大文件下载是我们开发中经常可以遇到的业务场景,如果直接将大文件(如一部高清的电影可能有5G)装载到内存中的方式下载,如下所示:
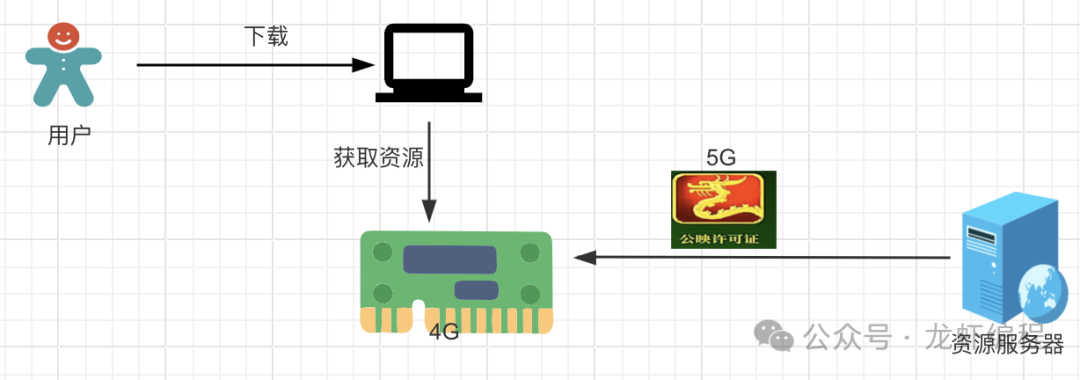
如果内存只有4G内存,此时资源就下载不下来,并且由于下载占用了大部分的内存资源进而整个服务因为内存不足不可用。那么有没有什么方案可以解决大文件下载的问题呢?下面介绍一种分片下载的方案。
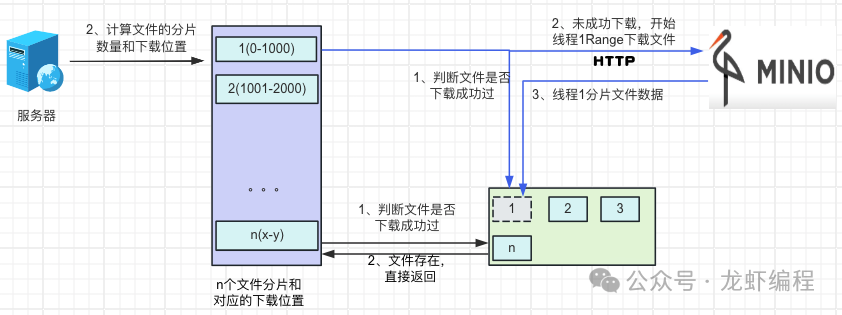
分片下载的核心思想是将服务器上的大文件拆分成若干个小文件,等这些小份文件都下载好了之后,最后将小文件合并成一个完整的大文件。如下图所示:
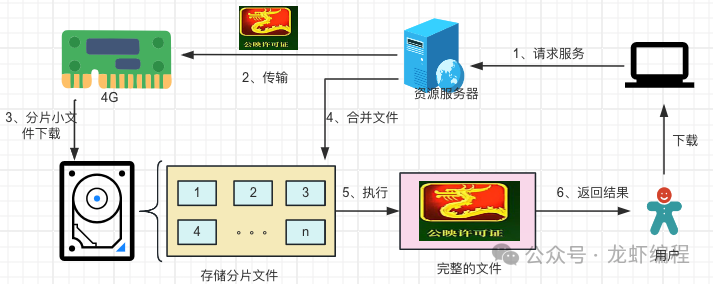
这里有个问题就是如何将一个大文件分成小文件(分片)下载呢?其实这个很简单,我们可以使用前端一个比较重要的请求首部------Range,它可以帮助我们实现分片下载。
1、认识Range
Range首部会告诉服务器返回文件哪一部分,同时它也支持一次性请求多个部分,服务器会以multipart文件的形式将结果返回。如果服务器返回的是范围响应的时候,服务器使用206状态码通知客户端,如果服务器发现请求不合法会使用416状态码通知客户端。下面列举几种常见的Range获取资源形式
(1)指定部分下载,下图的配置Range告诉服务器下载文件的0-1000字节的数据,

(2)指定多个部分下载,下图配置告诉服务器下载文件的--1000字节、1500-1900字节之间的数据。

(3)下载整个文件资源,配置如下图所示:

经过上面的分析,我们知道了可以使用request添加Range首部的方式可以实现分片获取文件资源。
2、大文件分片下载
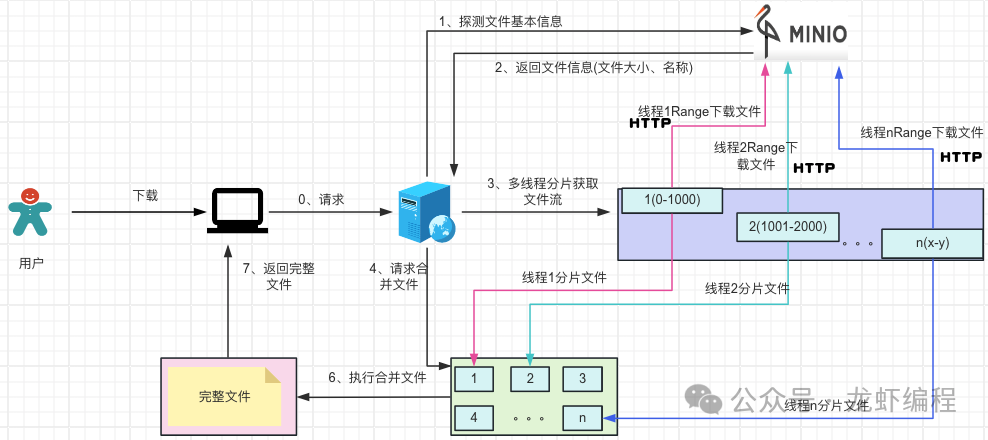
分片下载文件的核心流程:
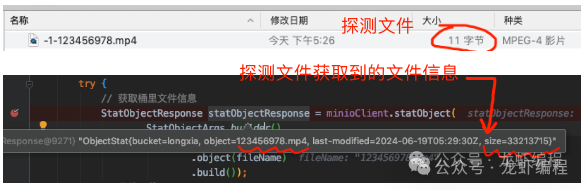
(1)后端先探测Minio上的文件。探测其实就是先下载文件的很小一部分数据(如Range设置成bytes=0-10)目的是用来获取文件的基本信息(如文件的大小、文件的名称、文件的唯一编码等等),如下图所示:
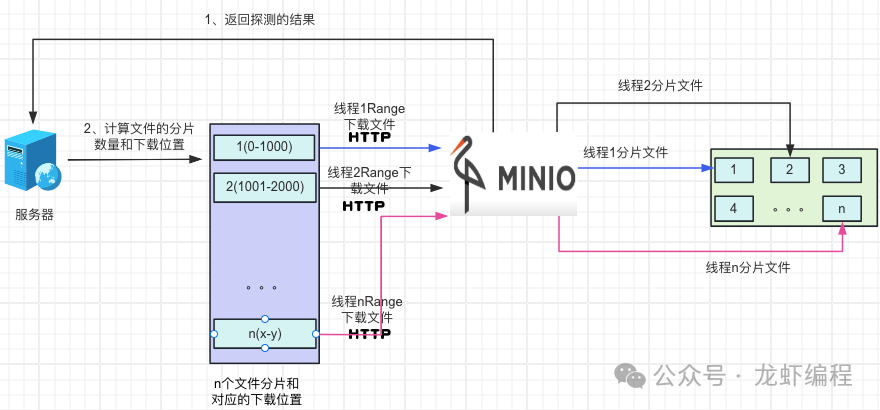
(2)拿到文件的基本信息后,后端设置每个分片的固定的大小,然后探测出来的根据文件的大小确定分片的数据量,开启和分片数量一致的线程通过http携带Range方式来获取分片文件的资源
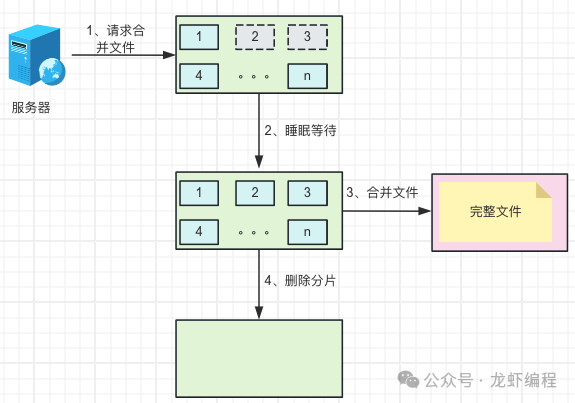
(3)待最后的一个文件下载结束后开始做合并文件的操作,由于是多线程下载文件资源,可能会出现在合并的时候,某些文件还没有下载好,此时需要让合并文件的线程睡眠一小段时间等待文件下载结束后再去合并文件资源。
通过上面的整体分片下载流程分析之后,下面实现这套流程。
3、分片下载具体的落地实现
现在采用分片下载的方式从Minio上下载指定的文件,文件如下:
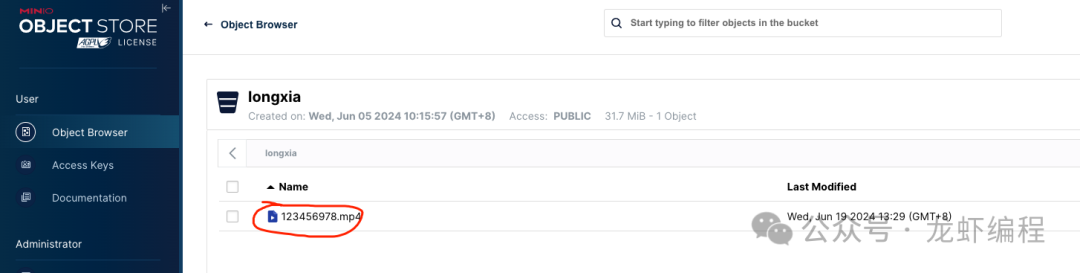
分片下载的搭建过程和代码如下:
(1)maven配置
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
<!--swagger--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.7.0</version> </dependency> <!--swagger ui--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger-ui</artifactId> <version>2.7.0</version> </dependency> <!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency>
<!--minio--> <dependency> <groupId>io.minio</groupId> <artifactId>minio</artifactId> <version>8.4.3</version> <exclusions> <exclusion> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> </exclusion> </exclusions> </dependency>
<dependency> <groupId>com.squareup.okhttp3</groupId> <artifactId>okhttp</artifactId> <version>4.8.1</version> </dependency>
<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.11</version> </dependency>
(2)Swagger配置 * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
@Configuration@EnableSwagger2public class SwaggerConfig { @Bean public Docket webApiConfig(){ //设置分片下载的swagger请求头 List<Parameter> operationParameters = Lists.newArrayList(); operationParameters.add(new ParameterBuilder(). name("Range"). description("Range"). modelRef(new ModelRef("string")). parameterType("header").defaultValue("bytes=0-").hidden(true).required(true).build());
return new Docket(DocumentationType.SWAGGER_2) .groupName("龙虾编程") .apiInfo(webApiInfo()) .select() //接口中由/admin /error就不显示 .paths(Predicates.not(PathSelectors.regex("/admin/.*"))) .paths(Predicates.not(PathSelectors.regex("/error.*"))) //扫描指定的包 .apis(RequestHandlerSelectors.basePackage("com.longxia")) .build() .globalOperationParameters(operationParameters); }
private ApiInfo webApiInfo(){ return new ApiInfoBuilder() .title("龙虾编程------分片下载") //swagger页面上大标题 .description("龙虾编程------分片下载") //描述 .version("1.0") .contact(new Contact("龙虾编程", "http://www.baidu.com", "1733150517@qq.com")) .build(); }
}
(3)Minio配置
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
yaml:------------------------yaml start------------------------#minio配置minio: access-key: 9ItcodDEOrXFYcxnKmFu secret-key: kxv4FFO3oMhzTEyPdkE24HKOAbudGdK2WJPAyvcl url: http://192.168.201.167:9002 #访问地址 bucket-name: longxia bucket-name-slice: slice-file ------------------------yaml end-------------------------------- Bean的配置: ------------------------bean配置 start------------------------@Configurationpublic class MinIOConfig {
@Value("${minio.url}") private String url;
@Value("${minio.access-key}") private String accessKey;
@Value("${minio.secret-key}") private String secretKey;
@Bean public MinioClient minioClient() { return MinioClient.builder() .endpoint(url) .credentials(accessKey, secretKey) .build(); }}
(1)文件的基本信息类
*
*
*
*
*
*
*
*
*
*
*
*
@Getterclass FileInfo { //文件的大小 private long fSize; //文件的名称 private String fName;
public FileInfo(long fSize, String fName) { this.fSize = fSize; this.fName = fName; } }
(2)下载单个分片文件去minio上下载 * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
@GetMapping("/singlePartFileDownload") public void singlePartFileDownload(@RequestParam("fileName")String fileName, HttpServletRequest request, HttpServletResponse response) throws Exception { InputStream is = null; OutputStream os = null; GetObjectResponse stream = null; try { // 获取桶里文件信息 StatObjectResponse statObjectResponse = minioClient.statObject( StatObjectArgs.builder() .bucket("longxia") .object(fileName) .build()); // 分片下载 long fSize = statObjectResponse.size();// 获取长度 response.setContentType("application/octet-stream"); fileName = URLEncoder.encode(fileName, utf8); response.addHeader("Content-Disposition", "attachment;filename=" + fileName); //根据前端传来的Range 判断支不支持分片下载 response.setHeader("Accept-Range", "bytes"); //文件大小 response.setHeader("fSize", String.valueOf(fSize)); //文件名称 response.setHeader("fName", fileName); response.setCharacterEncoding(utf8); // 定义下载的开始和结束位置 long startPos = 0; long lastPos = fSize - 1; //判断前端需不需要使用分片下载 if (null != request.getHeader("Range")) { response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT); String numRange = request.getHeader("Range").replaceAll("bytes=", ""); System.out.println("请求头:" + request.getHeader("Range")); String[] strRange = numRange.split("-"); if (strRange.length == 2) { startPos = Long.parseLong(strRange[0].trim()); lastPos = Long.parseLong(strRange[1].trim()); // 若结束字节超出文件大小 取文件大小 if (lastPos >= fSize - 1) { lastPos = fSize - 1; System.out.println("请求头last:"+ lastPos); } } else { // 若只给一个长度 开始位置一直到结束 startPos = Long.parseLong(numRange.replaceAll("-", "").trim()); } }
//要下载的长度 long rangeLenght = lastPos - startPos + 1; //组装断点下载基本信息 String contentRange = new StringBuffer("bytes").append(startPos).append("-").append(lastPos).append("/").append(fSize).toString(); response.setHeader("Content-Range", contentRange); response.setHeader("Content-Lenght", String.valueOf(rangeLenght)); os = new BufferedOutputStream(response.getOutputStream()); //minio上获取文件信息 stream = minioClient.getObject( GetObjectArgs.builder() .bucket(statObjectResponse.bucket()) //文件所在的桶 .object(statObjectResponse.object()) //文件的名称 .offset(startPos) //文件的开始位置 默认从0开始 .length(rangeLenght) //文件需要下载的长度 .build());
os = new BufferedOutputStream(response.getOutputStream()); //将读取的文件写入到OutputStream中 byte[] buffer = new byte[1024]; long bytesWritten = 0; int bytesRead = -1; while ((bytesRead = stream.read(buffer)) != -1) { //已经读取的长度和本次读取的长度之和是否大于需要读取的长度(实质就是判断是否最后一行) if (bytesWritten + bytesRead > rangeLenght) { os.write(buffer, 0, (int) (rangeLenght - bytesWritten)); break; } else { os.write(buffer, 0, bytesRead); bytesWritten += bytesRead; } } os.flush(); response.flushBuffer(); } finally { if (is != null) { is.close(); } if (os != null) { os.close(); } if(stream != null){ stream.close(); } } }
(3)保存单个分片的下载数据 * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
private FileInfo download(long start, long end, long page, String fName) throws Exception { // 断点下载 文件存在不需要下载 File file = new File(down_path, page + "-" + fName); // 探测必须放行 若下载分片只下载一半就需要重新下载 所以需要判断文件是否完整 if (file.exists() && page != -1 && file.length() == per_page) { System.out.println("文件存在了咯,不处理了"); return null; } // 需要知道 开始-结束 = 分片大小 CloseableHttpClient client = HttpClients.createDefault(); // httpclient进行请求 HttpGet httpGet = new HttpGet("http://127.0.0.1:8080//download2/singlePartFileDownload?fileName=" + fName); // 告诉服务端做分片下载,并且告诉服务器下载到那个位置 httpGet.setHeader("Range", "bytes=" + start + "-" + end); CloseableHttpResponse response = client.execute(httpGet); String fSize = response.getFirstHeader("fSize").getValue(); fName = URLDecoder.decode(response.getFirstHeader("fName").getValue(), "utf-8"); HttpEntity entity = response.getEntity();// 获取文件流对象 InputStream is = entity.getContent(); //临时存储分片文件 FileOutputStream fos = new FileOutputStream(file); // 定义缓冲区 byte[] buffer = new byte[1024]; int readLength; //写文件 while ((readLength = is.read(buffer)) != -1) { fos.write(buffer, 0, readLength); } is.close(); fos.flush(); fos.close(); //判断是不是最后一个分片,如果不是最后一个分片不执行 if (end - Long.parseLong(fSize) > 0) { try { System.out.println("开始合并了"); this.mergeAllPartFile(fName, page); System.out.println("文件合并结束了"); } catch (Exception e) { e.printStackTrace(); } } return new FileInfo(Long.parseLong(fSize), fName); }
(4)开启多线程下载分片
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
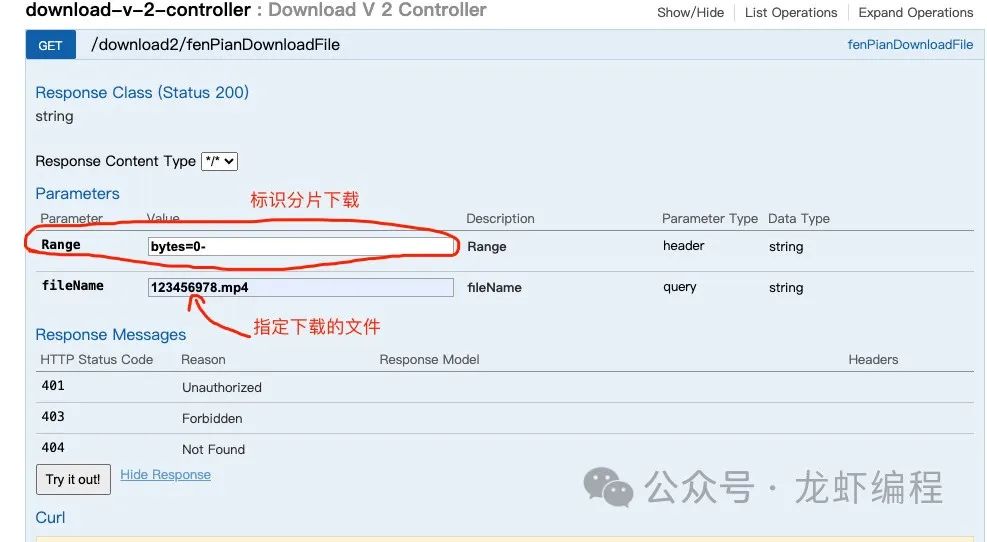
@GetMapping("/fenPianDownloadFile")public String fenPianDownloadFile(@RequestParam("fileName")String fileName) throws Exception { //探测文件信息 FileInfo fileInfo = download(0, 10, -1, fileName); if (fileInfo != null) { long pages = fileInfo.fSize / per_page; System.out.println("文件分页个数:" + pages + ", 文件大小:" + fileInfo.getFSize()); for (int i = 0; i <= pages; i++) { pool.submit(new Download(i * per_page, (i + 1) * per_page - 1, i, fileInfo.fName)); } } return "success"; }
#异步线程下载分片数据class Download implements Runnable { //开始下载位置 long start; //结束下载的位置 long end; //当前的分片 long page; //文件名称 String fName;
public Download(long start, long end, long page, String fName) { this.start = start; this.end = end; this.page = page; this.fName = fName; }
@Override public void run() { try { //下载单个分片 download(start, end, page, fName); } catch (Exception e) { e.printStackTrace(); } } }
(5)合并文件 * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
/** * 合并文件 * * @param fName 文件名称 * @param page 分片的文件的页 * */ private void mergeAllPartFile(String fName, long page) throws Exception { // 归并文件位置 File file = new File(down_path, fName); BufferedOutputStream os = new BufferedOutputStream(new FileOutputStream(file)); for (int i = 0; i <= page; i++) { File tempFile = new File(down_path, i + "-" + fName); // 分片没下载或者没下载完需要等待 while (!file.exists() || (i != page && tempFile.length() < per_page)) { Thread.sleep(1000); System.out.println("结束睡觉,再次查询文件等候已经下载完成了"); } byte[] bytes = FileUtils.readFileToByteArray(tempFile); os.write(bytes); os.flush(); tempFile.delete(); } //删除探测文件 File file1 = new File(down_path, -1 + "-" + fName); file1.delete(); os.flush(); os.close(); }
启动Swagger测试:
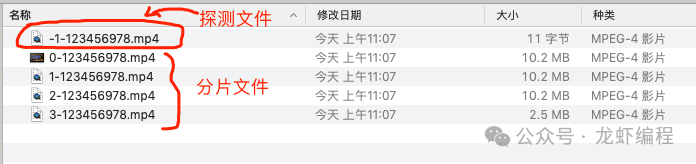
所有分片都下载好之后的效果:
合并完整文件并删除分片之后的效果:

以上我们完成了分片下载的功能。
4、断点下载实现
断点下载就是在分片下载的基础上实现的,下载时候我们判断当前的分片是否是完整的下载(根据文件的大小为依据),最后一个分片根据文件大小我们不知道是否全部下载完成,所有最后一个分片直接去服务器上下载。
下面模拟一下断点下载的场景,分片下载之后,在合并的时候抛出异常,如下图所示:
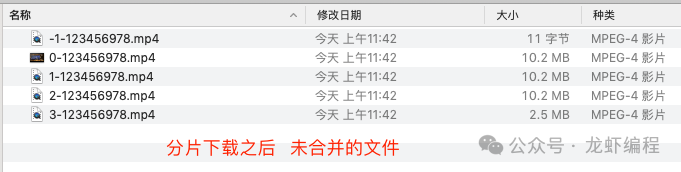
下载好分片之后,在执行合并文件的时候抛出异常,如下如图所示:
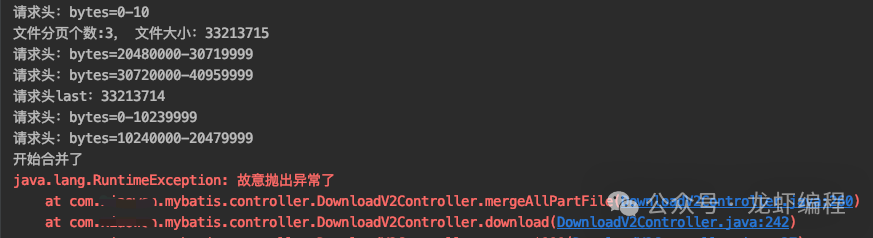
重新执行分片下载,下载过程如下所示:
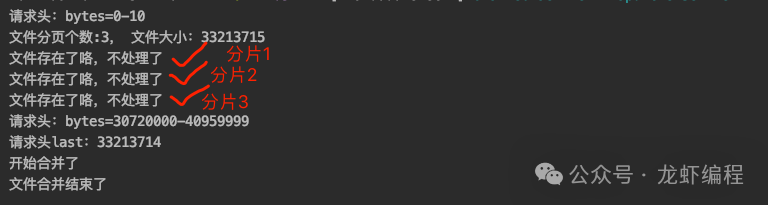
最后的结果:

这样就可以实现断点下载的效果了。至此我们完成从Minio上分片下载和端点下载文件的的功能。
总结:
(1)分片下载使用的是Range首部方式实现文件下载指定部分,等所有分片都下载结束后,再将整个文件都合并成完成文件,最后删除分片文件的数据。
(2)断点下载是在分片下载的基础上实现的,如果分片已经下载好了就不需要再次下载。