简介:
Web 数据提取工具,具有适用于现代 Web 的简单点击界面
免费且易于使用的网络数据提取工具,适用于所有人。
通过简单的点击界面,只需几分钟的爬虫设置就可以从网站中提取数千条记录。
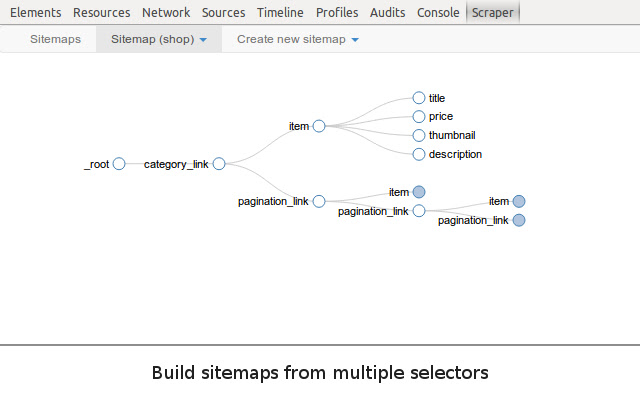
Web Scraper 使用由选择器组成的模块化结构,它指示爬虫如何遍历目标站点以及提取哪些数据。由于这种结构,从亚马逊、Tripadvisor、eBay 等现代动态网站以及鲜为人知的网站中挖掘数据变得毫不费力。
数据提取在您的浏览器上运行,不需要在您的计算机上安装任何东西。您不需要 Python、PHP 或 JavaScript 编码经验即可开始抓取。此外,可以在 Web Scraper Cloud 中完全自动化数据提取。
一旦数据被抓取,将其下载为 CSV 或 XLSX 文件,可以进一步导入到 Excel、Google 表格等中。
特征
Web Scraper 是一个简单的网络抓取工具,允许您使用许多高级功能来获取您正在寻找的确切信息。它提供以下功能:
* 从多个页面抓取数据;
* 多种数据提取类型(文本、图像、URL 等);
* 从动态页面抓取数据(JavaScript + AJAX,无限滚动);
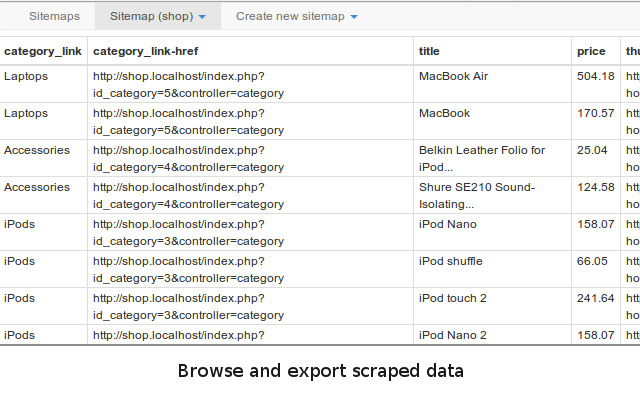
* 浏览抓取的数据;
* 将抓取的数据从网站导出到 Excel;
它只依赖于网络浏览器;因此,您无需额外的软件即可开始抓取。
如何开始抓取?
为了掌握网络抓取,您只需要学习几个步骤:
1.安装扩展并打开开发者工具中的Web Scraper选项卡(必须放在屏幕底部);
2.新建站点地图;
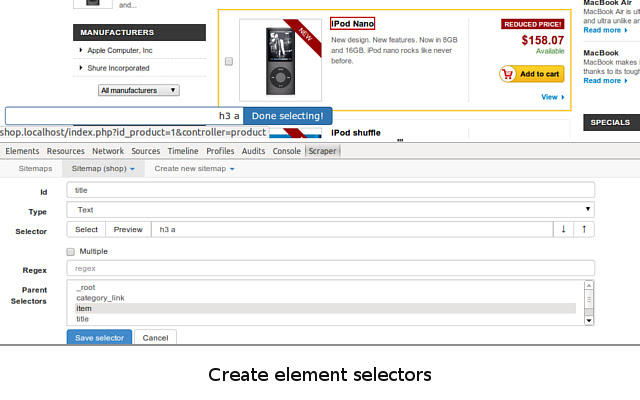
3.站点地图添加数据提取选择器;
4. 最后,启动爬虫并导出爬取的数据。
就这么简单!
Web Scraper 可以用来做什么?
* 潜在客户生成 - 电子邮件、电话号码、其他与各种网站的联系方式相关的数据挖掘;
* 电子商务 - 产品数据提取、产品价格抓取、描述、URL 提取、图像检索等;
* 网站内容爬取------从新闻门户、博客、论坛等中提取信息;
* 零售监控------监控产品性能、竞争对手或供应商库存和定价等;
* 品牌监测------产品评论、社交内容抓取进行情感分析;
* 商业智能------为关键业务决策收集数据,向竞争对手学习;
* 用于机器学习、营销、业务战略开发、研究的大数据提取;
* 以及更多。
Web 抓取一开始可能有点困难,这就是为什么我们创建了可以为您提供帮助的信息指南。
如需视频教程、文档、操作方法、游乐场网页和博客,请访问我们的网站:
https://www.webscraper.io/
如果您想讨论网络抓取、请求功能、提出问题或提交错误,请访问我们的友好论坛:
https://forum.webscraper.io/
关于我们产品的隐私政策,请参阅"浏览器扩展隐私政策" https://webscraper.io/extension-privacy-policy
感谢您选择我们!
插件下载: