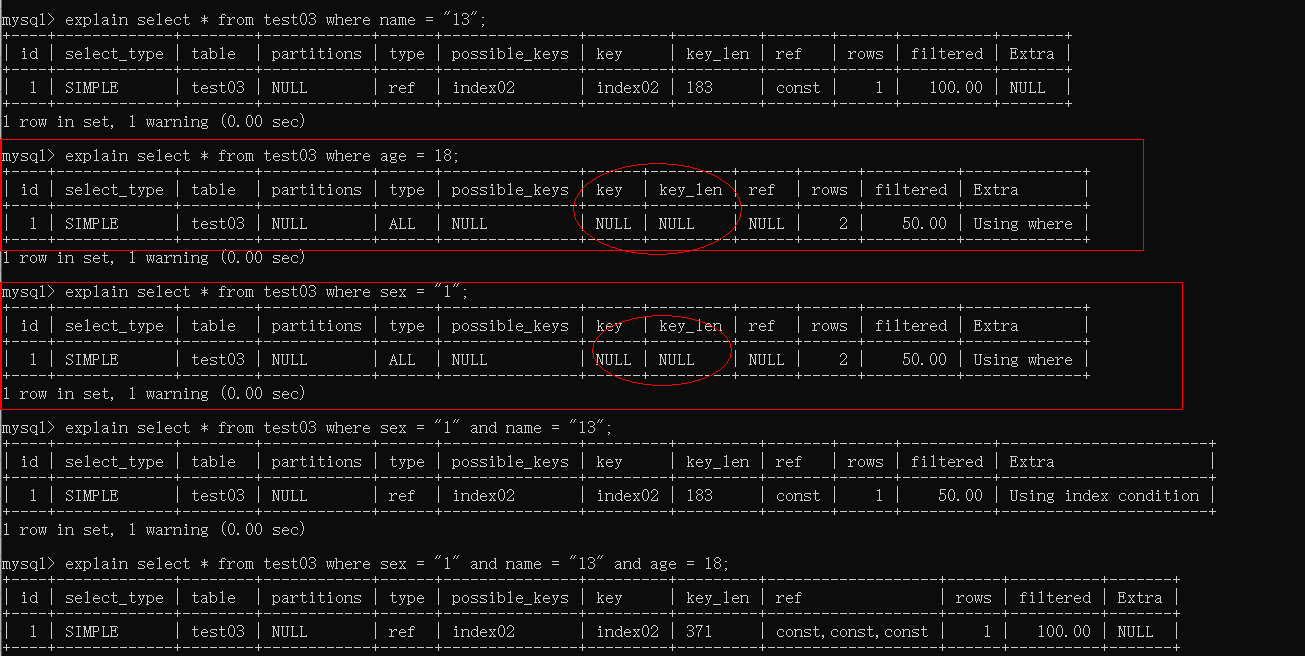
最左匹配原则:比如一个表,其中有三个字段(name, age, sex)是组合索引,如图查看: PS:可以看到,两个我圈起来的并没有走索引
8.什么叫MRR?
比如一个表(test)有字段id和name,给id(主键索引)和age(二级索引)建立索引,此时我们使用命令:select * from test where age > 18;会返回一组id值,如果我们一个id一个id的去找,会很慢。这时候可以对id进行排序,这样会得到一个id的范围,可以范围查找,不用挨个去遍历了,这个过程就叫做MRR
9.什么叫FIC?
-
插入操作:(1)先创建临时表,将数据导入到临时表。(2)把原始表删除。(3)修改临时表的名字。
-
给当前表添加一个share琐,不会有创建临时文件的资源消耗,还是在源文件中进行。但是此时如果有人进行DML操作,很明显数据会不一致,所以添加Share琐,读取时没有问题。
10.索引有哪几种类型?
-
主键索引:数据列不允许重复,不允许为NULL,一个表只能有一个主键。
-
唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
-
可以通过 ALTER TABLE table_name ADD UNIQUE (column); 创建唯一索引
-
可以通过 ALTER TABLE table_name ADD UNIQUE (column1,column2); 创建唯一组合索引
-
-
普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
-
可以通过ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引
-
可以通过ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建组合索引
-
-
全文索引: 是目前搜索引擎使用的一种关键技术。
- 可以通过ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
-
组合索引:用多个列组合构建的索引,这多个列中的值不允许有空值
- 可以通过ALTER TABLE table_name ADD INDEX index_name('col1','col2','col3');创建
11.索引的匹配方式?
-
全值匹配:
-
匹配最左前缀:
-
匹配列前缀:
-
匹配范围值:
-
精确匹配某一列并范围匹配另外一列:
-
只访问索引的查询:
12.索引什么时候失效?
-
在使用模糊查询的时候索引会失效,这个情况指的是'%李%'和'%李',如果是这个情况'李%',索引会有效
-
如果在使用组合索引的时候,比如三个字段的组合索引(name, age, sex),这时我们查找的时候,我们条件为name = ?,age > 18, sex = ?。这时,中间的age使用了>(范围查找),索引会失效,最后的索引使用为name和age,sex的索引不会用到
-
当使用or的时候,如果表里有个普通列,而你查询的时候要求返回该列的指,那么所以就会失效,如果查询的时候要求返回的都是组合索引,那么会走所有的索引。比如(表有三个字段,name, age, sex。name和age是一个组合索引,sex是一个普通列):select * from test where name = ? or age = 18;这时因为用了*表示返回所有的字段值,此时索引会失效。select name, age from test where name = ? or age = 18 这时就会走所有索引
-
隐式类型转换的时候,索引也会失效。
13.hash索引的限制?
-
hash索引必须进行二次查找。
-
hash索引无法进行排序。
-
hash索引不支持部分索引查找也不支持范围查找。
-
hash索引中hash码的计算可能存在hash冲突。
14.什么是聚簇索引?它的优缺点?什么是非聚簇索引?
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据。聚簇索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的就是整张表的行记录数据,也将聚集索引的叶子节点称为数据页。这个特性决定了索引组织表中数据也是索引的一部分,每张表只能拥有一个聚簇索引。Innodb通过主键聚集数据,如果没有定义主键,innodb会选择非空的唯一索引代替。如果没有这样的索引,innodb会隐式的定义一个主键来作为聚簇索引
-
聚簇索引的优点:
-
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快
-
聚簇索引对于主键的排序查找和范围查找速度非常快
-
-
聚簇索引的缺点:
-
插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
-
更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新
-
二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
-
- 非聚簇索引:就是指B+Tree的叶子节点上的data域并不直接保存数据,而是数据的地址(其实也可以叫做指针)。并且Myisam引擎的主索引和辅助索引在结构上没有任何区别,唯一的区别是主索引要求key是唯一的,而辅助索引的key可以重复
15.为什么使用索引的时候尽量不要使用表达式?
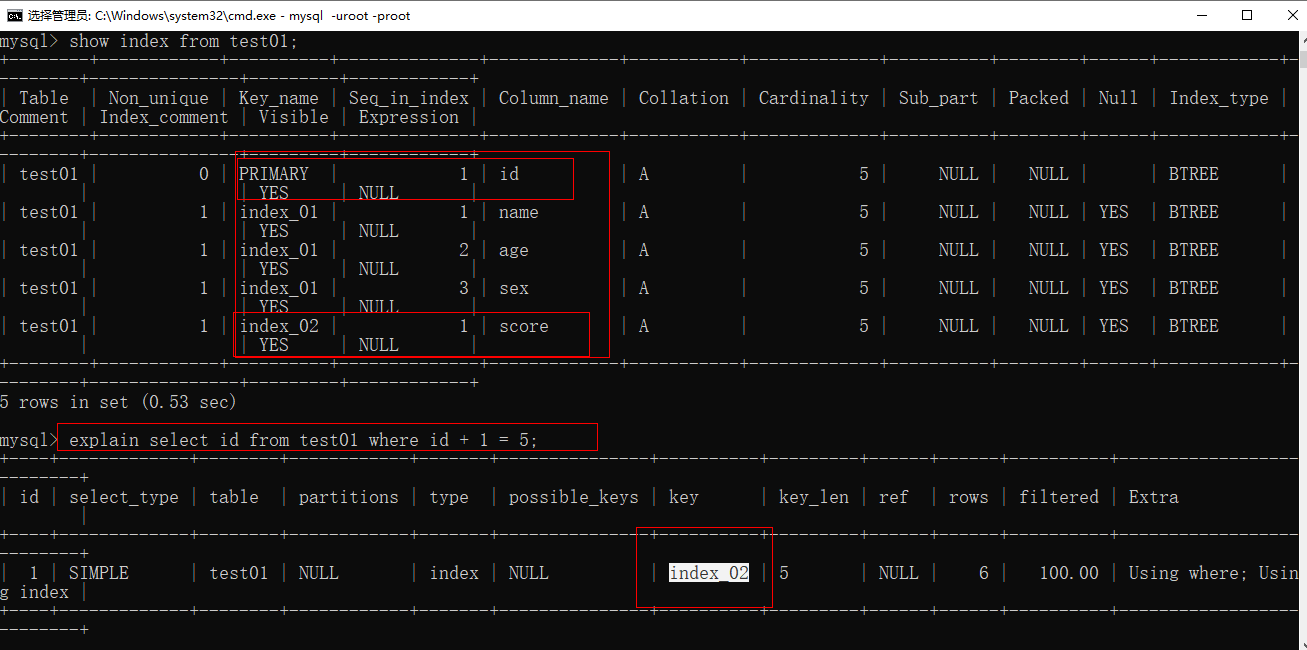
- 比如当我们在去查找主键的时候(explain select id from test01 where id + 1 = 5),可以看到这时用到了表达式,本身这个时候的索引使用的应该是主键索引的,但是查看会发现使用了普通索引。
- 看图可以看到我们查的是id这个字段,本身走的索引应该也是它,但是可以看到它走的时普通索引
16.为什么尽量使用主键查询,而不是使用其它索引?
- 因为主键查询不会触发回表查询
17.什么是自然主键,什么是代理主键?为什么要使用主键自增?
-
自然主键:就是充当主键的字段本身具有一定的含义,是构成记录的组成部分,比如学生的学号,除了充当主键之外,同时也是学生记录的重要组成部分
-
代理主键:就是充当主键的字段本身不具有业务意义,只具有主键作用,比如自动增长的ID
-
为什么建议使用主键自增:
-
数据存储空间小
-
InnoDB默认都会在主键上建立主键索引,使用int作为主键可以将更多的索引载入内存,提高查询性能
-
在数据插入时,可以保证逻辑相邻的元素物理也相邻,便于范围查找
-
在数据插入、删除、更新时可以做到索引数据尽可能少的移动、分裂页,减少碎片的产生
18.怎么使用索引扫描来进行排序?
- MySQL可以使用同一个索引既满足排序,又用于查找行,只有当索引列的顺序和ORDER BY字句的要求顺序是一致的,并且所有列的排序方向(倒序或正序时)MySQL才能够使用索引来对结果进行排序。如果查询需要关联多张表, 则只有当 ORDER BY 子句引用的字段全部为第一个表时,才能使用索引做排序。ORDER BY 子句和查找型查询的限制是一样的:需要满足索引的最左前缀的要求。否则, MySQL都需要执行排序操作,而无法利用索引排序可以看看这篇文章
19.MySQL存储引擎都有哪些?MyISAM与InnoDB区别?=========+1
-
mysql所有引擎大概有八个,常用的有InnoDB,MyISAM,MEMORY
-
MyISAM与InnoDB区别
对应关系|MyISAM|InnoDB :---:|:---:|:---: 存储结构|每张表被存放在三个文件--frm-表格定义、MYD(MYData)-数据文件、MYI(MYIndex)-索引文件|所有的表都保存在同一个数据文件中--也可能是多个文件,或者是独立的表空间文件 存储空间|MyISAM可被压缩,存储空间较小|InnoDB的表需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引 可移植性、备份及恢复|由于MyISAM的数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作|免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了 文件格式|数据和索引是分别存储的,数据.MYD,索引.MYI|数据和索引是集中存储的,.ibd 记录存储顺序|按记录插入顺序保存|按主键大小有序插入 外键|不支持|支持 事务|不支持|支持 锁支持|表级锁定|行级锁定、表级锁定,锁定力度小并发能力高 SELECT|MyISAM更优| INSERT、UPDATE、DELETE||InnoDB更优 select count(*)|myisam更快,因为myisam内部维护了一个计数器,可以直接调取| 索引的实现方式|B+树索引,myisam 是堆表|B+树索引,Innodb 是索引组织表 哈希索引|不支持|支持 全文索引|支持|不支持
20.mysql里面常用的分组函数有哪些?
-
count 计数;sum 求和;avg 平均值;max 最大数;min 最小数
-
需要注意的是:分组函数分自动忽略null,即null不计数,如果你计算的列里有null值存在的话,建议使用ifnull去进行计算:例--select *, ifnull(age, 0) * 12 from test01;
21.MySQL的CBO和RBO有什么区别?
- CBO的基于成本优化,RBO式基于规则优化。
22.说一下事务的四个特性?
-
原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用
-
一致性: 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的
-
隔离性: 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的
-
持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响
23.数据库的事务隔离级别?=========+2
-
由低到高依次为READ-UNCOMMITTED、READ-COMMITTED、REPEATABLE-READ、SERIALIZABLE
-
这四个分别表示:
-
READ-UNCOMMITTED(读取未提交): 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-
READ-COMMITTED(读取已提交): 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。PS: Oracle 默认采用
-
REPEATABLE-READ(可重复读): 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。PS:MySQL默认采用这个
-
SERIALIZABLE(可串行化): 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读
24.什么是脏读?幻读?不可重复读?
-
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的
-
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据
-
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几列(Row)数据,而另一个事务却在此时插入了新的几列数据,先前的事务在接下来的查询中,就会发现有几列数据是它先前所没有的
25.select * from test01 where age > avg(age);运行报错,为什么报错?
- 分组函数不能直接使用在where子句当中。因为group by语句是在where后面执行的,而分组函数是在group by执行之后才执行的。这样写的话就把分组函数写在了group by语句前面。所以分组函数不能使用在where后面。
26.一张表,有很多数据,主键是自增的,怎么去获取到最后一条数据?=======+1
- 方式1:简单思路就是先将id字段倒序排序然后使用limit取第一个即可:
- select * from test order by id desc limit 1;
- 方式2:思路就是查询id等于最大的那个
- select * from test where id = (select max(id) from test);
27.mysql分页怎么去做的?
-
使用limit可以进行分页查询:select id,title from test limit 1000,10;
-
优化:select id from test order by id limit 90000,10;这样写可以使用到id主键的索引,可以大大加快查询速度。
28.sql的执行顺序?
-
FROM [left_table] ---选择表
-
ON <join_condition> --- 链接条件
-
<join_type> JOIN <right_table> --- 链接
-
WHERE <where_condition> --- 条件过滤
-
GROUP BY <group_by_list> --- 分组
-
AGG_FUNC(column or expression),... --- 聚合函数
-
HAVING <having_condition> --- 分组过滤
-
SELECT(9) --- 选择字段
-
DISTINCT column,... --- 去重
-
ORDER BY <order_by_list> --- 排序
-
LIMIT count OFFSET count; --- 分页
29.sql调优的方法?======+1
-
查询SQL尽量不要使用select *,而是具体字段
-
避免在where子句中使用or来连接条件
-
使用varchar代替char
-
尽量使用数值替代字符串类型
-
查询尽量避免返回大量数据
-
使用explain分析你SQL执行计划
-
是否使用了索引及其扫描类型
-
创建name字段的索引
-
优化like语句
-
索引不宜太多,一般5个以内
-
注意字符串隐式类型转换问题
-
索引不适合建在有大量重复数据的字段上
-
where限定查询的数据
-
避免在索引列上使用内置函数
-
避免在where中对字段进行表达式操作
-
避免在where子句中使用!=或<>操作符
-
去重distinct过滤字段要少
-
where中使用默认值代替null
PS:可以看看这篇文章
30.数据库的内连接和外连接的区别?=======+1
-
内连接:匹配不到的不显示
-
外连接:匹配不到的主表数据显示,副表显示为空
31.主键索引和复合索引以及单列索引哪个优先级高?======+1
- 复合索引 > 主键索引 > 单列索引 PS:这个问题奇奇怪怪的,不知道什么个情况,这个答案是我自己测试的,如果错了,希望有懂的人能够指出来一下,谢谢!
32.比如一张表(test),有4个字段,name(姓名), age(年龄), sal(月薪资),comm(津贴) ,这时比如有三个人,其中有一个人的津贴字段为null。请问怎么计算每个人的年薪资?
- select name,sal * 12 + (case when comm is null then 0 else comm end) as year_sal from test;
33.查找入职员工时间倒数第三的员工的所有信息?
-
select * from test01 where hire_date=(select distinct hire_date from test01 order by hire_date desc limit 2, 1);
-
select * from test01 order by hire_date desc limit 2,1;
PS:参考文章