—Bodisparking恶意代码")
WireShark黑客发现之旅(3)—Bodisparking恶意代码
<h1>0x00 发现</h1> <hr /> <p>接到客户需求,对其互联网办公区域主机安全分析。在对某一台主机通信数据进行分析时,过滤了一下HTTP协议。</p> <p><img src="http://static.51tbox.com/static/2024-12-23/col/32...
<h1>0x00 发现</h1> <hr /> <p>接到客户需求,对其互联网办公区域主机安全分析。在对某一台主机通信数据进行分析时,过滤了一下HTTP协议。</p> <p><img src="http://static.51tbox.com/static/2024-12-23/col/32...
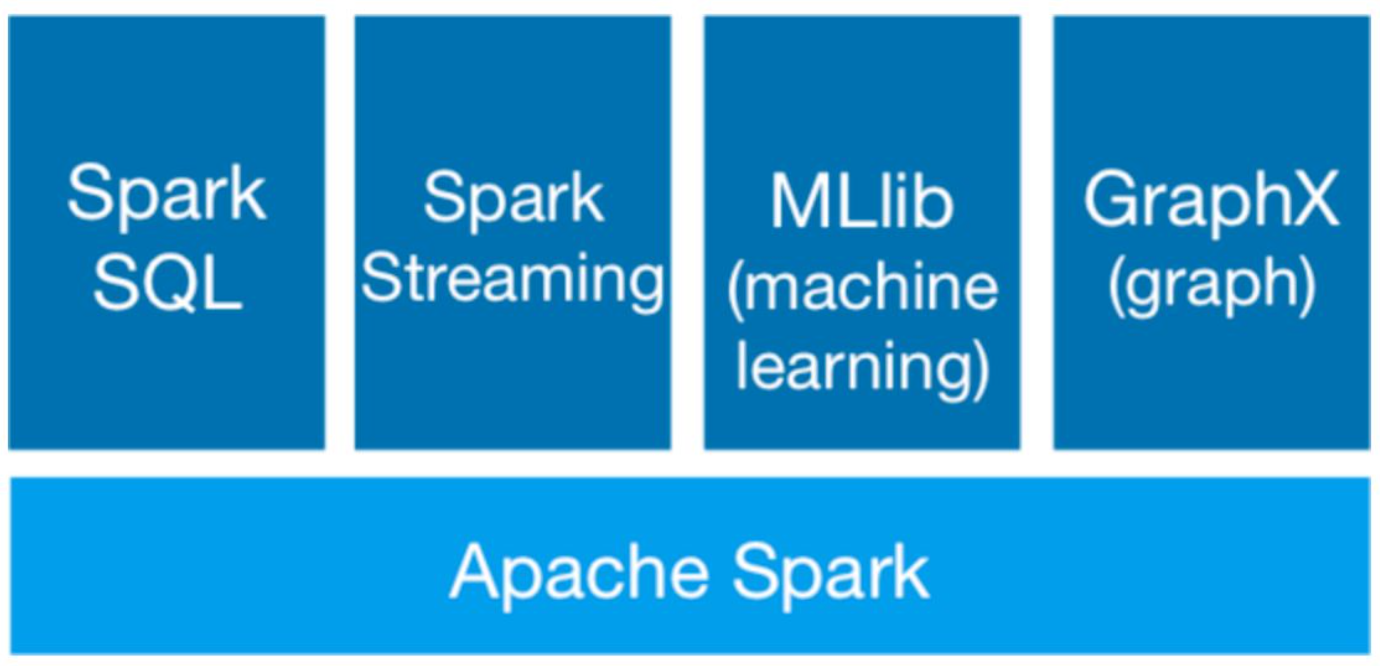
<p>Spark SQL允许大家在Python、Java以及Scala中使用数据帧;利用多种结构化格式读取并写入数据;通过SQL进行大数据查询。</p> <p>Spark SQL属于Spark用于处理结构化与半结构化数据的接口。结构化数据是指那些拥有一定模式的数据,包括JSON、Hive Tables以及Parquet。模式意味着每条记录都拥...
<p>1月才刚释出1.6版的大数据技术Spark,下一个2.0版本预计4、5月释出,将提供可运行在SQL/Dataframe上的结构化串流即时引擎,并统一化Dataset及DataFrame</p> <br /> <p><img src="http://static.51tbox.com/static/2024-1...

<p>有些时候我们想从 DQYDJ 网站的数据中分析点有用的东西出来,在过去,我们要<a href="https://dqydj.com/how-to-import-fixed-width-data-into-a-spreadsheet-via-r-playing-with-ipums-cps-data/">用 R 语言提取固定宽度的...

<blockquote> <p>Spark SQL 是 Spark 生态系统中处理结构化格式数据的模块。它在内部使用 Spark Core API 进行处理,但对用户的使用进行了抽象。这篇文章深入浅出地告诉你 Spark SQL 3.x 的新内容。</p> </blockquote> <p>有了 Spark SQL,用...
spark 丢失临时文件问题 HHH 日志改造问题 背景 目前 HHH 日志初筛程序由于 RPC 处理时间过长,需要优化改造成 SparkStreaming 处理; 同时,HHH 日志解析后续 DP、DK、DEL 表生成同样适用MR 处理,浪费大量资源,可改造合并到 Spark Streaming 中一块处理。但在合并初筛、HHH 日志解析、DP、DK、DEL 时,碰到...
英文: How to transform in DataFrame in PySpark? 问题 {#heading} ============= 以下是翻译好的部分: 我在 Py Spark 中有一个数据框,其中包含列:id、name、value。 列名应为每个id取值`A、B、C`。value列包含数值。 样本数据框: dat...
英文: How to get Parquet row groups stats sorted across multiple files with Pyspark? 问题 {#heading} ============= 你可以尝试使用`repartition`方法来改变数据分区的分布,从而达到你想要的效果。例如: df = df.repartition(2...
英文: How to create a Spark UDF that returns a Tuple or updates two columns at the same time? 问题 {#heading} ============= Here's the modified code with the necessary changes to fix th...
英文: Write to Iceberg/Glue table from local PySpark session 问题 {#heading} ============= 我想要能够从我的本地机器使用Python操作托管在AWS Glue上的Iceberg表(读/写)。 我已经完成了以下工作: * 创建了一个Iceberg表并在AWS Glue上注册了它 * 使...