评论(0)
16 )
在 Apache OpenMeetings(一个流行的视频会议和在线协作开源平台)中发现了一个严重的安全漏洞(CVE-2024-54676,CVSS 9.8)。攻击者可利用该漏洞在易受攻击的系统上执行任意代码,从而可能泄露敏感数据并中断服务。
该漏洞源于 OpenMeetings 群集模式中对不信任数据的不安全反序列化。这一问题的产生是由于 OpenMeetings 使用的 ...
评论(0)
16 )
DataEase 项目就影响其流行的开源 BI 工具的一个关键漏洞(CVE-2024-56511)发布了紧急公告。 该漏洞在 CVSSv4 评级中被评为 9.3 级,可绕过身份验证机制,在未经授权的情况下访问敏感数据。
DataEase 是一款广泛使用的商业智能工具,可帮助用户轻松分析数据并获得可行的见解。 它的拖放界面、对不同数据源的支持以及无缝图表共享功能使其成为企业优化...
评论(0)
16 )
来自 Atheos 项目的安全公告披露了一个关键漏洞 (CVE-2025-22152),该漏洞可能会危及运行基于 Web 的 IDE 框架的服务器。这个路径遍历漏洞的 CVSSv4 得分为 9.4,它使用户面临重大风险,包括未经授权的文件访问、远程代码执行和任意文件上传。
Atheos 是轻量级网络集成开发环境(IDE)Codiad 的一个现代化分叉,并得到了积极维护。该平台...
评论(0)
14 )
最近,安全研究人员 @wh1te4ever 揭示了一个针对 CVE-2024-54498 的概念验证(PoC)漏洞,该漏洞允许应用程序逃离 macOS 沙盒的限制。发布在 GitHub 上的 PoC 演示了恶意行为者如何利用这个漏洞未经授权访问敏感的用户数据。
macOS 沙盒是一项重要的安全功能,它限制应用程序访问或修改指定区域之外的文件和资源。这一保护措施可以防止恶意软件...
评论(0)
20 )
前言
---
前段时间看到普元 EOS Platform 爆了这个洞,Apache James,Kafka-UI 都爆了这几个洞,所以决定系统来学习一下这个漏洞点。
JMX 基础
------
### JMX 前置知识
JMX(Java Management Extensions,即 Java 管理扩展)是一个为应用程序、设备、系统等植入管理功能的框架。JMX 可以跨越...
评论(0)
15 )
网络安全和基础设施安全局(CISA)就恶意行为者正在积极利用的两个关键安全漏洞发出紧急警告。这些漏洞影响了BeyondTrust的特权访问管理软件和Qlik Sense Enterprise for Windows,给各行各业的组织带来了重大风险。
CVE-2024-12686影响BeyondTrust的特权远程访问(PRA)和远程支持(RS)解决方案,这些解决方案被政府机构...
评论(0)
12 )
Patchstack 的安全研究员拉菲-穆罕默德(Rafie Muhammad)在最近的一份安全公告中发现了 Fancy Product Designer 插件中的关键漏洞。该插件由 Radykal 开发,销量已超过 20,000 件,以允许用户自由设计和个性化产品而闻名。然而,由于发现了严重的安全漏洞,数千个 WordPress 网站面临风险。
Fancy Product ...
评论(0)
15 )
网络安全研究人员详细介绍了一个现已打补丁的安全漏洞,该漏洞影响三星智能手机上的 Monkey's Audio (APE) 解码器,可能导致代码执行。
该高严重性漏洞被追踪为 CVE-2024-49415(CVSS 得分:8.1),影响运行 Android 12、13 和 14 版本的三星设备。
"SMR Dec-2024 Release 1之前的libsa...
评论(0)
15 )
在这里分享一下通过拖取 DataCube 代码审计后发现的一些漏洞,包括前台的文件上传,信息泄露出账号密码,后台的文件上传。当然还有部分 SQL 注入漏洞,因为 DataCube 采用的是 SQLite 的数据库,所以SQL 注入相对来说显得就很鸡肋。当然可能还有没有发现的漏洞,可以互相讨论。
phpinfo 泄露
----------

17 )
如果您是使用 SimpleHelp 满足远程 IT 支持/访问需求的组织,则应立即更新或修补服务器安装,以修复可能被远程攻击者利用在底层主机上执行代码的安全漏洞。
**漏洞**
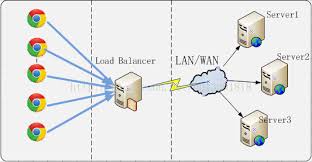
SimpleHelp 是一款比较流行的远程支持/访问软件,偶尔也会被网络攻击者利用。
技术服务公司和组织的 IT 服务台和技术支持团队大多使用该解决方案。它使用 Java 运行时环境来运行服务器和...
")