51工具盒子
依楼听风雨
笑看云卷云舒,淡观潮起潮落
网站首页
Chrome插件
网站导航
在线工具
爱白嫖
人工智能
开发笔记
软件教程
网赚思路
关注本站
RSS订阅
十亿
上一页
下一页
热门文章
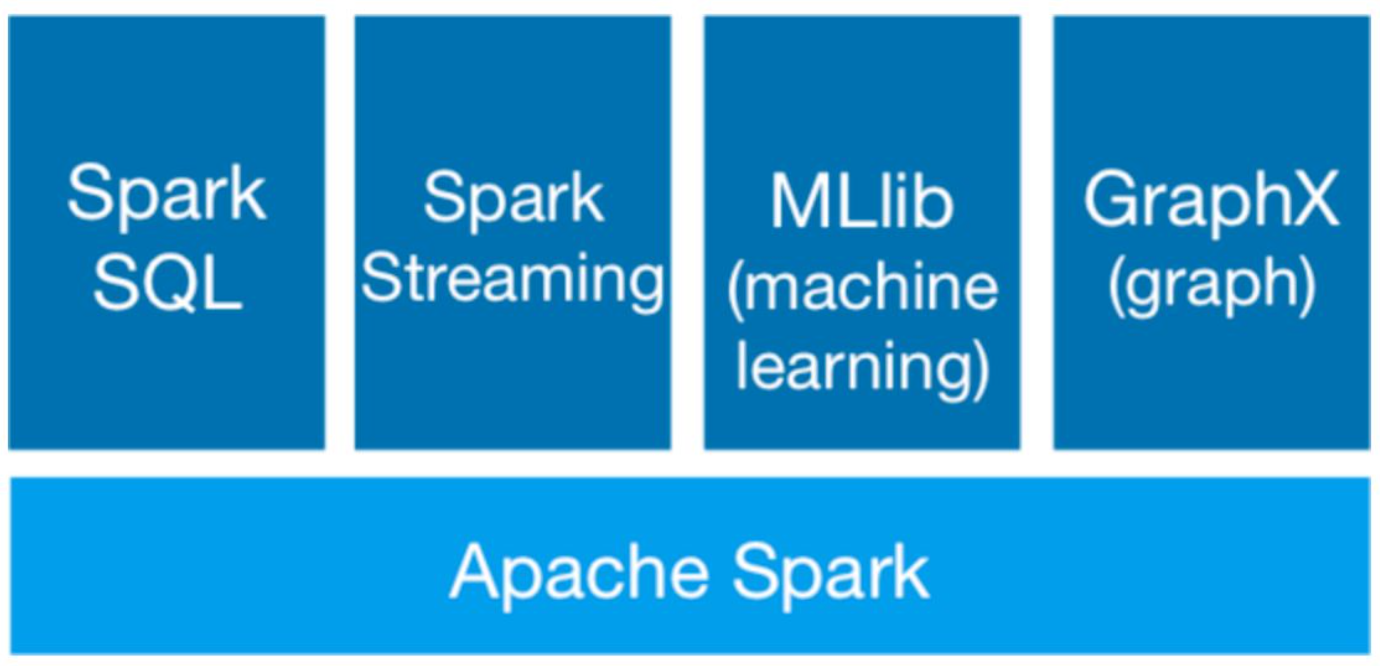
十亿条数据需要每天计算怎么办?Spark快速入门
2024-10-26
猜你喜欢
十亿条数据需要每天计算怎么办?Spark快速入门
2024-10-26
快捷分类
云服务器
日常运维
在线免费
开源工具
科学上网
开发笔记
区块链
白嫖帮
新视野
人工智能
网赚思路
Python笔记
Php笔记
Java笔记
链知识
币知识
IOS笔记
Android笔记
Mysql
C语言笔记
前端开发
R笔记
Go笔记
mybatis笔记
Golang笔记
数据库
市场营销
软件教程
vps
Rust笔记
软件使用
经验分享
Stable Diffusion
chatgpt
Midjourney
操作系统
Photoscape
加密货币
挖矿
Coze
Meta
网络安全
网络运营
开源软件
Github
ComfyUI
数字人
Docker笔记
Claude
Oracle
web3
linux
windows
mac
redis
git笔记
nginx
kafka
maven
spring
RocketMQ
Zabbix
ubuntu
centos
kubesphere
ffmpeg
jenkins
hbase
JavaScript笔记
WordPress
nginx
Hadoop
vuejs
mongo
SQL Server
PostgreSQL
SQLite
ElasticSearch
Spark
netty
zookeeper
RabbitMQ
ClickHoust
cocos2d
gradle
tomcat
Markdown
MinIO
react
Hexo
git
intellij idea
android studio
svn
C++
spdlog
nodejs
C
WordPress
宝塔面板
vim
shell
logstash
软件渗透
NeoDB
CSS3
HTML
Lua笔记
数据算法
嵌入式
debian
红帽RHEL
Neo4j
jquery
nas
1panel
aapanel
浏览器
谷歌
.net
微信
telegram
Cloudflare
大数据
rust
layui
JumpServer
DataEase
TiDB
DM数据库
虚拟机
elk
sqlmap
nacos
Firefox
C#
Swagger
Foxmail
navicat
DeepSeek
 51工具盒子
51工具盒子