简介:
一种将基于网站的书籍或页面列表转换为 ePub 格式以在电子阅读器/Kindle 等设备上阅读的工具。
出版商
电子阅读器和 Kindle 的爱好者可以使用此工具从网站生成电子阅读器/Kindle 兼容文件以供日后阅读。
一个高度可定制的工具,允许您从目录页面中提取 html 页面列表,并将它们编译成 ePub 书籍,以导入到您选择的电子阅读器中。
对于可以编写 javascript 的高级用户,您可以添加额外的解析器定义来自定义任何站点的解析。
## 特征 ##
- 支持多章节小说(测试最多300章)
- 下载和嵌入图像
- 可以使用 shift-select 有选择地解析章节
- 使用 readability.js 自动捕捉主要内容
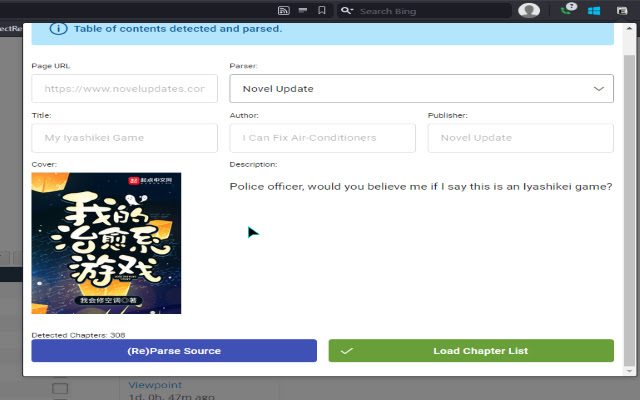
- 封面图片、作者、标题、描述是从某些站点自动解析的。
- 小说更新
- 目录和章节的可配置解析器
## 如何使用 ##
- 导航到目录页面
- 示例:https://www.novelupdates.com/series/<series>
- 对于 novelupdates.com,单击"显示所有章节"按钮以下载所有章节链接
- 打开弹出窗口,它应该自动尝试检测页面数据
- 点击"加载章节列表"
- 选择一些章节(或全部)
- 点击 `Extract Chapters`,如果一切正常,如果解析器工作正常,它应该显示 `Parsed`
- 单击"编译 Epub"以生成 ePub 作为下载
高级用户配置##
**警告:高级配置需要 javascript 知识**
### 概述 ###
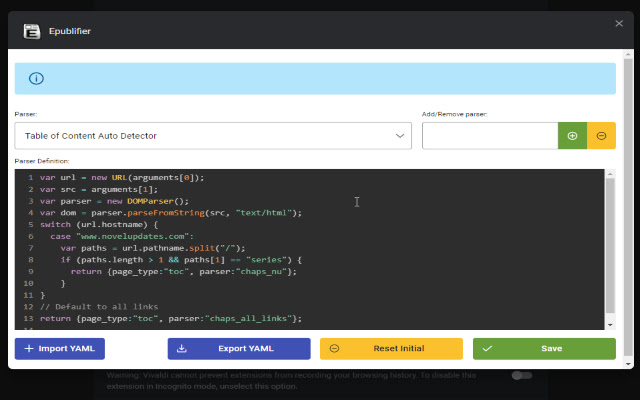
高级用户有四种配置:
- 目录自动检测器 - 根据页面源和 URL 更改要使用的目录解析器
- 目录解析器 - 实际上将 HTML 解析为章节 URL 列表或章节 html
- 章节类型自动检测器 - 根据页面源和 URL 检测使用哪种章节解析器
- Chapter Parser - 将章节 HTML 文本解析为纯文本 HTML 内容
配置解析器
您可以创建新的 YAML 解析器定义或修改现有的主要定义。
插件下载: