Redis Set原理分析
大家好,我是猿java。 在 Redis中,**Set(集合)**以其独特的特性和高效的操作模式,在实际应用中得到了广泛的使用。本文将深入分析 Redis Set 的原理、源码实现,并通过示例展示其在实际应用中的使用方式。 1 什么是 Redis Set? {#1-什么是-Redis-Set} =================================== 在 R...
大家好,我是猿java。 在 Redis中,**Set(集合)**以其独特的特性和高效的操作模式,在实际应用中得到了广泛的使用。本文将深入分析 Redis Set 的原理、源码实现,并通过示例展示其在实际应用中的使用方式。 1 什么是 Redis Set? {#1-什么是-Redis-Set} =================================== 在 R...
大家好,我是猿java。 这篇文章,我们将从 Redis List 的基本原理出发,深入分析其内部实现机制、源码层面的细节,并结合实际示例,全面解析 Redis List 的工作原理。 1. Redis List 概述 {#1-Redis-List-概述} =================================== Redis 的 List 是一个简单的字符串...
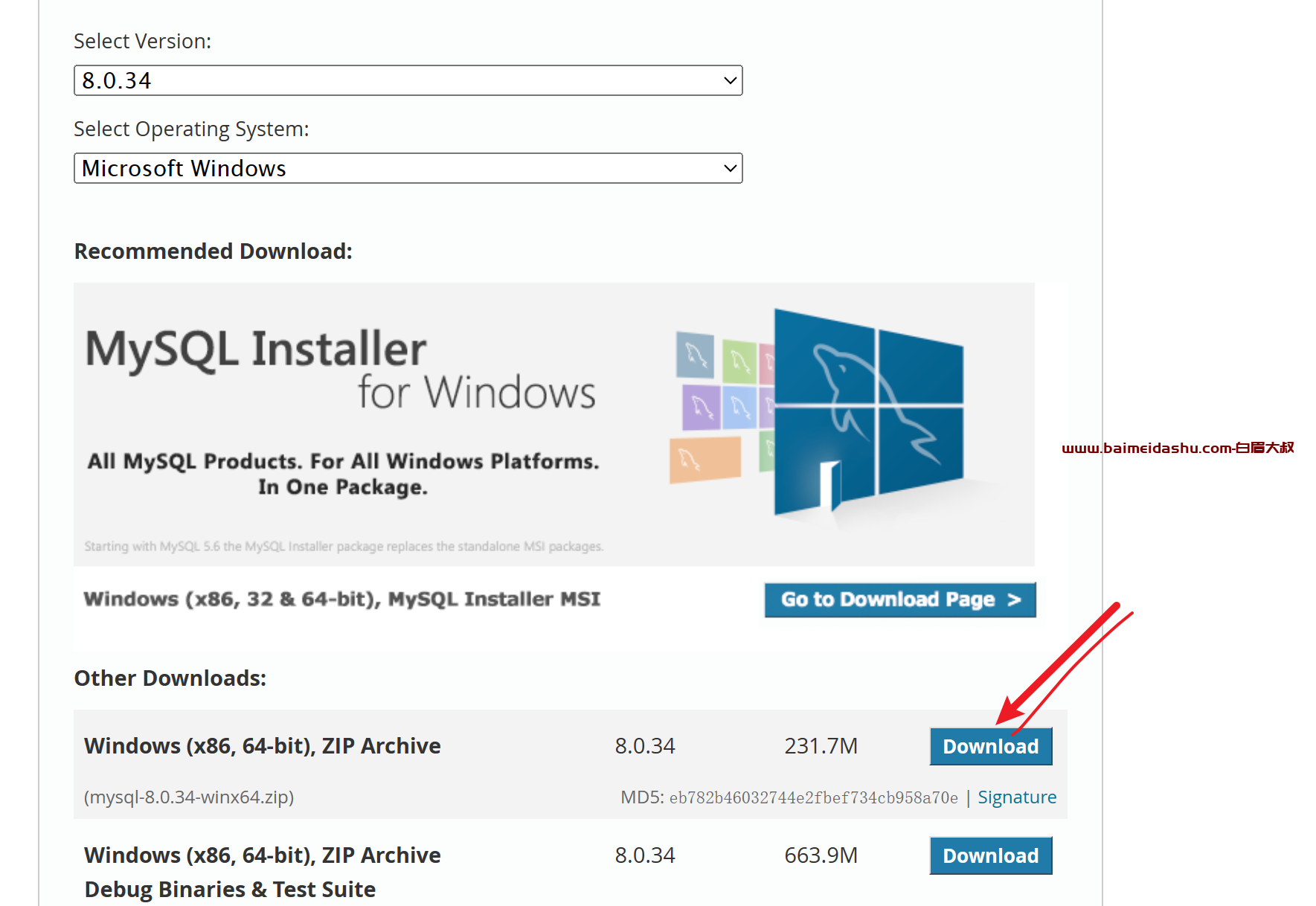
Ubuntu 16.04.4 LTS PHP 7.0.30-0ubuntu0.16.04.1 (fpm-fcgi) nginx version: nginx/1.12.2 **安装 Redis** ``` $ apt install redis-server ``` **修改配置文件** ``` $ vim /etc/redis/redis.con...

> 令她反感的,远不是世界的丑陋,而是这个世界所戴的漂亮面具。------《不能承受的生命之轻》 代码如下: |------------------------------------------------------------------------------------------------------------------------|--------...
一、前言 {#一、前言} ------------ flex 是 flexible Box 的缩写,意为**弹性布局**,用来为盒状模型提供最大的灵活性,任何一个容器都可以指定 flex 布局。 二、布局原理 {#二、布局原理} ---------------- 采用 flex 布局的元素成为 flex 容器。其所有子元素会自动成为容器成员,成为 flex 项目。 通过...
一、前言 {#一、前言} ------------ flex 是 flexible Box 的缩写,意为**弹性布局**,用来为盒状模型提供最大的灵活性,任何一个容器都可以指定 flex 布局。 二、布局原理 {#二、布局原理} ---------------- 采用 flex 布局的元素成为 flex 容器。其所有子元素会自动成为容器成员,成为 flex 项目。 通过...

#### 一、Nginx简介 Nginx(发音为 "Engine-X")是一个高性能的Web服务器、反向代理服务器、负载均衡器和HTTP缓存。它最初由Igor Sysoev开发,并于2004年发布,迅速成为全球最受欢迎的Web服务器之一。Nginx以其高性能、轻量级和低资源消耗著称,尤其适用于处理大量并发连接。 # 默认的index效果图 ...
Nginx 的访问日志中蕴含丰富的信息,然而直接阅读对于大多数人来说是一项艰巨的任务。但我们有 GoAccess 这样的强大工具,它能够帮助我们轻松地分析和可视化 Nginx 的访问日志。 工具安装 {#工具安装} ------------ 对于基于 Debian 的系统「如 Ubuntu」,可以使用以下命令安装: |-------------|-----------...
在当今数字化时代,网站流量分析对于理解用户行为、优化网站性能以及制定营销策略至关重要。本文将探讨如何通过分析 Nginx 的 access_log 获取网站流量的多维度数据,并给出具体操作步骤和分析方法。 日志格式 {#日志格式} ------------ 在开始分析前,我们需要了解 access_log 的默认日志格式。通常情况 access_log 的日志格式如下:...
Nginx监控 {#articleContentId} =========================== [Nginx监控-CSDN博客](https://blog.csdn.net/qq1271566323/article/details/142418625)