1.MyBatis是什么?他的优缺点?
-
MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射
-
优点:
-
基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用
-
与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接
-
很好的与各种数据库兼容
-
提供映射标签,支持对象与数据库的ORM字段关系映射;提供对象关系映射标签,支持对象关系组件维护
- 缺点:
-
SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求
-
SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
2.JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
-
数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库连接池可解决此问题
-
Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码
-
向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应
-
对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便
3.MyBatis编程步骤是什么样的?
-
创建SqlSessionFactory
-
通过SqlSessionFactory创建SqlSession
-
通过sqlsession执行数据库操作
-
调用sqlsession.commit()提交事务
-
调用sqlsession.close()关闭会话
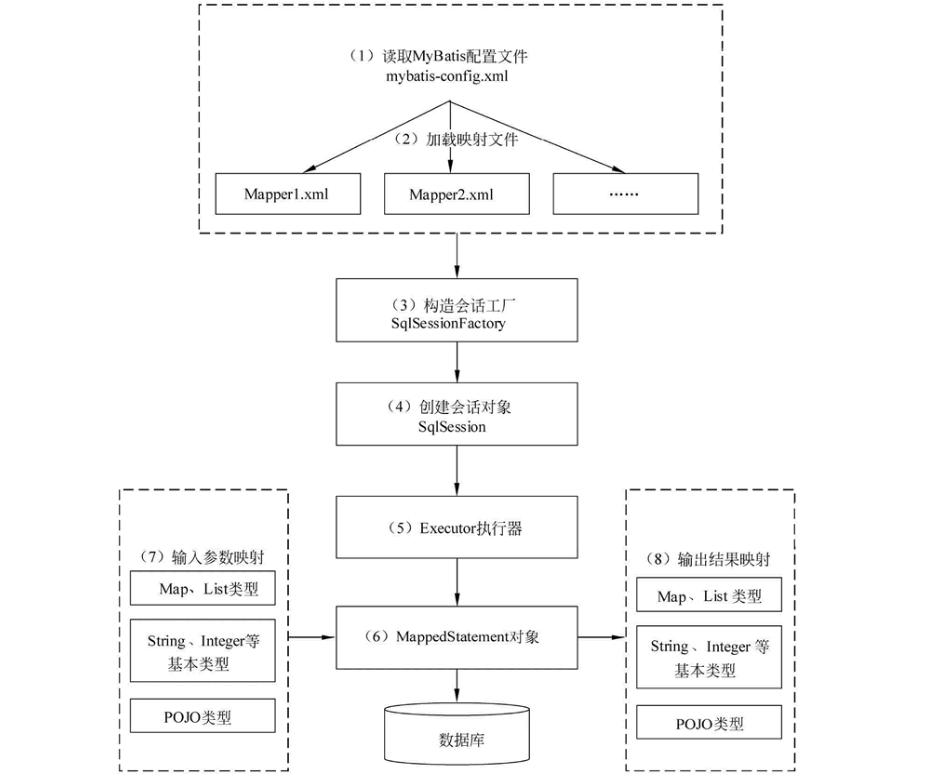
4.请说说MyBatis的工作原理?
- 原理图
-
读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息
-
加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表
-
构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory
-
创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法
-
Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护
-
MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息
-
输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程
-
输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程
5.什么是预编译?为什么要使用预编译?
-
SQL 预编译指的是数据库驱动在发送 SQL 语句和参数给 DBMS 之前对 SQL 语句进行编译,这样 DBMS 执行 SQL 时,就不需要重新编译
-
JDBC 中使用对象 PreparedStatement 来抽象预编译语句,使用预编译。预编译阶段可以优化 SQL 的执行。预编译之后的 SQL 多数情况下可以直接执行,DBMS 不需要再次编译,越复杂的SQL,编译的复杂度将越大,预编译阶段可以合并多次操作为一个操作。同时预编译语句对象可以重复利用。把一个 SQL 预编译后产生的 PreparedStatement 对象缓存下来,下次对于同一个SQL,可以直接使用这个缓存的 PreparedState 对象。Mybatis默认情况下,将对所有的 SQL 进行预编译
6.#{}和${}的区别?======被问+2
-
${}是拼接符,字符串替换,没有预编译处理。#{}是占位符,预编译处理,
-
Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法来赋值
-
Mybatis在处理${}时,是原值传入,就是把${}替换成变量的值,相当于JDBC中的Statement编译
-
变量替换后,#{} 对应的变量自动加上单引号 '';变量替换后,${} 对应的变量不会加上单引号 ''
-
${} 不能防止SQL 注入,#{} 可以有效的防止SQL注入,提高系统安全性;
-
${} 的变量替换是在 DBMS 外,#{} 的变量替换是在DBMS 中;
7.Mybatis模糊查询like语句该怎么写?需要注意什么?
-
"%"#{question}"%" :正确写法之一
-
因为#{...}解析成sql语句时候,会在变量外侧自动加单引号' ',所以这里 % 需要使用双引号" ",不能使用单引号 ' ',不然会查不到任何结果
8.在mapper中如何传递多个参数?
-
顺序传参法---不建议使用
-
@Param注解传参法
-
Map传参法
-
java实体类传参法
9.当实体类中的属性名和表中的字段名不一样 ,怎么办?
-
通过在查询的SQL语句中定义字段名的别名,让字段名的别名和实体类的属性名一致
-
通过<resultMap>来映射字段名和实体类属性名的一一对应的关系。
PS:通过resultMap的方式
<?xml version="1.0" encoding="GBK" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.com.shallow.dao.UserMapper">
<!-- resultMap-->
<resultMap id="userMap" type="user">
<!--column:数据库中的字段 property:实体类中的属性-->
<!-- <result column="id" property="id"/>-->
<!-- <result column="name" property="name"/>-->
<result column="password" property="pwd"/>
</resultMap>
<select id="getListUser" resultMap="userMap" >
select * from mybatis_study;
</select>
</mapper>
10.什么是MyBatis的接口绑定?有哪些实现方式?
-
接口绑定,就是在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定,我们直接调用接口方法就可以,这样比起原来了SqlSession提供的方法我们可以有更加灵活的选择和设置
-
实现方法有两种:
-
通过注解绑定,就是在接口的方法上面加上 @Select、@Update等注解,里面包含Sql语句来绑定
-
通过xml里面写SQL来绑定, 在这种情况下,要指定xml映射文件里面的namespace必须为接口的全路径名
11.使用MyBatis的mapper接口调用时有哪些要求?
-
mapper接口的方法名要与mapper.xml里的每个sql定义的id名相同
-
Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
-
Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
-
Mapper.xml文件中的namespace即是mapper接口的类路径
12.Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
-
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复
-
原因就是namespace+id是作为Map<String, MappedStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同
-
在Mybatis中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象
13.MyBatis实现一对一,一对多有几种方式,怎么操作的?======+1
-
有联合查询和嵌套查询;联合查询是几个表联合查询,只查询一次,通过在resultMap里面的association,collection节点配置一对一,一对多的类就可以完成。嵌套查询是先查一个表,根据这个表里面的结果的外键id,去再另外一个表里面查询数据,也是通过配置association,collection,但另外一个表的查询通过select节点配置
-
操作:
PS:一对一实现的两种方式
<?xml version="1.0" encoding="GBK" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.shallow.dao.StudentMapper">
<!-- 按照查询嵌套处理-即嵌套查询-->
<select id="getStudentList" resultMap="studentMap">
select * from student;
</select>
<resultMap id="studentMap" type="student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<!--复杂的属性,需要单独处理,比如现在Student类里有个Teacher对象
对象处理:association
property: Student实体类中定义对象的名字 即:teacher
column: 数据库字段名字 即uid
javaType: 这个定义对象的类型 即:Teacher
select: 嵌套的select查询语句的对应id 即:getTeacherList
集合处理:collection
-->
<association property="teacher" column="uid" javaType="Teacher"
select="getTeacherList"/>
</resultMap>
<select id="getTeacherList" resultType="teacher">
select * from teacher where id = #{id};
</select>
<!-- 按照结果嵌套处理-即联合查询-->
<select id="getStudentList" resultMap="studentMap">
select
s.id sid, s.name "学生姓名", t.id id, t.name "老师"
from
student s, teacher t
where
s.uid = t.id;
</select>
<resultMap id="studentMap" type="Student">
<result property="id" column="sid"/>
<result property="name" column="学生姓名"/>
<!-- property : 对应的Student实体类的Teacher对象命名的字段
javaType : Teacher
-->
<association property="teacher" javaType="Teacher">
<result property="id" column="id"/>
<result property="name" column="老师"/>
</association>
</resultMap>
</mapper>
PS:一对多的两种实现方式
<?xml version="1.0" encoding="GBK" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.shallow.dao.TeacherMapper">
<select id="getAllTeacher" resultMap="teacherMap">
select * from teacher where id = #{uid};
</select>
<resultMap id="teacherMap" type="teacher">
<!--集合用collection
property: 一样是集合对象的变量名
javaType: 这里集合有点不一样,普通的对象写对象名字即可,这里写:ArrayList
ofType: 这里写定义集合的对象名 即 Student
select: 一样是嵌入子查询的id 即 getStudent
-->
<collection property="student" javaType="ArrayList" ofType="Student"
select="getStudent" column="id"/>
</resultMap>
<select id="getStudent" resultType="student">
select * from student where uid = #{uid};
</select>
<!---->
<select id="getAllTeacher" resultMap="teacherMap">
select
t.id tid, t.name tname, s.id sid, s.name sname, s.uid
from
teacher t, student s
where
t.id = s.uid and t.id = #{uid}
</select>
<resultMap id="teacherMap" type="teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<!--
使用集合:collection
property: 这个为实体类中的变量名
ofType: 这个为实体类
-->
<collection property="student" ofType="Student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result property="uid" column="uid"/>
</collection>
</resultMap>
</mapper>
14.Mybatis动态sql是做什么的?都有哪些动态sql?======+1
-
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能
-
Mybatis提供了9种动态sql标签trim|where|set|foreach|if|choose|when|otherwise|bind
15.什么是缓存?为什么使用缓存?
-
缓存:存在内存中的临时数据,将用户经常查询的数据放在缓存中,用户去查询数据就不用从磁盘上查询,而是从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题
-
为什么使用缓存:
-
减少和数据库的交互次数,减少系统开销,提高系统效率
-
当我们经常查询但是不经常改变的数据,就可以使用缓存
16.mybatis缓存失效的情况?
-
使用更新 插入 删除语句的时候,缓存会更新,即失效
-
关闭连接也会失效
-
手动清理缓存
-
不同Mapper文件
17.一级缓存是什么?什么时候结束?
-
一级缓存也叫本地缓存,与数据库同一次会话期间查询的数据会放到本地缓存中,以后要用到这些数据的时候直接从缓存中拿,不需要再去查询数据库
-
一级缓存结束于你关闭SqlSession的时候
18.什么是二级缓存?它的机制是什么?
-
二级缓存也叫全局缓存,基于namespace级别的缓存,一个名称空间对应一个二级缓存
-
工作机制:
-
一个会话查询到一条数据,这个数据就会被放在当前会话的一级缓存中
-
如果会话关闭了,这个会话的一级缓存就没了,但是我们想要的是,这个一级缓存关闭了,数据会保存到二级缓存中
-
新的会话查询信息,就可以从二级缓存中获取内容
-
不同的mapper查处的数据会放在自己对应的缓存中
PS:二级缓存注意点:二级缓存是在一级缓存关闭之后才会将数据放到二级缓存的 PS:缓存的一个原理(执行顺序):1.先去二级缓存里查看是否有想要的数据,有就直接取;2.二级缓存没有再去一级缓存里查看是否有,有就直接取;3.如果一级缓存也没有,再去数据库查询,然后数据查询到的会放在一级缓存里,一级缓存关闭数据会放到二级缓存里去
19.如何获取生成的主键?======+1
- 对于支持主键自增的数据库:
- 使用useGeneratedKeys + keyProperty组合的方式;其中userGeneratedKeys代表是告诉mybatis要使用自增生成的主键,keyProperty是告诉mybatis主键字段是哪个。
PS:使用代码理解吧!
<!--这个是mapper文件-->
<insert id="test" parameterType="user" useGeneratedKeys="true" keyProperty="id">
INSERT
INTO
testTable(name, age)
VALUES(#{name}, #{age});
</insert>
<!--这里是mapper接口的方法-->
int insert(User user);
<!--这里是java代码-->
User user = new User("李四", 18);
int num = PersonMapper.insert(user);
// 这个就是主键id了
int id = user.getId();
- 不支持主键自增的数据库可以使用selectKey,当然支持的也可以使用。
<!--前提需要主键字符串 需要设置长度36-->
<insert id="insertUser" parameterType="user">
<selectKey keyColumn="id" resultType="java.lang.String" keyProperty="id" order="BEFORE">
SELECT UUID()
<!--Mysql使用SELECT LAST_INSERT_ID()但是要记得使用order等于AFTER-->
</selectKey>
INSERT
INTO
testTable(name, age)
VALUES(#{name}, #{age});
</insert>
20.Mybatis是如何进行分页的?======+1
- 使用Map来进行包装数据实现分页功能
-
在SQL语句映射的ResultType返回的是你要查询得到的实体类
-
传入参数类型为Map
-
然后给map里面put你要分页的条件,记得key的名字和映射文件要一致
<!--mapper文件-->
<select id="getLimit" parameterType="map" resultType="user">
select * from mybatis_study limit #{startIndex},#{pageSize};
</select>
<!--mapper接口的方法-->
List<User> getLimit(Map<String, Object> map);
<!--测试实现-->
// 分页
@Test
public void getLimit() {
SqlSession sqlSession = Utils.getSqlSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
Map<String, Object> map = new HashMap<String, Object>();
Object startIndex = map.put("startIndex", 2);
Object pageSize = map.put("pageSize", 2);
List<User> limit = mapper.getLimit(map);
for (User user : limit) {
System.out.println(user);
}
sqlSession.close();
}
- 使用RowBounds来实现分页
PS:看这篇文章吧~~~~如果选择了这个方式,难免会在被问一些原理之内的。