简介:
伪本地化 HTML 网页。
更新包括许多错误修复以及现在起诉日本数字的改进填充。
源代码现已在 github (https://github.com/eirikRude/pseudolocalizer) 中提供
伪本地化是本地化和国际化工程师的重要工具。伪本地化的目标是提供一个仍然可用的界面,同时突出显示应用程序本地化时出现的一些常见问题。
一些伪定位尝试测试的领域是:
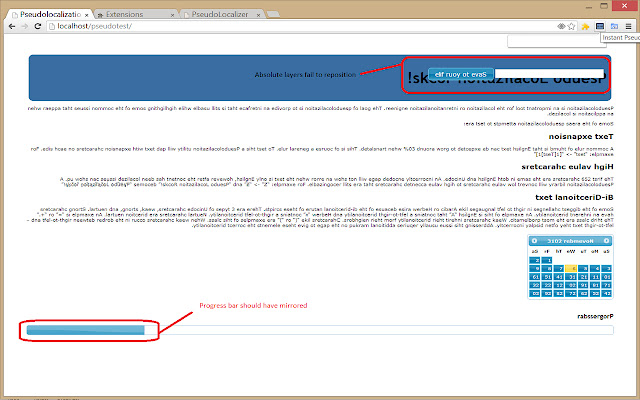
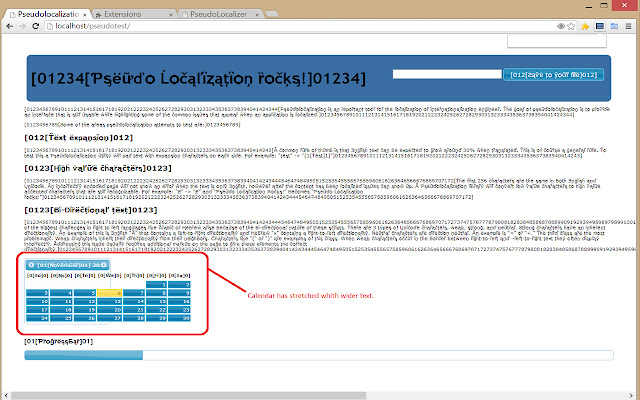
●文本扩展
●●一个普遍的经验法则是,英文文本在翻译后预计会增长 30% 左右。这当然是一般规则。为了测试这一点,伪本地化实用程序将在每一侧使用扩展字符填充文本。例如:"测试"->"[1[测试]1]"
●高价值字符
●●前256 个字符在许多ASCII 和Unicode 中是相同的。当文本仅为英文时,错误编码的页面不会显示错误,但是在内容本地化后可能会出现问题。伪本地化库会将低值字符转换为仍可识别的高值重音字符。例如:"Z"->"Ƶ"和"伪本地化摇滚!"变成"Ƥᶊëữďѻ Ĺѻčąľἳȥąțἳѻņ ȑѻčķᶊ!"
●双向文本
●●从右到左的语言(如阿拉伯语或希伯来语)中的一些最大挑战是由于这些脚本的双向性质而出现的。 Unicode 字符有 3 种类型,弱、强和中性。强大的角色具有内在的方向性。例如,英语"A"包含从左到右的方向性,希伯来语"א"包含从右到左的方向性。中性字符是方向中性的。一个例子是"="或"+"。第三类是最有问题的。弱角色从他们的邻居那里继承他们的方向性。像"("或")"这样的字符就是这个类的例子。当弱字符出现在从右到左和从左到右文本之间的边界时,它们通常会显示不正确。解决这个问题通常需要在页面上添加额外的标记来为这些元素提供正确的方向性。
限制:
伪本地化通常作为提取资源文件的本地化过程的一部分执行。然后在构建时或通过运行时的机制将它们合并到应用程序中。此扩展的目标是提供一种快速简便的方法来在流程的早期以较少的要求测试页面上的基本伪本地化。它不是为替换资源文件的伪本地化而设计的。它应该被视为另一种扩大覆盖范围的工具。
资源文件的伪本地化发现的一个常见的本地化错误是文本的连接。由于伪定位发生在呈现的文本后连接上,因此此扩展将无助于检测连接。
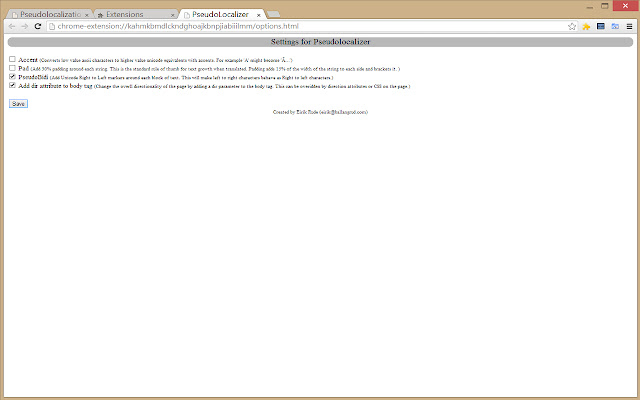
该扩展仅适用于 HTML 页面。方向性设置仅更改主体目录属性。除了 <body> 之外,它不会修改 CSS 或 HTML 标记中指定的方向性。这可能会在未来的版本中得到增强。
插件下载: