
如何导入超大的sql文件到Mysql
#### 如何从sql文件导入到Mysql {#如何从sql文件导入到Mysql} *** ** * ** *** 你可以使用如下命令将sql导入到Mysql: |-----------|---------------------------------------| | ``` 1 ``` | ``` mysql -u 用户名 -p 数据库名 < 文件.sql `...
#### 如何从sql文件导入到Mysql {#如何从sql文件导入到Mysql} *** ** * ** *** 你可以使用如下命令将sql导入到Mysql: |-----------|---------------------------------------| | ``` 1 ``` | ``` mysql -u 用户名 -p 数据库名 < 文件.sql `...
<p><strong>查出重复的type</strong></p> <pre><code>SELECT type FROM table GROUP BY type HAVING count(type) > 1; </code></pre> <p><st...

<p>我们在远程电脑管理数据库时经常遇到这样的问题<br /> <img src="http://static.51tbox.com/static/2024-12-14/col/df4497985bf9b6f9a63f3ad8c2aa6645/a64019e1391846f6a3a4868f96442e07.png.jpg" a...

spark 丢失临时文件问题 HHH 日志改造问题 背景 目前 HHH 日志初筛程序由于 RPC 处理时间过长,需要优化改造成 SparkStreaming 处理; 同时,HHH 日志解析后续 DP、DK、DEL 表生成同样适用MR 处理,浪费大量资源,可改造合并到 Spark Streaming 中一块处理。但在合并初筛、HHH 日志解析、DP、DK、DEL 时,碰到...
英文: How to transform in DataFrame in PySpark? 问题 {#heading} ============= 以下是翻译好的部分: 我在 Py Spark 中有一个数据框,其中包含列:id、name、value。 列名应为每个id取值`A、B、C`。value列包含数值。 样本数据框: dat...
英文: Add new timestamp column with interval in dataframe in pyspark 问题 {#heading} ============= 我正在使用PySpark,并且有一个Spark数据框。我想要添加一个新列"timestamp interval",间隔为15分钟。请问有人可以帮忙吗? 我的数...
英文: How to get Parquet row groups stats sorted across multiple files with Pyspark? 问题 {#heading} ============= 你可以尝试使用`repartition`方法来改变数据分区的分布,从而达到你想要的效果。例如: df = df.repartition(2...
英文: How to create a Spark UDF that returns a Tuple or updates two columns at the same time? 问题 {#heading} ============= Here's the modified code with the necessary changes to fix th...
英文: Write to Iceberg/Glue table from local PySpark session 问题 {#heading} ============= 我想要能够从我的本地机器使用Python操作托管在AWS Glue上的Iceberg表(读/写)。 我已经完成了以下工作: * 创建了一个Iceberg表并在AWS Glue上注册了它 * 使...
<p>英文:</p> <p>PySpark using OR operator in filter</p> <h1>问题 {#heading}</h1> <p>这个过滤器有效:</p> <p><code>raw_df_2 = raw_df_1.filter(a...

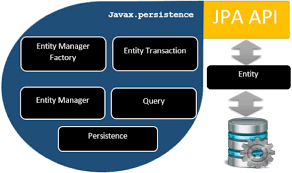



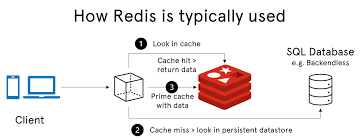
![NestJS[四]-数据库](https://img1.51tbox.com/static/2024-12-19/bToBijCIqcRg.png)