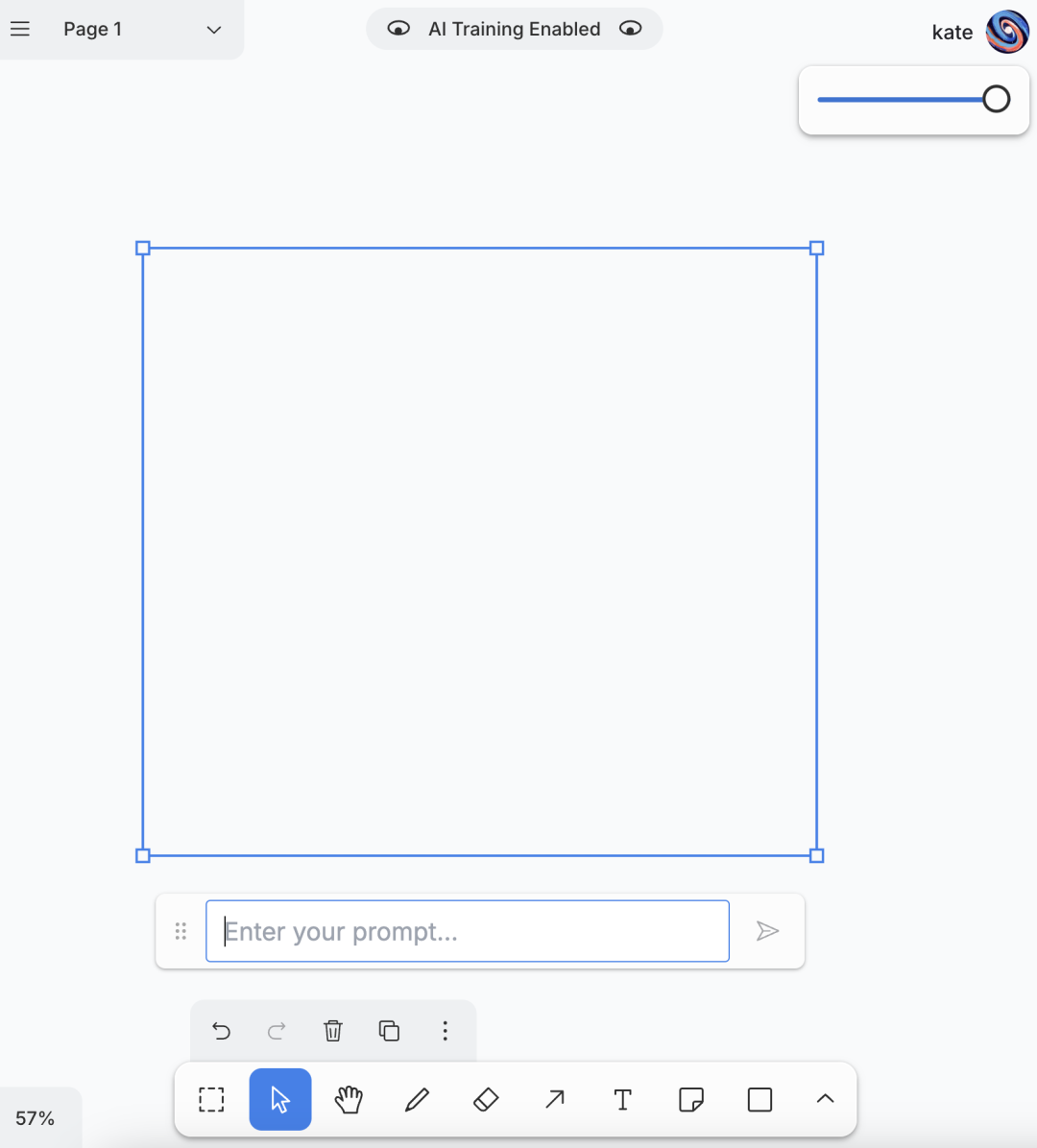
经典怀旧Windows自带画图工具,在线体验版
刚接触电脑的时候,电脑上的画图程序没少玩,界面的样子至今也没有忘。现在推荐一款重现经典画图程序的网站。 **JS Paint:<https://jspaint.app/>** 这款在线画图程序和早期的Windows上的几乎一样,支持导出png、jpg、bmp、webp等文件格式。 [](http://static.51t...
Sublime Text一款流行的代码编辑器软件,HTML、PHP、CSS、Javascript等等格式文件编辑。这里就不做过多介绍了。 [](htt...
1.首先在群晖后台套件中心安装"**Virtual Machine Manager**"。 [](http...
EditPlus是一款由韩国 Sangil Kim出品的小巧但是功能强大的文本编辑器,小伙伴们可以使用EditPlus完成所有你想要的文本编辑功能。EditPlus也是一款非常好用的HTML编辑器,可支持C、C++、Perl、Java,EditPlus软件中有内建完整的HTML \& CSS1 指令功能。 [ 0x00 文件操作函数 {#menu_index_1} =========================== [ZwDeleteFile](https://learn.micros...
问题如下 {#%E9%97%AE%E9%A2%98%E5%A6%82%E4%B8%8B} -------------------------------------------- 连接局域网共享的标签打印机提示错误代码0x00000709 <br />