edge-tts是github上高赞的开源文本合成语音TTS项目,通过调用微软edge的在线语音合成服务,支持40多种语言和318种声音;尤其中文方面,不仅支持普通话而且还支持地方口音,效果可以说是吊打ChatTTS。
edge-tts语音合成搭建教程(https://github.com/rany2/edge-tts)
安装对应的环境
!pip install edge-tts
!pip install torchaudio
import edge_tts
print("edge_tts:", edge_tts.__version__)
查看edge-tts支持的语言
!edge-tts --list-voices # 查看其支持的所有声音
基于命令行端-来生成语音教程
合成对应的香港话、粤语语音-效果展示
获得支持的香港话、粤语语音明细
!edge-tts --list-voices| grep HK # TW
Name: en-HK-SamNeural
Name: en-HK-YanNeural
Name: zh-HK-HiuGaaiNeural
Name: zh-HK-HiuMaanNeural
Name: zh-HK-WanLungNeural
通过命令行(Window输入cmd)合成生成粤语语言效果
!edge-tts --voice zh-HK-WanLungNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
运行的效果展示: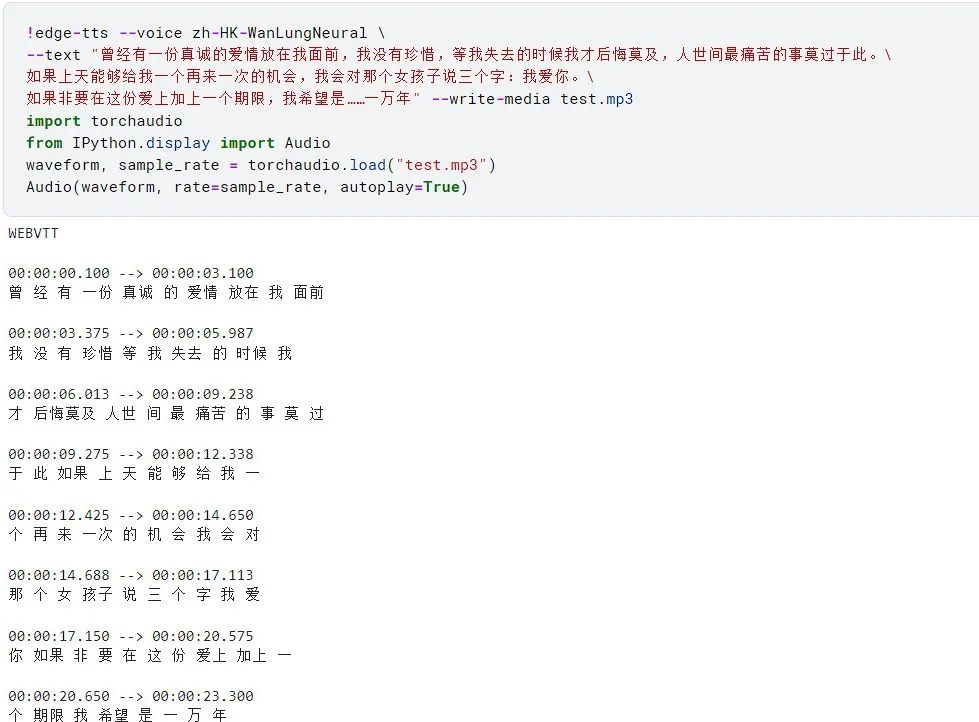
语音效果如下:
合成对应陕西方言语音-效果展示
!edge-tts --list-voices |grep CN# 查看其支持的中国话
Name: zh-CN-XiaoxiaoNeural
Name: zh-CN-XiaoyiNeural
Name: zh-CN-YunjianNeural
Name: zh-CN-YunxiNeural
Name: zh-CN-YunxiaNeural
Name: zh-CN-YunyangNeural
Name: zh-CN-liaoning-XiaobeiNeural
Name: zh-CN-shaanxi-XiaoniNeural
命令行合成生成对应的陕西方言语音
!edge-tts --voice zh-CN-shaanxi-XiaoniNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
合成对应男语音-效果展示
!edge-tts --voice zh-CN-YunyangNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
合成对应台湾口音-效果展示
获得支持的台湾语音明细
!edge-tts --list-voices| grep TW
Name: zh-TW-HsiaoChenNeural
Name: zh-TW-HsiaoYuNeural
Name: zh-TW-YunJheNeural
合成对应台湾语音
!edge-tts --voice zh-TW-YunJheNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
调整合成语音的语速--rate参数
通过rate参数来设置播放的语速快慢,-30%表示语速变慢30%,+30%表示语速增加30%。
!edge-tts --rate=-30% --voice zh-HK-WanLungNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
调整合成语音的音量--volume
通过--volume参数来设置播放的语速快慢,-60%表示语速变慢60%,+60%表示语速增加60%。
!edge-tts --volume=-50% --voice zh-HK-WanLungNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
调整合成语音的频率--pitch
通过pitch参数来调整合成语音的频率
!edge-tts --pitch=-50Hz --voice zh-HK-WanLungNeural \
--text "曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。\
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。\
如果非要在这份爱上加上一个期限,我希望是......一万年" --write-media test.mp3
import torchaudio
from IPython.display import Audio
waveform, sample_rate = torchaudio.load("test.mp3")
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
基于python代码-来合成语音
import asyncio
import edge_tts
import torchaudio
from IPython.display import Audio
TEXT = """曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候我才后悔莫及,人世间最痛苦的事莫过于此。
如果上天能够给我一个再来一次的机会,我会对那个女孩子说三个字:我爱你。如果非要在这份爱上加上一个期限,我希望是......一万年"""
VOICE = "zh-HK-HiuGaaiNeural" #选择对应的声音
OUTPUT_FILE = "test.mp3"
communicate = edge_tts.Communicate(TEXT,
VOICE,
rate='+0%',
volume= '+0%',
pitch= '+50Hz')
communicate.save_sync(OUTPUT_FILE)
waveform, sample_rate = torchaudio.load(OUTPUT_FILE)
Audio(waveform, rate=sample_rate, autoplay=True)
语音效果如下:
? 文章末尾,惊喜连连 ?
亲爱的读者们,如果这篇文章让你有所收获,或者仅仅是让你的嘴角上扬,那就不要吝啬你的手指,轻轻一点,给予我们一个小小的赞?。你的每一次点赞,都是对我们最大的鼓励和支持!
而且,别忘了点击"在看",让你的朋友们也能享受到这份知识和乐趣。毕竟,好东西要分享,不是吗??
我们下期再见,期待你的持续关注和互动!?
?往期文章 ?
【Ai技巧】新思路让Kimi不再"一根筋",轻松生成高效提示词!(附实战案例和提示词)
利用剪映+Midjourney+Dreamina5步完美复刻10W+点击量的高质量视频(含完整的攻略)
Kimi+腾讯元宝强强联手:五步拆解10w+公众号文章(附提示词)
22款免费AI神器:一键抠图、换脸、换装、换背景,让你秒变魔术大师
全网第一个利用kimi+字节扣子实现小红书治愈图文制作与发布自动化的免费AI工具(含完整攻略)
【新热点】10分钟如何利用kimi+通义+即梦+剪映快速制作抖音高点击、高质量创意美食怪兽爆款视频(含完整的实战步骤)
10分钟快速掌握利用天工AI+度加剪辑5步免费打造高质量、高点击的《玫瑰的故事》Rap影视解说全攻略